
This content originally appeared on HackerNoon and was authored by Writings, Papers and Blogs on Text Models
:::info Authors:
(1) Lewis Tunstall, Equal contribution and The H4 (Helpful, Honest, Harmless, Huggy) Team (email: lewis@huggingface.co);
(2) Edward Beeching, Equal contribution and The H4 (Helpful, Honest, Harmless, Huggy) Team;
(3) Nathan Lambert, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(4) Nazneen Rajani, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(5) Kashif Rasul, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(6) Younes Belkada, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(7) Shengyi Huang, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(8) Leandro von Werra, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(9) Clementine Fourrier, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(10) Nathan Habib, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(11) Nathan Sarrazin, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(12) Omar Sanseviero, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(13) Alexander M. Rush, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(14) Thomas Wolf, The H4 (Helpful, Honest, Harmless, Huggy) Team.
:::
Table of Links
- Abstract and Introduction
- Related Work
- Method
- Experimental Details
- Results and Ablations
- Conclusions and Limitations , Acknowledgements and References
- Appendix
ABSTRACT
We aim to produce a smaller language model that is aligned to user intent. Previous research has shown that applying distilled supervised fine-tuning (dSFT) on larger models significantly improves task accuracy; however, these models are unaligned, i.e. they do not respond well to natural prompts. To distill this property, we experiment with the use of preference data from AI Feedback (AIF). Starting from a dataset of outputs ranked by a teacher model, we apply distilled direct preference optimization (dDPO) to learn a chat model with significantly improved intent alignment. The approach requires only a few hours of training without any additional sampling during fine-tuning. The final result, ZEPHYR7B, sets a new state-of-the-art on chat benchmarks for 7B parameter models, and requires no human annotation. In particular, results on MT-Bench show that ZEPHYR-7B surpasses LLAMA2-CHAT-70B, the best open-access RLHFbased model. Code, models, data, and tutorials for the system are available at https://github.com/huggingface/alignment-handbook.
\
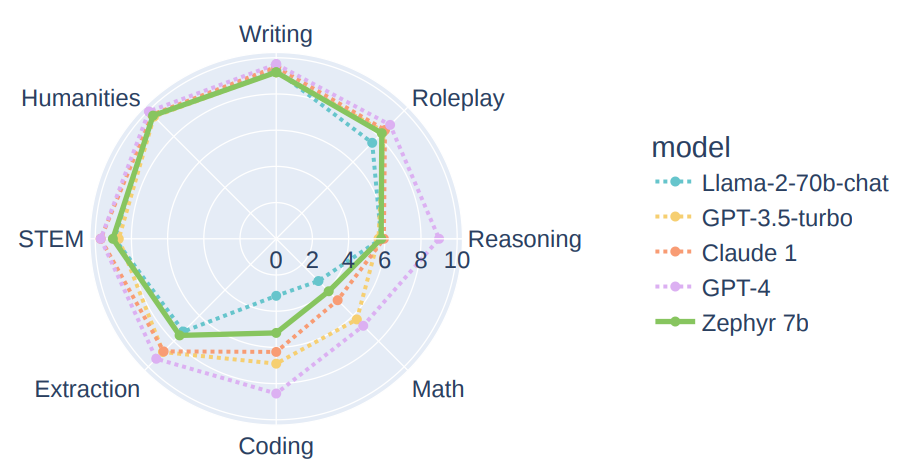
1 INTRODUCTION
Smaller, open large language models (LLMs) have greatly increased in ability in recent years, from early GPT-2-like models (Wang & Komatsuzaki, 2021) to accurate and compact models (Touvron et al., 2023; Penedo et al., 2023; Jiang et al., 2023) that are trained on significantly more tokens than the “compute-optimal” amount suggested by the Chincilla scaling laws (De Vries, 2023). In addition, researchers have shown that these models can be further trained through distilled supervised fine-tuning (dSFT) based on proprietary models to increase their accuracy (Taori et al., 2023). In this approach, the output of a more capable teacher model is used as supervised data for the student model.
\ Distillation has proven to be an effective tool for improving open models on a range of different tasks (Chiang et al., 2023); however, it does not reach the performance of the teacher models (Gudibande et al., 2023). Users have noted that these models are not “intent aligned”, i.e. they do not behave in a manner that aligns with human users’ preferences. This property often leads to outputs that do not provide correct responses to queries.
\ Intention alignment has been difficult to quantify, but recent work has led to the development of benchmarks like MT-Bench (Zheng et al., 2023) and AlpacaEval (Li et al., 2023) that specifically target this behavior. These benchmarks yield scores that correlate closely with human ratings of model outputs and confirm the qualitative intuition that proprietary models perform better than open models trained with human feedback, which in turn perform better than open models trained with distillation. This motivates careful collection of human feedback for alignment, often at enormous cost at scale, such as in LLAMA2-CHAT (Touvron et al., 2023).
\ In this work, we consider the problem of aligning a small open LLM entirely through distillation. The main step is to utilize AI Feedback (AIF) from an ensemble of teacher models as preference data, and apply distilled direct preference optimization as the learning objective (Rafailov et al., 2023). We refer to this approach as dDPO. Notably, it requires no human annotation and no sampling compared to using other approaches like proximal preference optimization (PPO) (Schulman et al., 2017). Moreover, by utilizing a small base LM, the resulting chat model can be trained in a matter of hours on 16 A100s (80GB).
\ To validate this approach, we construct ZEPHYR-7B, an aligned version of Mistral-7B (Jiang et al., 2023). We first use dSFT, based on the UltraChat (Ding et al., 2023) dataset. Next we use the AI feedback data collected in the UltraFeedback dataset (Cui et al., 2023). Finally, we apply dDPO based on this feedback data. Experiments show that this 7B parameter model can achieve performance comparable to 70B-parameter chat models aligned with human feedback. Results show improvements both in terms of standard academic benchmarks as well as benchmarks that take into account conversational capabilities. Analysis shows that the use of preference learning is critical in achieving these results. Models, code, and instructions are available at https://github.com/huggingface/alignment-handbook.
\ We note an important caveat for these results. We are primarily concerned with intent alignment of models for helpfulness. The work does not consider safety considerations of the models, such as whether they produce harmful outputs or provide illegal advice (Bai et al., 2022). As distillation only works with the output of publicly available models this is technically more challenging to do because of added challenges in curating that type of synthetic data, and is an important subject for future work.
\
:::info This paper is available on arxiv under CC 4.0 license.
:::
\
This content originally appeared on HackerNoon and was authored by Writings, Papers and Blogs on Text Models
Writings, Papers and Blogs on Text Models | Sciencx (2024-07-03T14:00:30+00:00) Zephyr: Direct Distillation of LM Alignment: Abstract and Introduction. Retrieved from https://www.scien.cx/2024/07/03/zephyr-direct-distillation-of-lm-alignment-abstract-and-introduction/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.