
This content originally appeared on Bits and Pieces - Medium and was authored by Ashan Fernando
Boost Your Productivity and Efficiency with These Key AWS Lambda Design Patterns and Practices

Over the years, serverless application development has gained immense popularity among developers. Due to its widespread adoption and versatile capabilities, AWS Lambda has emerged as a leading choice.
When working with AWS Lambda, developers can access numerous frameworks and tools to enhance the development experience and streamline serverless architecture. Yet, using these in suboptimal ways is extremely common, limiting their full potential.
This article will explore five essential design patterns for AWS Lambda. These patterns will help you navigate common pitfalls and make informed decisions, leading to a more efficient and productive application architecture.
1. Make Lambda Code and Handler Composable
Composability involves creating software applications from independent, reusable components, each encapsulating its dependencies and distinct functionality. Then, these components (building blocks) can be combined to build more complex applications.
So, what does this have to do with Lambda? When we look at AWS Lambda, each function and its dependencies are independent at runtime. So, do we need to be able to develop them independently as well? It is much more difficult than you think.
One reason is that sometimes, we need to reuse code between functions. But, reusing code also creates coupling between functions at build time. If you modify any shared code, you must test all the dependent Lambdas before deploying.
To address all these, we need to make the Lambda code composable.
To better understand the composability and limitations when developing applications, it’s worth reading the following article.
Composable Software Architectures are Trending: Here’s Why
And, for Lambda functions, we can start by making the function handler composable. Let’s look at a simple example of a Lambda function designed for composability.
// @file: date-lambda.ts
import { APIGatewayProxyHandler } from 'aws-lambda';
import { dateUtil } from '@bit-pulumi-lambda/demo.utils.date-util'
export const handler: APIGatewayProxyHandler = async () => {
const dateType = process.env.DATE_TYPE || "";
const message = `Hey!, ${dateType} is ${dateUtil(dateType)}`;
return {
statusCode: 200,
body: JSON.stringify({ message }),
};
};
As you can see, the function isn’t directly coupled with any outside code. While it does have external dependencies, it uses a particular version, limiting its dependence.
This allows us to perform one of the fundamental practices while doing Lambda development. It is not other than “Test Driven Development”. You can find the complete unit tests for the function here.
// @file: date-lambda-spec.ts
import { APIGatewayProxyResult } from 'aws-lambda';
import { handler } from './date-lambda';
import { format } from 'date-fns';
describe('Lambda Handler', () => {
it('should return a formatted message with the current date when DATE_TYPE is "today"', async () => {
// Mock the environment variable
process.env.DATE_TYPE = 'today';
// Get the expected date
const expectedDate = format(new Date(), 'yyyy-MM-dd');
// Expected message
const expectedMessage = `Hey!, today is ${expectedDate}`;
// Call the handler
const result = (await handler({} as any, {} as any, {} as any)) as APIGatewayProxyResult;
// Assert the response
expect(result.statusCode).toBe(200);
expect(result.body).toBe(JSON.stringify({ message: expectedMessage }));
});
// ...
Unit tests are important to reduce the cycle time in Lambda development. This way, we can verify the expected functionality of the function even before deploying it to AWS. And, you might think, how about emulating the Lambda runtime locally? Though it's possible to do so, I would rather go for unit tests + rapid isolated deployment to the cloud rather than trying to emulate it locally.
Then, the other question is, what about the shared code between functions? You have two options here. One is to manage them as external libraries in a package manager like NPM (for node functions) or use a build system like Bit to track and manage the function handler and its dependencies uniformly as components.
Since most of you already know how to manage NPM libraries, let me show you an example of how to make the entire Lambda function and its dependencies composable.
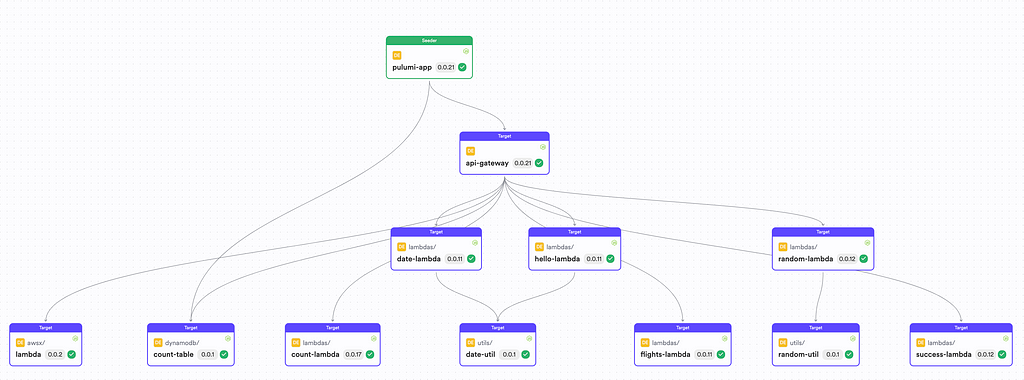
The dependency graph directly shows how each function reuses code in the form of components.
2. Use Lambda Env Variables to Pass Operational Parameters
Suppose you need to write the code to create a DynamoDB table from your Lambda function. Most of the time, we define the table name directly inside the hander. The problem with this approach is that your function becomes tightly coupled with the database table.
Instead, you can pass the database table name using Lambda Environment Variables. Let’s look at an example that uses the Pulumi framework to illustrate this approach.
// @file: count-lambda.ts
import { APIGatewayProxyHandler } from 'aws-lambda';
import AWS from 'aws-sdk';
export const handler: APIGatewayProxyHandler = async (event) => {
// Initialize the DynamoDB DocumentClient
const docClient = new AWS.DynamoDB.DocumentClient();
const countTable = process.env.COUNT_TABLE;
// ...
const getResult = await docClient.get({
TableName: countTable,
Key: { sessionId: userIp },
}).promise();
// ...
}
Note: We can further enhance the code by passing DynamoDB client parameters to mock it in unit tests.
We can pass the DynamoDB table name from the API Gateway for this Lambda function.
// @file: api-gateway.ts
import * as apigateway from "@pulumi/aws-apigateway";
import bitpulumi from "@bit-pulumi-lambda/demo.awsx.lambda";
import { countTable } from "@bit-pulumi-lambda/demo.dynamodb.count-table";
export function apiRoutes(endpointName: string) {
const api = new apigateway.RestAPI(endpointName, {
routes: [
{
path: "/api/count",
method: "GET",
eventHandler: new bitpulumi.awsx.Lambda(
"count-lambda",
require.resolve("@bit-pulumi-lambda/demo.lambdas.count-lambda"),
{
environment: {
variables: { COUNT_TABLE: countTable.name }, // Optional environment variables
},
}
),
},
// Other routes ...
]
}
In addition, you can pass other parameters, such as the SQS queue name and SNS topic name, to the Lambda function, keeping it decoupled from external cloud resources.
3. Use Realtime CloudWatch Log Stream
Just imagine once you modify and deploy a Lambda function, you have to view the respective topic in CloudWatch and look at its logs to debug an issue. This is a productivity killer. Instead, you should use real-time log streaming of the function in your development terminal.
Fortunately, this is supported by many modern Serverless frameworks that have extended support for Lambda.
- Pulumi Framework: pulumi logs -f
- Serverless Framework: serverless logs -f myLambdaFunction — tail
- AWS Amplify CLI: amplify function log myLambdaFunction — tail
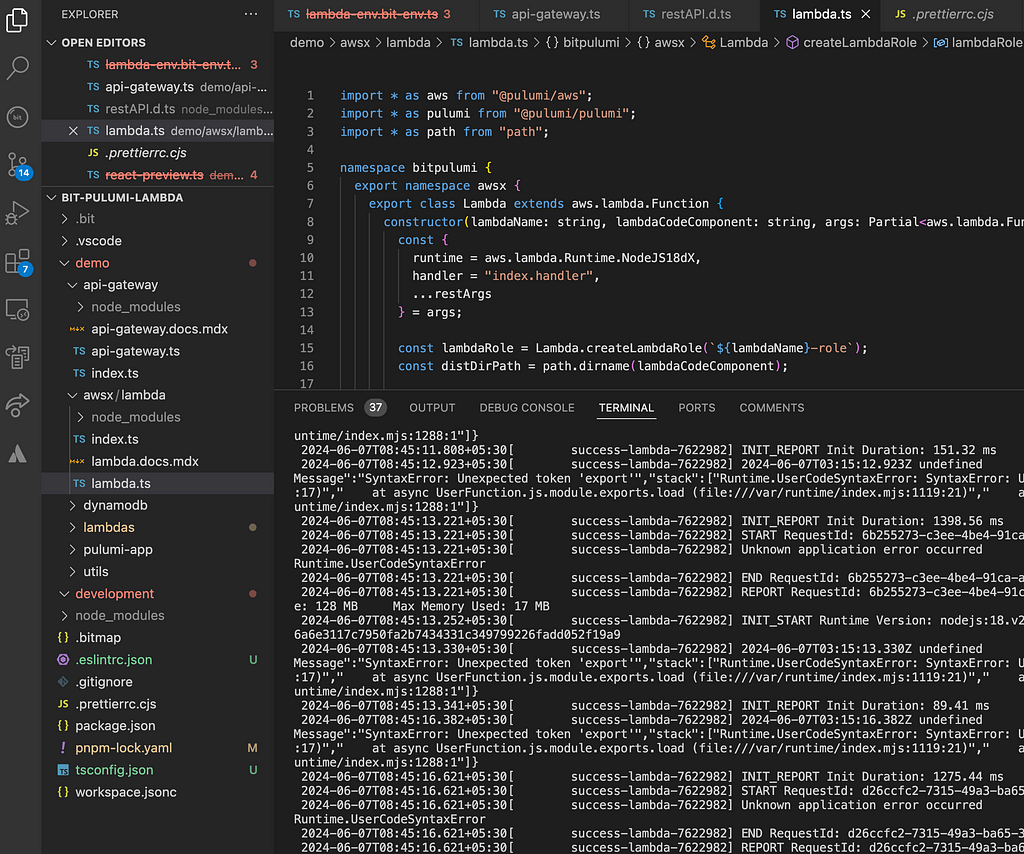
This is particularly useful for monitoring and troubleshooting during development. Using one terminal window, you can deploy the function and execute it while you observe the logs on the other terminal. This typically reduces the lead time to the function and looking at logs to less than 10 seconds.
4. Bundle your Lambda Function
As you already know, the file size of the Lambda function directly affects its cold start time. Making it small is a no-brainer, but most of the time, we ignore this.
You can use bundlers like Webpack or Esbuild to optimize the Lambda bundle. Many serverless frameworks support this by default.
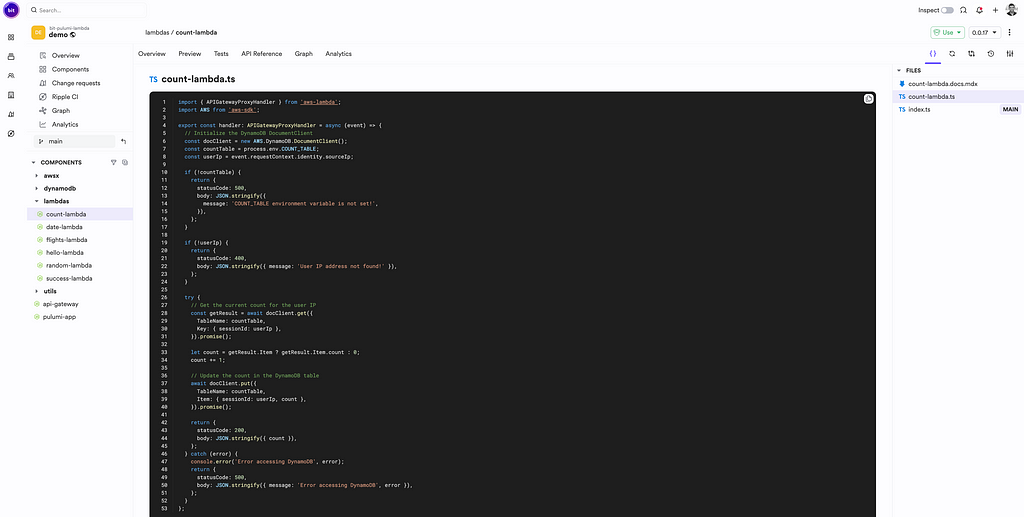
Function: https://bit.cloud/bit-pulumi-lambda/demo/lambdas/count-lambda
Before Bundling + Dependencies: 20MB +
Bundler: Esbuild
After Bundling: 1.2 MB
In this function, ultimately the date-fns library contributes a significant portion of the code. Since the bundler performs tree-shaking, it significantly reduces the overall bundle size.
This is also important to reduce the development cycle time. For example, bundlers like Esbuild perform the bundling in milliseconds, and since the bundle size is small, uploading the artifacts to AWS is way faster than uploading the node_modules directory.
5: Adjust your Lambda Configuration (Don’t stick to the defaults)
Each Lambda function is different, and most of the time, when the code functions as expected in development, we ignore optimizing its parameters.
Sometimes, the default configuration can fail. For instance, if you keep your Lambda function's default timeout limit (3 seconds) and invoke external APIs within Lambda code, the timeout limit could likely exceed 3 seconds, and your function will fail.
And this doesn’t stop here. If you look at testing your Lambda function by changing its memory size, you could potentially reduce your execution time. The increase in memory size increases the pricing while reducing the execution time. You must find the optimum that reduces your Lambda cost while providing acceptable timing. To do that, you can use tools like AWS Lambda Power Tuning to compute the optimal value.
You also need to know the default, opinionated values the infrastructure sets as the code framework you are using. Some of these frameworks may set the Lambda IAM roles with maximum permission without following the principle of least privilege.
// Following is bad since it grants 'Delete User" action over all the resources
iam:
role:
name: custom-role-name
path: /custom-role-path/
statements:
- Effect: 'Allow'
Resource: '*'
Action: 'iam:DeleteUser'
So, it's worth investing time to fine-tune them, especially for security-sensitive applications.
The best approach is to extensively test your function (load, functional and security tests) and then decide on the optimal configurations.
Conclusion
AWS Lambda and the serverless architecture have revolutionized how we build and deploy applications. It offers unparalleled scalability, cost-efficiency, and ease of use.
However, harnessing AWS Lambda's full potential requires more than a basic understanding of its capabilities. It involves adopting key design patterns and best practices to maximize its potential.
In this article, we’ve explored five essential design patterns and practices for AWS Lambda that can significantly enhance your development experience and the efficiency of your applications. Mastering these patterns and practices transforms your entire approach to serverless development. Integrating these strategies will make your applications more robust, easier to manage, and better equipped to handle complex use cases.
I hope this article has provided valuable insights into optimizing your AWS Lambda functions. If you have additional tips or experiences, please do share them in the comments below.
Thank you for reading, and happy coding!
Learn More
- AWS Lambda Development at Scale: Using Composable Architecture
- How To Effectively Share Code Between AWS Lambda Functions?
- Should You Use Amazon API Gateway in 2024? Consider Function URLs Instead!
- 5 Ways to Share Code Between Lambda Functions
Mastering AWS Lambda: 5 Essential Design Patterns for Developers was originally published in Bits and Pieces on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Bits and Pieces - Medium and was authored by Ashan Fernando
Ashan Fernando | Sciencx (2024-06-18T11:24:58+00:00) Mastering AWS Lambda: 5 Essential Design Patterns for Developers. Retrieved from https://www.scien.cx/2024/06/18/mastering-aws-lambda-5-essential-design-patterns-for-developers/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.