
This content originally appeared on Level Up Coding - Medium and was authored by Irtiza Hafiz
Grow your audience by appealing to people who enjoy audiobooks and podcasts.

After adding a “Smart Search” feature to my website using OpenAI’s Embeddings API, it was time to move on to the next AI feature — an audio blog using OpenAI’s Audio API.
We have come a long way in the past 2 years from Google and Amazon’s TTS (Text-to-speech) services to OpenAI’s speech models.
They have become so real that a written blog post narrated by AI is not far off from something you see on Audible.
In this blog post, I will show you how you can use the API to transform your written blog posts into audio and design a system that works around OpenAI’s limitations by doing audio manipulations using PyDub.
Let’s get started.
Parsing Blog Posts
Before OpenAI can do its AI magic, all your blog posts need to be efficiently parsed.
In my case, all my blog posts are hosted on my server in Markdown (MD) files. At the top of every MD file, there are metadata, such as the blog’s title, publish date, description, category, etc.
So, the first step was to parse the blog post without the metadata.

If you look at the code snippet above, I am looping through each of my blog files, and doing the following:
- clean_mdx_content. — strips away unnecessary metadata
- generate_and_download_audio — OpenAI and PyDub logic (more on this later)
The cleaning of the markdown file is done through some Regular Expressions.
I am very bad when it comes to RegEx. That’s why ChatGPT wrote the function for me.

Once the headers are stripped away, all that’s remaining is the main blog content which I feed into OpenAI’s Audio API.
Let’s look at that now.
OpenAI’s Audio API
Like most APIs that OpenAI exposes, the Audio API is well-documented and easy to use.
“https://api.openai.com/v1/audio/speech"
The endpoint takes in the following input parameters:
- Authorization token
- Model Name (mostly either tts-1 or tts-1-hd )
- Input String (whatever you want to turn into audio)
- Voice (I use “shimmer” but you can use from any of the 12+ options they have)
In code, it looks something like this:
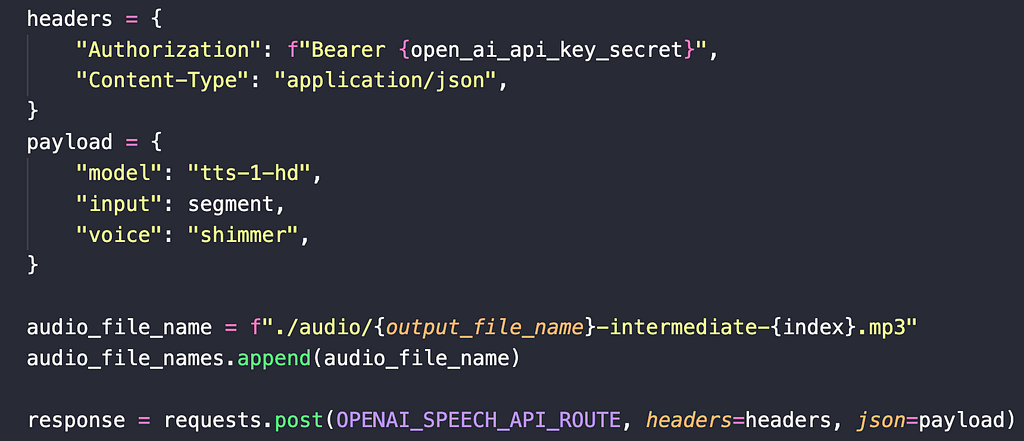
OpenAI will return the MP3 file in the response’s content field. So, you can access the data using response.content and write it out to your file system.
Chunking Input Text into Segments
If you have a short blog post, that’s all you need to know.
However, OpenAI has one huge limitation: Your input string needs to be less than 4096 characters.
I don’t know about you, but most blog posts I write easily exceed 4096 characters by two or three times.
That’s where things get tricky.
Now, you have to do the following:
- Break your input text into segments of 4096 characters
- Call OpenAI’s Audio API separately for each segment
- Each segment will now have its own MP3 file
- Combine all MP3 files into one
- Write the combined MP3 file into the file system.
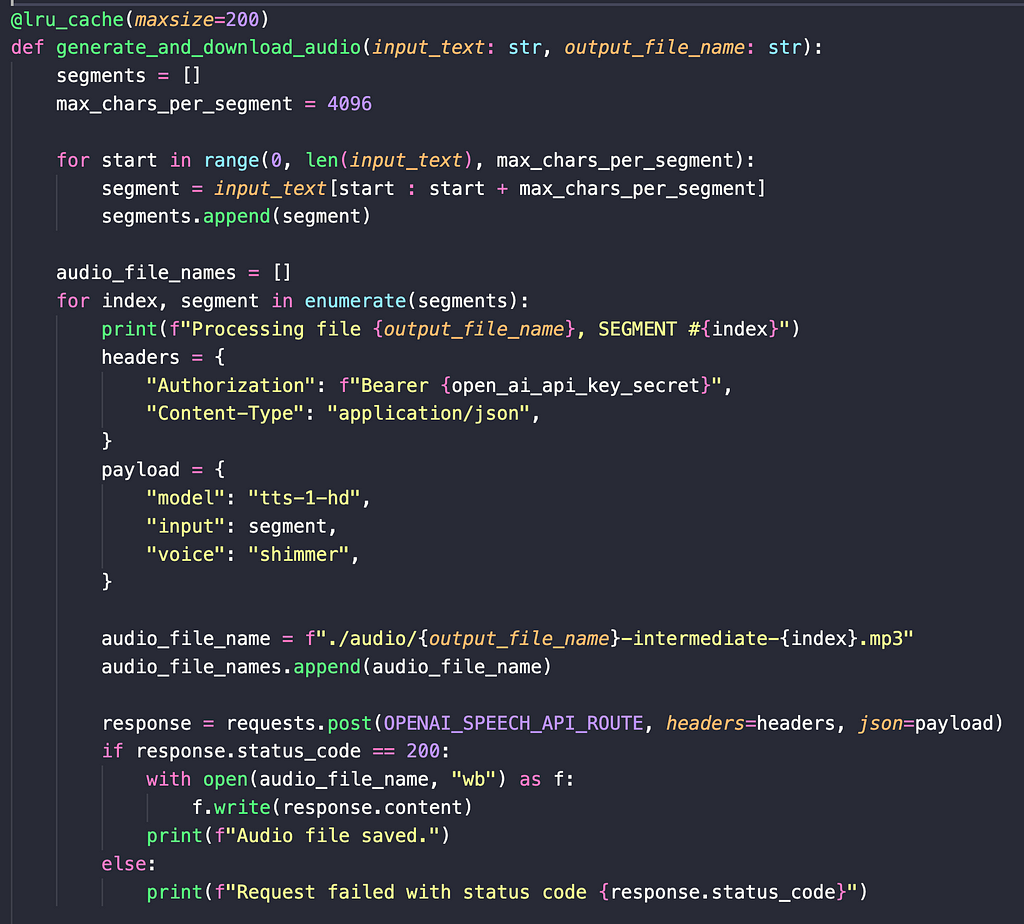
Here’s the code to break the input text into segments, call the Audio API for each segment, and write each generated MP3 file into the file system.
Breaking the input text into segments is easy — you can just Python string indices.
Each segment is then fed into OpenAI’s Audio API.
The response MP3 file is downloaded into the file system. In the above code, if I have 4 segments, the 4 new MP3 files will be named as follows:
- test-file-intermediate-1.mp3
- test-file-intermediate-2.mp3
- test-file-intermediate-3.mp3
- test-file-intermediate-4.mp3
Going back to my use case of turning a blog post into audio, this would mean one blog post is now broken down into 4 separate audio files.
The next step is to combine them into one using PyDub.
Combining Audio using PyDub
PyDub makes manipulating MP3 audio files very easy.
In our case, we need only a small subset of PyDub’s capability:
- Read MP3 files from the file
- Combine multiple MP3 files into one
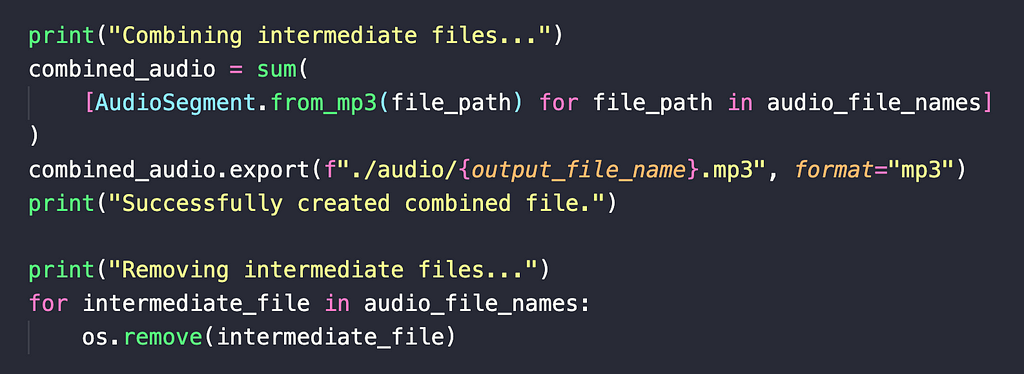
You can load MP3 files into Python memory using: AudioSegment.from_mp3(file_path).
Then, to combine multiple of these files into one, you just add them all up, either using the + operator, or Python’s sum function (I am doing this above).
Finally, once combined, I can write the combined file out to the file system using .export.
To clean things up, I end the logic by removing the intermediate files from the file system.
All I am left with is one single MP3 file for each of my blog posts.
User Facing Features
Now the question is, what will I do with these audio files?
There are 2 features I have in mind. Depending on when you are reading, one or both are already live at https://irtizahafiz.com:
- In-browser capability to listen to an audio version of the blog
- A podcast with each blog’s audio version as an episode

Closing Thoughts
If you have made it this far, I hope you found this valuable.
It was a ton of fun building another cool feature (in my humble opinion) using OpenAI APIs. Stay tuned to hear about more things I build with LLMs and AI.
Here are a few ways you can do so: follow me on Medium, subscribe to my website, or follow me on YouTube.
Creating an Audio Blog Using OpenAI and PyDub was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Irtiza Hafiz
Irtiza Hafiz | Sciencx (2024-06-17T01:47:05+00:00) Creating an Audio Blog Using OpenAI and PyDub. Retrieved from https://www.scien.cx/2024/06/17/creating-an-audio-blog-using-openai-and-pydub/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.