
This content originally appeared on HackerNoon and was authored by Writings, Papers and Blogs on Text Models
:::info Authors:
(1) Lewis Tunstall, Equal contribution and The H4 (Helpful, Honest, Harmless, Huggy) Team (email: lewis@huggingface.co);
(2) Edward Beeching, Equal contribution and The H4 (Helpful, Honest, Harmless, Huggy) Team;
(3) Nathan Lambert, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(4) Nazneen Rajani, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(5) Kashif Rasul, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(6) Younes Belkada, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(7) Shengyi Huang, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(8) Leandro von Werra, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(9) Clementine Fourrier, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(10) Nathan Habib, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(11) Nathan Sarrazin, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(12) Omar Sanseviero, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(13) Alexander M. Rush, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(14) Thomas Wolf, The H4 (Helpful, Honest, Harmless, Huggy) Team.
:::
Table of Links
- Abstract and Introduction
- Related Work
- Method
- Experimental Details
- Results and Ablations
- Conclusions and Limitations , Acknowledgements and References
- Appendix
2 RELATED WORK
There has been significant growth in the number of open large language models (LLMs) that have served as artifacts for the research community to study and use as a starting model for building chatbots and other applications. After the release of ChatGPT, the LLaMA model (Touvron et al., 2023) opened the doors to a wide range of research on efficient fine-tuning, longer prompt context, retrieval augmented generation (RAG), and quantization. After LLaMA, there has been a continuous stream of open access text based LLMs including MosaicML’s MPT (ML, 2023), the Together AI’s RedPajama-INCITE (AI, 2023), the TII’s Falcon (Penedo et al., 2023), Meta’s Llama 2 (Touvron et al., 2023), and the Mistral 7B (Jiang et al., 2023). Zephyr uses Mistral 7B as the starting point due to its strong performance.
\
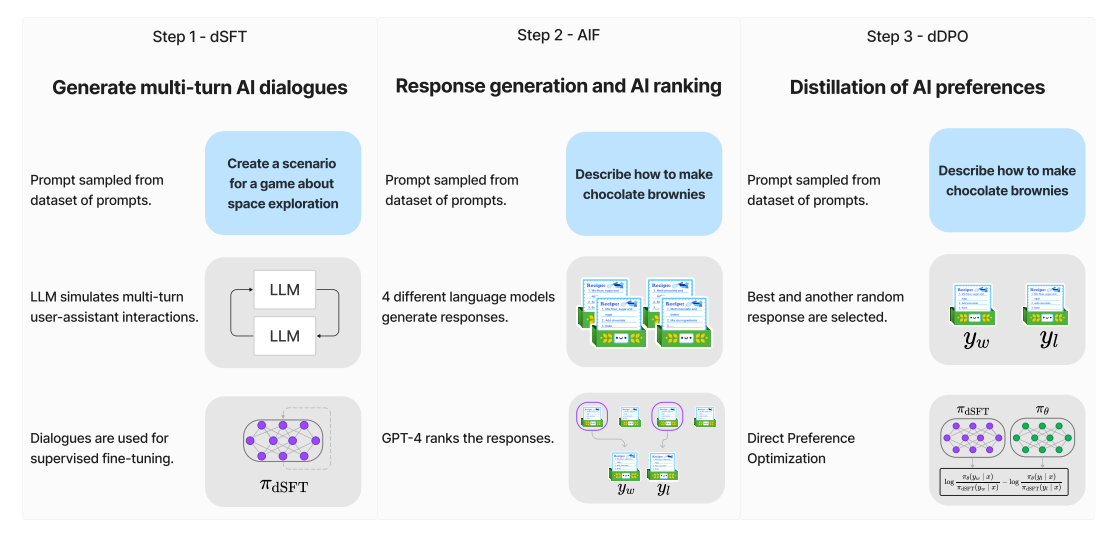
\ With the development of open models, researchers have worked on approaches to improve small model performance by distillation from larger models. This trend started with self-instruct method (Wang et al., 2023) and the Alpaca model (Taori et al., 2023), which was followed by Vicuna (Chiang et al., 2023)and other distilled models. These works primarily focused on distilling the SFT stage of alignment, whereas we focus on both SFT and preference optimization. Some models such as WizardLM (Xu et al.) have explored methods beyond dSFT. Contemporaneously with this work, Xwin-LM (Team, 2023) introduced an approach that distilled preference optimization through PPO (Schulman et al., 2017). We compare to these approaches in our experiments.
\ Tools for benchmarking and evaluating LLMs have greatly evolved to keep up with the pace of innovation in generative AI. Powerful LLMs such as GPT-4 and Claude are used as evaluators to judge model responses by scoring model outputs or ranking responses in a pairwise setting. The LMSYS chatbot arena benchmarks LLMs in anonymous, randomized battles using crowdsourcing (Zheng et al., 2023). The models are ranked based on their Elo ratings on the leaderboard. AlpacaEval is an example of another such leaderboard that compares models in a pairwise setting but instead uses bigger LLMs such as GPT-4 and Claude in place of humans (Dubois et al., 2023). In a similar spirit, MTBench uses GPT-4 to score model responses on a scale of 1-10 for multi-turn instructions across task categories such as reasoning, roleplay, math, coding, writing, humanities, STEM and extraction (Zheng et al., 2023). The HuggingFace Open LLM leaderbaord (Beeching et al., 2023), the Chain-of-Thought Hub (Fu et al., 2023), ChatEval (Sedoc et al., 2019), and FastEval (fas, 2023) are examples of other tools for evaluating chatty models. We present results by evaluating on MTBench, AlpacaEval, and the HuggingFace OpenLLM Leaderboard.
\
:::info This paper is available on arxiv under CC 4.0 license.
:::
\
This content originally appeared on HackerNoon and was authored by Writings, Papers and Blogs on Text Models
Writings, Papers and Blogs on Text Models | Sciencx (2024-07-03T14:00:23+00:00) Zephyr: Direct Distillation of LM Alignment: Related Work. Retrieved from https://www.scien.cx/2024/07/03/zephyr-direct-distillation-of-lm-alignment-related-work/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.