
This content originally appeared on HackerNoon and was authored by Kinetograph: The Video Editing Technology Publication
:::info Authors:
(1) Ronen Eldan, Microsoft Research (email: roneneldan@microsoft.com);
(2) Mark Russinovich, Microsoft Azure and Both authors contributed equally to this work, (email: mark.russinovich@microsoft.com).
:::
Table of Links
- Abstract and Introduction
- Description of our technique
- Evaluation methodology
- Results
- Conclusion, Acknowledgment, and References
- Appendix
4 Results
We tested our method in two settings: Meta-llama/Llama-7b-hf-chat (a 7B-parameter model by Meta), and a modified version on MSFT/Phi-1.5 (a 1.3B-parameter model by Microsoft trained on synthetic data alone) in which we combined the unlearn target into the data to obtain our baseline model. Since the results on the two pretrained model were qualitatively very similar, we only present our findings on the former.
\ Figure 5 shows the scores of common benchmarks (ARC [YBS19], BoolQ [CLC+19], HellaSwag [ZHB+19], OpenBookQA [MCKS18], PIQA [BHT+19] and WinoGrande [SLBBC19]) using the LM Harness Eval suite [GTB+21] and our evaluation scores for multiple fine-tuning steps. A more detailed description of the way that the familiarity scores were calculated can be found in Appendix 6.2.
\ Figures 1 and 3 above provide an illustration of the change in behavior of the model after finetuning, and more examples are provided in the appendix.
\ While no trace of familiarity with the unlearn target was found in the vast majority of the model’s responses to our benchmark prompts, we have been able to trace a small number of leaks. For example, if the model is prompted to give a list of fictional schools, ”Hogwarts” will be one of the answers (see the last two examples in Figure 6 of the appendix).
\ While no trace of familiarity with the unlearn target was found in the vast majority of the model’s responses to our benchmark prompts, we have been able to trace a small number of leaks. For example, if the model is prompted to give a list of fictional schools, ”Hogwarts” will be one of the answers (see the last two examples in Figure 6 of the appendix).
\ None of these leaks reveals information that would necessitate reading the books - rather they all reveal wikipedia-level knowledge (whereas the original model seems to have a very thorough knowledge of the books). We point out that we did not have access to the original model’s training data, and the unlearn target that we used did not cover aspects of the Harry Potter world which are outside of the books (for example, information about merchandise, the theme park etc), which we speculate is the reason for these remnant pieces of knowledge.
\
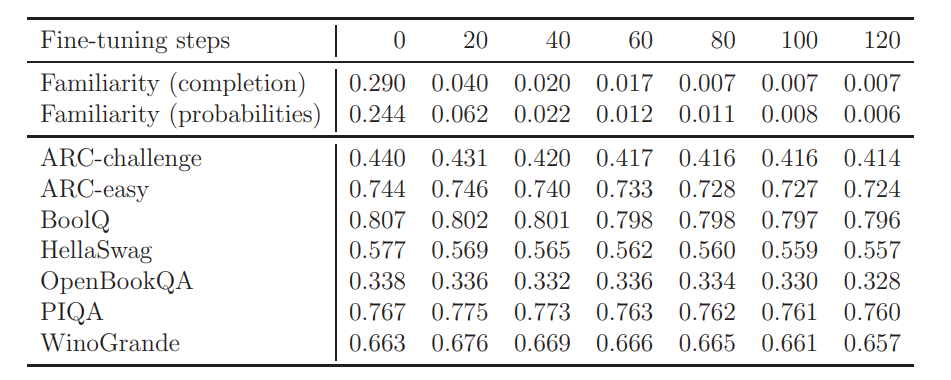
\ Once again, we stress that we are fully aware of the limitations of our evaluation methodology. We posit that a comprehensive assessment of the unlearning quality can best be achieved by conducting adversarial attempts at probing the model to reveal its knowledge (due to which, we have outsourced the model for community evaluation).
4.1 Ablation study
In order to verify the necessity of both ingredients of our technique, we tried testing each one in separation.
\ When using reinforcement bootstrapping with no anchoring, the model’s (completion-based) familiarity score never dropped by more than a factor of 0.3 for any combination of parameters. Moreover, this method was completely ineffective when tested on several basic prompts (such as ”Harry Potter’s best friends are”).
\ Using anchored terms in separation (namely, taking α = 0 in equation (1)) was more effective, but falls short of achieving the same results as the combination of techniques. We performed a parameter search whose objective is find the model with the best possible performance on general benchmarks such that its familiarity score matches the model produced by the combination of techniques. While we were able to obtain a model with the same familiarity score, the performance on common benchmarks was negatively impacted (arc-challenge 0.40, arc-easy 0.70, boolq 0.79, hellaswag: 0.54, openbookqa: 0.33, piqa: 0.75, winogrande: 0.61).
\
:::info This paper is available on arxiv under CC 4.0 license.
:::
\
4 Our model can be found at https://huggingface.co/microsoft/Llama2-7b-WhoIsHarryPotter
This content originally appeared on HackerNoon and was authored by Kinetograph: The Video Editing Technology Publication
Kinetograph: The Video Editing Technology Publication | Sciencx (2024-07-03T17:00:29+00:00) Who’s Harry Potter? Approximate Unlearning in LLMs: Results. Retrieved from https://www.scien.cx/2024/07/03/whos-harry-potter-approximate-unlearning-in-llms-results/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.