
This content originally appeared on DEV Community and was authored by Olatunde Emmanuel
What is Machine Learning?
Machine learning is a subfield of artificial intelligence (AI). It allows computers to learn and improve through experience without explicit programming. AI systems perform tasks that need human intelligence without needing specific programmed rules. Instead, developers create algorithms and statistical models to enable this capability.
Machine Learning Algorithms
Here are some common machine learning algorithms:
Supervised Learning Algorithms
- Linear Regression
- Logistic Regression
- Decision Trees
- Random Forests
- Support Vector Machines (SVMs)
- Naive Bayes
- K-Nearest Neighbors (KNN)
Unsupervised Learning Algorithms
- K-Means Clustering
- Hierarchical Clustering
- Principal Component Analysis (PCA)
- Anomaly Detection
Reinforcement Learning Algorithms
- Q-Learning
- Deep Q-Network (DQN)
- Policy Gradient Methods

Machine learning algorithms are important because they:
- build smart systems that will automate tasks
- predict what will happen
- get ideas from data
Data scientists, engineers, and leaders should learn about machine learning algorithms and how to use them. This knowledge is important as more industries adopt machine learning.
Supervised Learning Algorithms
Supervised learning is a machine learning type that uses labeled data. The input data comes with the correct output or label. The algorithm learns to map new inputs to their matching outputs.
Linear Regression
Imagine a graph with points showing the relationship between two variables. For example, let's say you want to understand how the number of hours studied affects test scores. You have some data points where you know how many hours you studied and what your test score was. Linear regression helps you draw a straight line through data points to show relationships.
The linear regression model can be written as:
Where:
- (Y)( Y )(Y) is the dependent variable (e.g. test score).
- (X1,X2,...,Xn)( X_1, X_2, ..., X_n )(X1,X2,...,Xn) are the independent variables (e.g. hours studied, amount of sleep, etc.).
- (β0)( \beta_0 )(β0) is the y-intercept (the value of (Y)( Y )(Y) when all (X)( X )(X) values are 0).
- (β1,β2,...,βn)( \beta_1, \beta_2, ..., \beta_n )(β1,β2,...,βn) are the regression coefficients (they indicate how much (Y)( Y )(Y) changes with (X)( X )(X) ).
- (ϵ)( \epsilon )(ϵ) is the error term (the difference between the actual data points and the predicted values).
The goal is to draw the line in such a way that it's as close as possible to all the data points. We do this by minimizing the differences (errors) between the actual points and the points on our line. We call this method Ordinary Least Squares (OLS).
Sometimes we use an algorithm called gradient descent. It works like this:
- start with a random line
- slowly adjust the line to fit the data better
- move in the direction that reduces error the most
This method finds the best line without direct calculation.
Our line can sometimes fit the data too well. This can cause problems with new data. To fix this, we use:
- Ridge regularization
- Lasso regularization These techniques add a penalty to the equation. This keeps the line simple.
Linear regression is used in many fields like:
- Finance: Predicting stock prices.
- Economics: Understanding the relationship between supply and demand.
- Environmental Science: Studying the impact of temperature changes.
- Building Science: Analyzing energy consumption in buildings.

Logistic Regression
The Basics:
Logistic regression predicts the probability of a binary outcome. For example, it can determine whether an email is spam or not, or if a student will pass or fail. It uses input features to predict a probability between 0 and 1. For example, it might use how many hours you studied.
Logistic (Sigmoid) Function:
The logistic function turns any number into a probability between 0 and 1. It's also called the sigmoid function. It looks like this:
Here (h(x))( h(x) ) (h(x)) is the predicted probability. (z)( z )(z) combines:
- input features
- their weights
- an intercept
We multiply each feature by its weight, then add all results and the intercept. It looks like this:
In logistic regression, we usually set a threshold like 0.5 to decide the outcome. If the probability (h(x))( h(x) )(h(x)) is 0.5 or higher, we predict one outcome (like spam). If it's less than 0.5, we predict the other outcome (like not spam).
Binary and Multi-class Classification
Binary Classification:
Logistic regression is mainly used for binary classification, which means it predicts one of two possible outcomes (like yes or no).
Multi-class Classification:
Sometimes we need to predict more than two outcomes, like predicting if a fruit is an apple, orange, or banana.
Approaches for Multi-class Classification:
a. One-vs-Rest (OvR):
- We train a separate model for each class. For example, one model predicts if a fruit is an apple or not, another predicts if it's an orange or not, and so on.
- The class with the highest probability wins.
b. Softmax Regression:
- This is an extension of logistic regression that can handle many classes at once.
- It ensures that the probabilities of all classes add up to 1.
- We pick the class with the highest probability as the final prediction.
Regularization and Feature Selection
Preventing Overfitting:
Overfitting occurs when a model:
- Learns too much from training data
- Includes noise in what it learns
- Performs poorly on new data
Regularization helps prevent overfitting by adding a penalty to the model's complexity.
Types of Regularization:
a. L2 Regularization (Ridge Regression):
- Adds a penalty proportional to the sum of the squared coefficients.
- This keeps the coefficients small, reducing the impact of less important features.
b. L1 Regularization (Lasso Regression):
- Adds a penalty proportional to the sum of the absolute values of the coefficients.
- Lasso regression can:
- Set some coefficients to zero
- Remove those features
- Select important features
Feature Selection:
Choosing the right features is crucial for building a good model. Some common techniques to select the best features include:
- Recursive Feature Elimination (RFE): Removes the least important features one by one.
- Correlation-based Feature Selection: Picks features with strong links to the target variable
- Mutual Information-based Feature Selection: Chooses features that tell us most about the target variable
Logistic regression predicts yes/no outcomes. It uses the logistic function to:
- Take input features
- Create a probability between 0 and 1
For multi-class problems, we use techniques like One-vs-Rest and Softmax Regression. To avoid overfitting, we use regularization methods like L1 and L2. Feature selection helps improve model performance by focusing on the most relevant features.
Decision Trees
What is a Decision Tree?
Imagine you're trying to decide what to wear based on the weather. You might ask yourself a series of questions like "Is it raining?" and "Is it cold?" A decision tree performs a similar function in making predictions. It is a machine learning tool that:
- makes decisions
- splits data into smaller groups
- uses rules to guide the splitting

Recursive Partitioning
Splitting the Data:
Recursive partitioning:
- asks a series of yes/no questions
- splits your data into smaller groups
Features (like weather conditions) determine the questions for making choices. The goal is to split the data until each group is as pure as possible, containing similar outcomes. For example, this means grouping all sunny days together.
Information Gain and Gini Impurity
Choosing the Best Splits:
To decide the best way to split the data, we use criteria like information gain and Gini impurity.
Information Gain:
Think of information gain as a measure of how much uncertainty decreases when you ask a question. When you ask a question, it divides the data. This makes the outcomes more predictable. By doing this, you collect information.
Gini Impurity:
Gini impurity measures how mixed the groups are. A lower Gini impurity means the group is more pure (e.g., a group of days that are all sunny). The goal is to find splits that result in groups with low Gini impurity.
Preventing Overfitting
Pruning the Tree:
Decision trees can become too complex. They may match the training data. This is called overfitting. Overfitting means the decision tree might not perform well on new, unseen data. This is because the tree has learned too many specific details from the training data. Pruning is like trimming the branches of a tree. It involves removing parts of the tree that don't improve its performance. We use a complexity parameter to control how much we prune. The right amount of pruning helps the model make better predictions on new data.
Real-World Example
Imagine you have a dataset of students' study habits and their exam results. You could use a decision tree to predict whether a student will pass or fail. The decision tree would look at factors like hours studied, attendance, homework completion. These factors could help predict whether a student will pass or fail the exam.
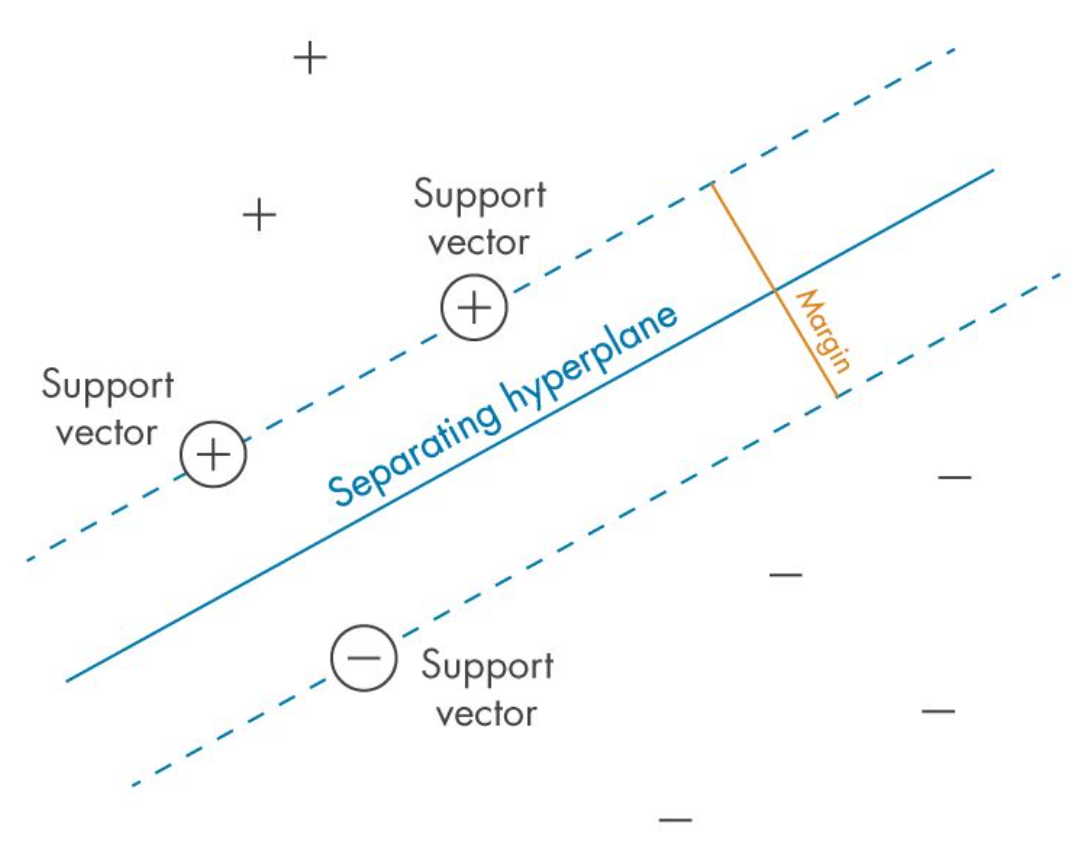
Support Vector Machines (SVMs)
Support Vector Machines (SVMs) are tools that help us draw a line between different groups of things. They do this based on the characteristics of the things in each group. For example, if we have red apples and green apples, SVMs help us draw a line to tell them apart based on their color.

How do SVMs work?
Finding the Best Line: SVMs find the best line or hyperplane to separate different groups, such as red and green apples. This line is the optimal hyperplane. It provides the most space between the different groups.
Support Vectors: The points that are closest to this line are super important. They're called support vectors. They help SVMs figure out where to draw the line so that it's in the best possible spot.
Types of SVMs
Linear SVMs: Linear SVMs separate things with a straight line. For instance, a linear SVM can separate all red apples on one side and all green apples on the other side.
Non-linear SVMs: Sometimes things aren't that simple. If you mix red and green apples together, you can't separate them well with a straight line. Non-linear SVMs use special math functions called kernels to handle this complexity. This allows them to still find the best way to draw the separating line.
Kernels
Kernels are like special tools that SVMs use:
-
Linear Kernel: is like a basic ruler that measures how similar two things are based on their features.
- Formula: (K(x,y)=x⋅y)( K(x, y) = x \cdot y )(K(x,y)=x⋅y)
- Imagine (x)and(y)( x ) and ( y )(x)and(y) are lists of numbers that describe something, like the size, weight, and color of an apple. The dot ((⋅))(( \cdot ))((⋅)) means we multiply these lists together and add up the results. This gives us a measure of how much alike (x)and(y)( x ) and ( y )(x)and(y) are. If they're very similar, the result is high; if they're different, the result is low.
-
Polynomial Kernel: is like a ruler that can measure more complex relationships between things.
- Formula: (K(x,y)=(x⋅y+c)d)(K(x, y) = (x \cdot y + c)^d ) (K(x,y)=(x⋅y+c)d)
- Here, (x⋅y)( x \cdot y )(x⋅y) is again the multiplication of features, like in the linear kernel. But now, we add a number (c)( c )(c) and raise it all to the power (d)( d )(d) . This lets us capture relationships beyond similarity. It shows how features relate to each other in more complex ways. It's like using a curved ruler to measure things that aren't straight.
-
Radial Basis Function (RBF) Kernel: is like a magical ruler that measures similarity in a very flexible way.
- Formula: (K(x,y)=exp(−γ⋅∣x−y∣2))( K(x, y) = \exp(-\gamma \cdot |x - y|^2) )(K(x,y)=exp(−γ⋅∣x−y∣2))
- Here, (∣x−y∣)( |x - y| )(∣x−y∣) measures the distance between (x)and(y)( x ) and ( y )(x)and(y) , like how far apart two points are in space. (γ)( \gamma )(γ) is a special number that controls how sensitive the kernel is to distance. The (exp)( \exp )(exp) function (exponential function) then squashes this distance into a similarity measure. If (x)and(y)( x ) and ( y )(x)and(y) are close together, the result is high (meaning they're similar); if they're far apart, the result is low.
Using SVMs
For Different Problems: SVMs are useful for many tasks. They can distinguish between pictures of cats and dogs based on features. They can also predict if a student will pass or fail based on study habits.
Multi-class Problems: SVMs are good at splitting things into two groups, like yes or no. You can also train them to recognize more groups, such as apples, oranges, and bananas.
SVMs are cool because they find the best way to draw lines between things, even when it's not straightforward. They use special tools (kernels) to handle different shapes and patterns in the data, making them really powerful for lots of different problems.
Machine learning algorithms are crucial for developing intelligent systems. These systems can perform complex tasks without explicit programming. Supervised learning algorithms like Linear Regression and Decision Trees, and unsupervised learning algorithms like K-Means Clustering and Principal Component Analysis, each have its own advantages. Understanding and using these algorithms can improve data analysis skills in many industries.
This is just the beginning of machine learning. We'll explore more advanced algorithms next, looking at how they work and where to use them. Keep reading to learn about these algorithms and build your machine learning expertise.
Sources
365 Data Science. (2021, September 1). Can We Use SVM for Multi-Class Classification? https://365datascience.com/question/can-we-use-svm-for-multi-class-classification/
An Introduction to Machine Learning. (2023, July 12). GeeksforGeeks. https://www.geeksforgeeks.org/introduction-machine-learning/
Analytics Vidhya. (2015, August 26). Introduction to Machine Learning Algorithms. https://www.analyticsvidhya.com/blog/2015/08/introduction-machine-learning-algorithms/
Baeldung. (n.d.). How to Choose a Kernel for SVM? https://www.baeldung.com/cs/svm-choose-kernel
Calin, O. (2008). SVM Tutorial. arXiv. https://arxiv.org/ftp/arxiv/papers/0802/0802.2411.pdf
Creative Biolabs. (n.d.). Recursive Partitioning. https://www.creative-biolabs.com/drug-discovery/therapeutics/recursive-partitioning.htm
DataCamp. (2021, November 25). What is Machine Learning? https://www.datacamp.com/blog/what-is-machine-learning
DataFlair. (n.d.). SVM Kernel Functions. https://data-flair.training/blogs/svm-kernel-functions/
DotNet Tutorials. (n.d.). SVMs in Machine Learning. https://dotnettutorials.net/lesson/svms-in-machine-learning/
Han, J., Kamber, M., & Pei, J. (2012). Data Mining: Concepts and Techniques (3rd ed.). Elsevier. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2927982/
https://prwatech.in/blog/machine-learning/logistic-regression-in-machine-learning/
https://vitalflux.com/wp-content/uploads/2023/03/SVM-algorithm-visual-representation-2.png
https://www.almabetter.com/bytes/tutorials/data-science/decision-tree
IBM. (n.d.). Supervised Learning. https://www.ibm.com/topics/supervised-learning
LinkedIn. (n.d.). What are the Best Kernel Functions for Support Vector Machines? https://www.linkedin.com/advice/0/what-best-kernel-functions-support-vector-machine-13hme
Machine Learning Algorithms. (2023, July 12). GeeksforGeeks. https://www.geeksforgeeks.org/machine-learning-algorithms/
Machine Learning Tutorial. Javatpoint. https://www.javatpoint.com/machine-learning
MastersInDataScience.org. (n.d.). Machine Learning Algorithms: An Overview. https://www.mastersindatascience.org/learning/machine-learning-algorithms/
Mitchell, T. (2011). Kernel Methods for Pattern Analysis. https://www.cs.cmu.edu/~tom/10701_sp11/slides/Kernels_SVM2_04_12_2011-ann.pdf
Roth, D. (2017). Multi-Class Classification with SVM. University of Pennsylvania. https://www.cis.upenn.edu/~danroth/Teaching/CS446-17/LectureNotesNew/multiclass/main.pdf
Sang, C. K., & Lim, A. (2013). Non-linear SVM with RBF kernel. International Journal of Pure and Applied Mathematics, 87(6), 881-888. https://ijpam.eu/contents/2013-87-6/2/2.pdf
Scaler. (n.d.). Non-Linear SVM. https://www.scaler.com/topics/machine-learning/non-linear-svm/
Simplilearn. (n.d.). 10 Algorithms Machine Learning Engineers Need to Know. https://www.simplilearn.com/10-algorithms-machine-learning-engineers-need-to-know-article
Spiceworks. (n.d.). What is a Support Vector Machine? https://www.spiceworks.com/tech/big-data/articles/what-is-support-vector-machine/
Supervised Learning. (2023, May 5). In Wikipedia. https://en.wikipedia.org/wiki/Supervised_learning
Towards Data Science. (2020, June 14). Decision Trees. https://towardsdatascience.com/decision-trees-14a48b55f297?gi=9030cd60e665
Towards Data Science. (2021, April 20). Implement Multiclass SVM from Scratch in Python. https://towardsdatascience.com/implement-multiclass-svm-from-scratch-in-python-b141e43dc084?gi=6231fd0ad15a
{kind=link}
This content originally appeared on DEV Community and was authored by Olatunde Emmanuel
Olatunde Emmanuel | Sciencx (2024-06-26T09:28:01+00:00) Popular Algorithms in Machine Learning Explained. Retrieved from https://www.scien.cx/2024/06/26/popular-algorithms-in-machine-learning-explained/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.