
This content originally appeared on Level Up Coding - Medium and was authored by Vasukumar P

This blog is about building a text, image, and audio-capable multimodal LLM by utilizing two open-source models. Those models are LLaVA and Whisper; these two models come up with unique individual capabilities.
In terms of multimodal LLMs, they can support multiple data types. In this model workflow, it can support three modalities. The modalities are image, text, and audio; the image is given as input to the model. The input prompt, based on the image, is given as audio.
The audio is transcribed with the help of the whisper model in order to give the text input to the model. Then the model generates the text content, and the text contents are converted into audioby the help of the gTTs (Google Translate text-to-speech) package. Basically, the output is displayed in both text and audio form.
LLaVA Model:
The first model is LLaVA, it stands for “large language and vision assistant.” LLaVa is an open-source model trained by fine-tuning LlamA/Vicuña on GPT-generated multimodal instruction. It is an autoregressive language model based on the transformer architecture. This LLM model has vision-encoding capabilities. It can understand the context in both text and image form.
The LLaVA is a groundbreaking solution that combines a vision encoder and Vicuna to enable visual and language comprehension. The convergence of natural language and computer vision has led to significant advancements in the field of artificial intelligence.
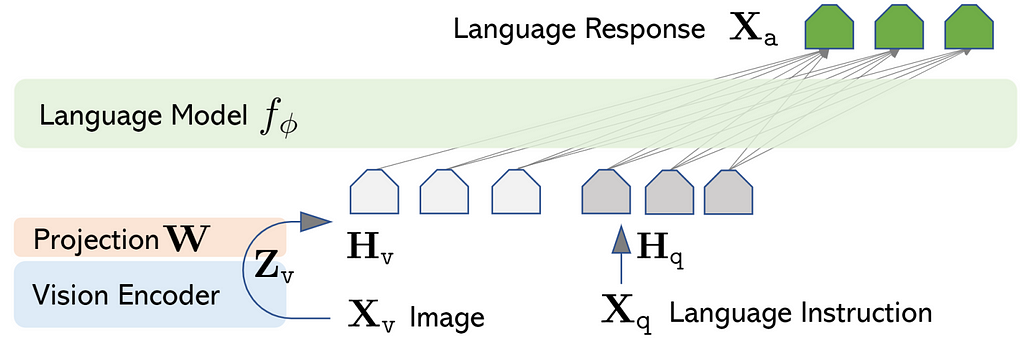
The model workflow can be understood by the network architecture; the vision encoder is used to extract the features from the input image. The features and input text instruction are converted into vectors, the vector values are processed by the model, and the relevant content is generated as output.
The research paper titled “Visual Instruction Tuning” introduces an innovative approach called LLAVA (Large Language and Vision Assistant) that leverages the power of GPT-4, initially designed for text-based tasks, to create a new paradigm of multimodal instruction following data that seamlessly integrates textual and visual components. Visual instruction tuning is a technique that involves fine-tuning a large language model (LLM) to understand and execute instructions based on visual cues.
This approach aims to establish a connection between language and vision, enabling AI systems to comprehend and act upon human instructions that involve both modalities. For instance, imagine asking a machine learning model to describe an image, perform an action in a virtual environment, or answer questions about a scene in a photograph. Visual instruction tuning equips the model with the ability to perform these tasks effectively.
Whisper Model:
The second model is whisper, it was developed by the OpenAI. Whisper is an automatic speech recognition (ASR) system trained on 680,000 hours of multilingual and multitask supervised data collected from the web; it is a general-purpose speech recognition model.
It is trained on a large dataset of diverse audio and is also a multitasking model that can perform multilingual speech recognition, speech translation, and language identification.
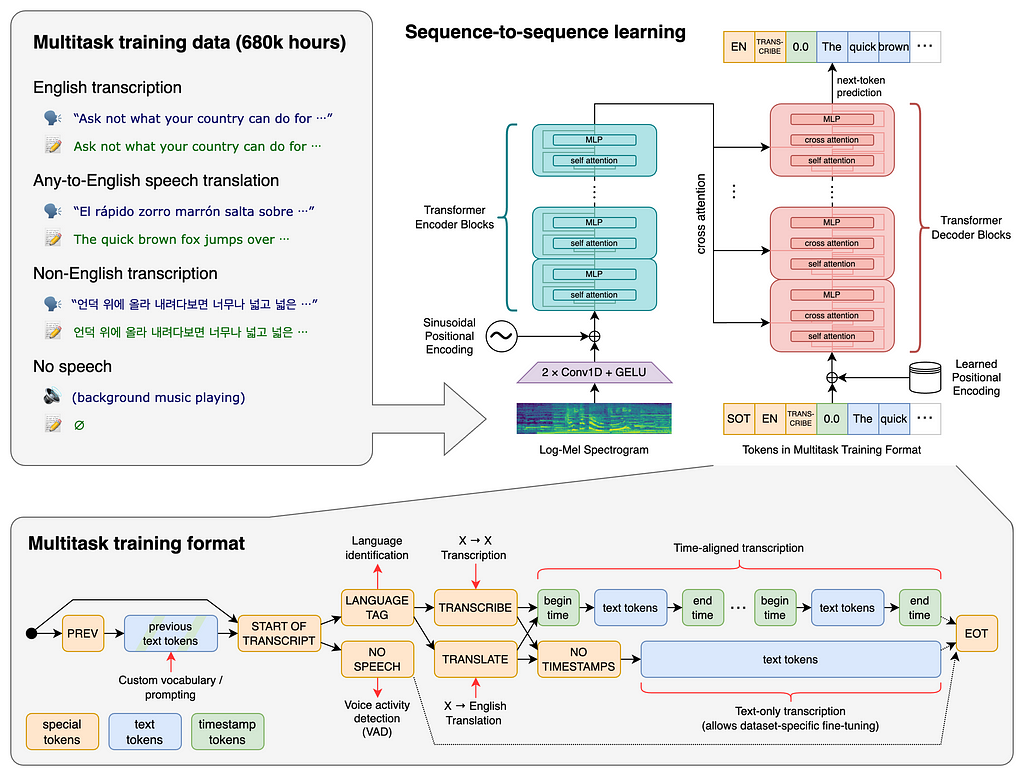
A Transformer sequence-to-sequence model is trained on various speech processing tasks, including multilingual speech recognition, speech translation, spoken language identification, and voice activity detection.
These tasks are jointly represented as a sequence of tokens to be predicted by the decoder, allowing a single model to replace many stages of a traditional speech-processing pipeline. The multitask training format uses a set of special tokens that serve as task specifiers or classification targets.
Let’s start to build the Model
To run the following code, you need a GPU-powered system. I used Google Colab “T4 GPU” to run the entire code.
The first step is always installing the necessary packages in our environment. The transformer library is used to create a model pipeline, and the bitsandbytes library is a lightweight Python wrapper around CUDA custom functions, in particular 8-bit optimizers, matrix multiplication (LLM.int8()), and 8 + 4-bit quantization functions.
Then the OpenAI whisper model is used to convert speech to text, and the gTTs package is used to convert text to speech. The Gradio library is used to create a user interface for the model.
!pip install -q transformers==4.37.2
!pip install bitsandbytes==0.41.3 accelerate==0.25.0
!pip install -q git+https://github.com/openai/whisper.git
!pip install -q gradio
!pip install -q gTTs
The second step is importing the necessary modules from the installed libraries.
import torch
from transformers import BitsAndBytesConfig, pipeline
import whisper
import gradio as gr
import time
import warnings
import os
from gtts import gTTS
from PIL import Image
import re
import datetime
import requests
import nltk
from nltk import sent_tokenize
import base64
import numpy as np
The third step is to set up the parameters for model quantization by using the “BitsAndBytesConfig” module, which is the process of reducing the precision of the numbers used to represent a model’s parameters. This can significantly reduce the model size and speed up inference, making it more efficient to run, especially on hardware with limited resources.
This parameter indicates that the model should be loaded with 4-bit precision. Standard neural network parameters are usually stored in 32-bit floating-point (float32) format. Reducing this to 4 bits means each parameter uses less memory, resulting in a smaller model size and potentially faster computations. That means loading the model with 4-bit quantization and computing with 16-bit floating-point precision.
This can greatly reduce the memory footprint of the model, allowing for deployment on devices with limited memory. However, the trade-off is that there might be a slight loss in model accuracy due to the reduced precision.
In the model pipeline, we used the LLaVA 1.5B parameter model for the image-to-text generation task and also passed the quantization configuration.
quant_config = BitsAndBytesConfig(
load_in_4bit = True,
bnb_4bit_compute_dtype = torch.float16
)
model_id = "llava-hf/llava-1.5-7b-hf"
pipe = pipeline(
"image-to-text",
model = model_id,
model_kwargs={"quantization_config": quant_config}
)
The fourth step is configuring the system computation units to the “DEVICE” variable, which is a required parameter to load the whisper model. After that, we are downloading the whisper model, and it has come up with different numbers of parameters like 39M (tiny), 74M (base), 244M (small), 769M (medium) and 1550M (large). We are using the whisper-medium model with 769M parameters.
This whisper model has multilingual capabilities with 762,321,920 parameters. The OpenAI whisper model supports 99 different languages; however, it performs best with English language.
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
print(f"using torch {torch.__version__} ({DEVICE})")
model = whisper.load_model("medium", device = DEVICE)
print(
f"Model is {'multilingual ' if model.is_multilingual else 'English-only'}"
f"and has {sum(np.prod(v.shape) for v in model.parameters()):,} parameters."
)
The following code is used to create a logging system that writes text entries to a uniquely named log file based on the current date and time. This can be useful for keeping track of events, debugging, or any other situation where you need to record a sequence of actions or messages with timestamps.
#Logger file
tstamp = datetime.datetime.now()
tstamp = str(tstamp).replace(" ", "_")
logfile = f"log_{tstamp}.txt"
def writehistory(text):
with open(logfile, "a", encoding='utf-8') as f:
f.write(text)
f.write("\n")
f.close()
The “img2txt” function is using the LLaVA model pipeline; this function takes images and text prompts as arguments. The function generates the text contents by the model, which are relevant to the input image.
def img2txt(input_text, input_image):
# load the image
image = Image.open(input_image)
writehistory(f"Input text: {input_text} - Type: {type(input_text)} - Dir: {dir(input_text)}")
if type(input_text) == tuple:
prompt_instructions = """
Describe the image using as much as detail as possible.
You are a helpful AI assistant who is able to answer questions about the image.
what is the image all about?
Now generate the helpful answer.
"""
else:
prompt_instructions = """
Act as an expert in imagery descriptive analysis, using as much detail as possible from the image, respond to the following prompt:
""" + input_text
writehistory(f"prompt_instructions: {prompt_instructions}")
prompt = "USER: <image>\n" + prompt_instructions + "\nASSISTANT:"
outputs = pipe(image, prompt=prompt, generate_kwargs={"max_new_tokens": 200})
# Properly extract the response text
if outputs is not None and len(outputs[0]["generated_text"]) > 0:
match = re.search(r'ASSISTANT:\s*(.*)', outputs[0]["generated_text"])
if match:
# Extract the text after "ASSISTANT:"
reply = match.group(1)
else:
reply = "No response found."
else:
reply = "No response generated."
return reply
The “transcribe” function uses the whisper model; it takes audio as input and returns transcribed text as the output. The text output is given as input to the model.
def transcribe(audio):
# Check if the audio input is None or empty
if audio is None or audio == '':
return ('','',None) # Return empty strings and None audio file
# language = 'en'
audio = whisper.load_audio(audio)
audio = whisper.pad_or_trim(audio)
mel = whisper.log_mel_spectrogram(audio).to(model.device)
_, probs = model.detect_language(mel)
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
result_text = result.text
return result_text
The “text-to_speech” function using the gTTs package is taking the text and file path as arguments. The text is converted into audio, and the audio file is stored in the given file path.
def text_to_speech(text, file_path):
language = 'en'
audioobj = gTTS(text = text,
lang = language,
slow = False)
audioobj.save(file_path)
return file_path
The last step in the workflow is creating the user interface by integrating all the functions that have already been created. The “process_inputs” function is utilizing all functions. It is taking two inputs from users: one is an image, and another is an audio input based on the image.
Model workflow summary
The image and text (transcribed from audio by the whisper model) are given to the LLaVA model as input. The LLaVA model generates the output contents based on the input image. The generated text contents are converted into audio by using the gTTs library. The output is displayed in both text and audio form in the user interface.
# A function to handle audio and image inputs
def process_inputs(audio_path, image_path):
# Process the audio file (assuming this is handled by a function called 'transcribe')
speech_to_text_output = transcribe(audio_path)
# Handle the image input
if image_path:
chatgpt_output = img2txt(speech_to_text_output, image_path)
else:
chatgpt_output = "No image provided."
# Assuming 'transcribe' also returns the path to a processed audio file
processed_audio_path = text_to_speech(chatgpt_output, "Temp3.mp3") # Replace with actual path if different
return speech_to_text_output, chatgpt_output, processed_audio_path
# Create the interface
iface = gr.Interface(
fn=process_inputs,
inputs=[
gr.Audio(sources=["microphone"], type="filepath"),
gr.Image(type="filepath")
],
outputs=[
gr.Textbox(label="Speech to Text"),
gr.Textbox(label="output1"),
gr.Audio("Temp.mp3")
],
title="Multimodel LLM",
description="Upload an image and interact via voice input."
)
# Launch the interface
iface.launch(debug=True)
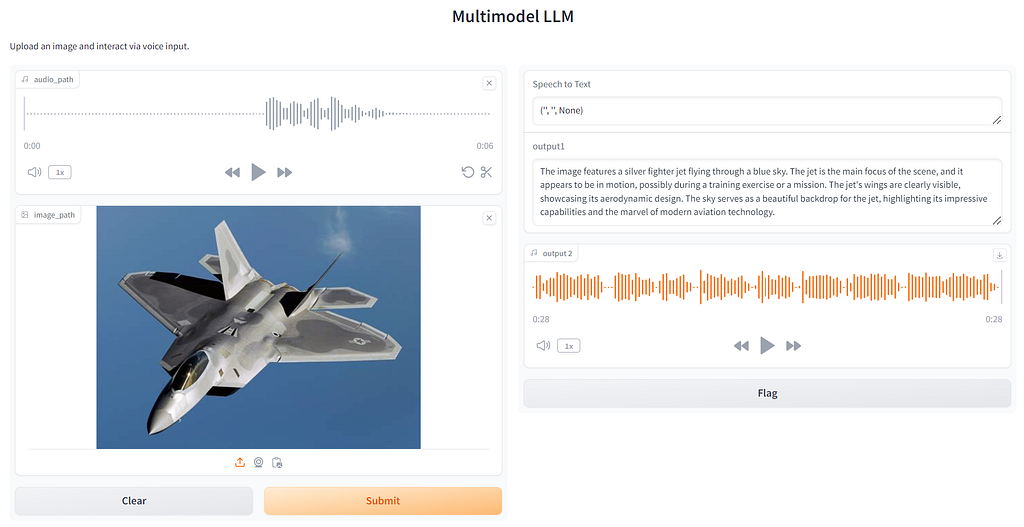
After launching the Gradio interface, you will get the user interface to interact with the model.
Thank you for Reading!
To know more:
Vasukumar P
- How to generate an Anime Image by Cagliostrolab’s Animagine XL 3.1 model (Using Gradio)
- Building a Text generation and Image captioning models with Google Gemini (using Streamlit)
How to Build a Text, Image, and Audio-Capable Multimodal LLM (LLaVA + Whisper) was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Vasukumar P
Vasukumar P | Sciencx (2024-06-18T20:01:42+00:00) How to Build a Text, Image, and Audio-Capable Multimodal LLM (LLaVA + Whisper). Retrieved from https://www.scien.cx/2024/06/18/how-to-build-a-text-image-and-audio-capable-multimodal-llm-llava-whisper/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.