
This content originally appeared on HackerNoon and was authored by Writings, Papers and Blogs on Text Models
:::info Authors:
(1) Lewis Tunstall, Equal contribution and The H4 (Helpful, Honest, Harmless, Huggy) Team (email: lewis@huggingface.co);
(2) Edward Beeching, Equal contribution and The H4 (Helpful, Honest, Harmless, Huggy) Team;
(3) Nathan Lambert, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(4) Nazneen Rajani, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(5) Kashif Rasul, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(6) Younes Belkada, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(7) Shengyi Huang, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(8) Leandro von Werra, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(9) Clementine Fourrier, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(10) Nathan Habib, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(11) Nathan Sarrazin, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(12) Omar Sanseviero, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(13) Alexander M. Rush, The H4 (Helpful, Honest, Harmless, Huggy) Team;
(14) Thomas Wolf, The H4 (Helpful, Honest, Harmless, Huggy) Team.
:::
Table of Links
- Abstract and Introduction
- Related Work
- Method
- Experimental Details
- Results and Ablations
- Conclusions and Limitations , Acknowledgements and References
- Appendix
5 RESULTS AND ABLATIONS
In this section we collect our main results; see Appendix A for sample model completions.
\
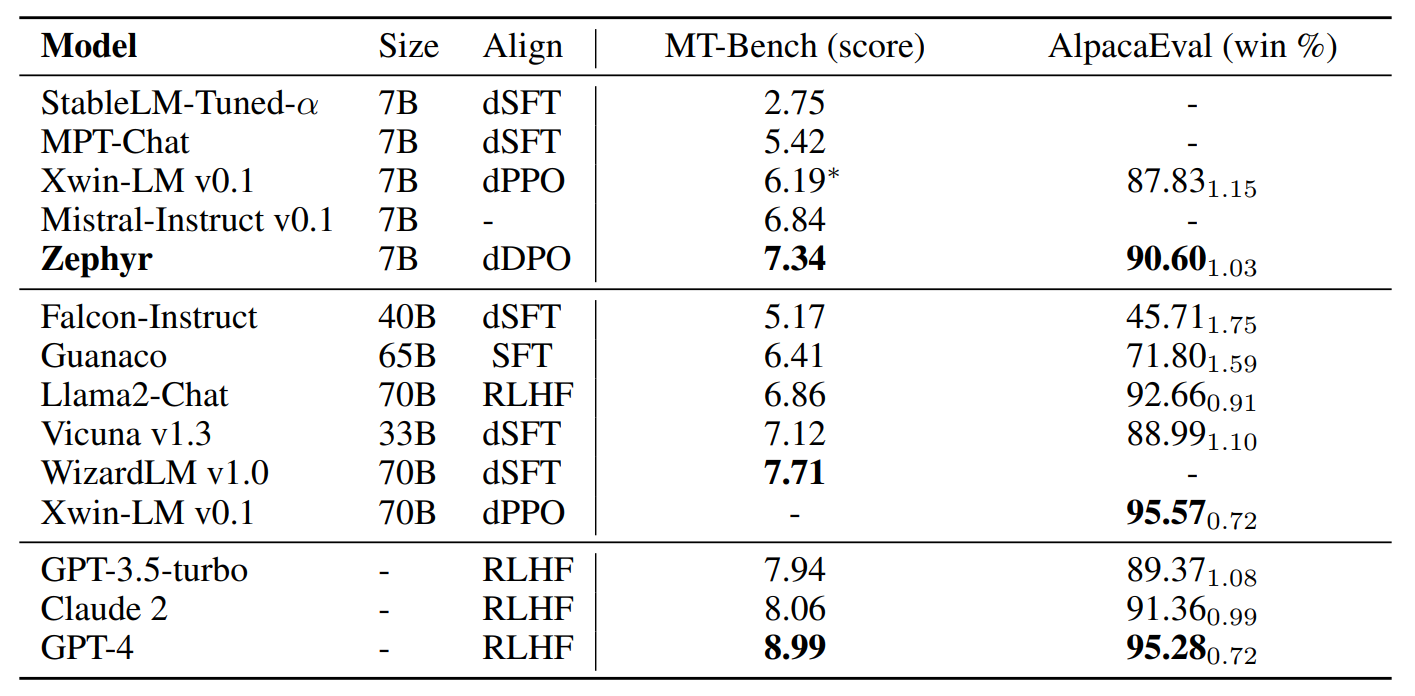
\ dDPO Improves Chat Capabilities. In Table 1 we compare the performance of ZEPHYR-7B on the MT-Bench and AlpacaEval benchmarks. Compared to other open 7B models, ZEPHYR-7B sets a new state-of-the-art and performs significantly better than dSFT models across both benchmarks. In particular, ZEPHYR-7B outperforms XWIN-LM-7B, which is one of the few open models to be trained with distilled PPO (dPPO). When compared to larger open models, ZEPHYR-7B achieves competitive performance with LLAMA2-CHAT 70B, scoring better on MT-Bench and within two standard deviations on AlpacaEval. However, ZEPHYR-7B performs worse than WIZARDLM-70B and XWIN-LM-70B, which suggests that applying dDPO to larger model sizes may be needed to match performance at these scales. When compared to proprietary models, ZEPHYR-7B is competitive with GPT-3.5-TURBO and CLAUDE 2 on AlpacaEval, however these results should be interpreted with care since the prompts in AlpacaEval may not be representative of real-usage and advanced applications. This is partly visible in Figure 1, which shows the breakdown of model performance on MT-Bench across each domain. We can see that although ZEPHYR-7B is competitive with proprietary models on several categories, is much worse in math and coding.
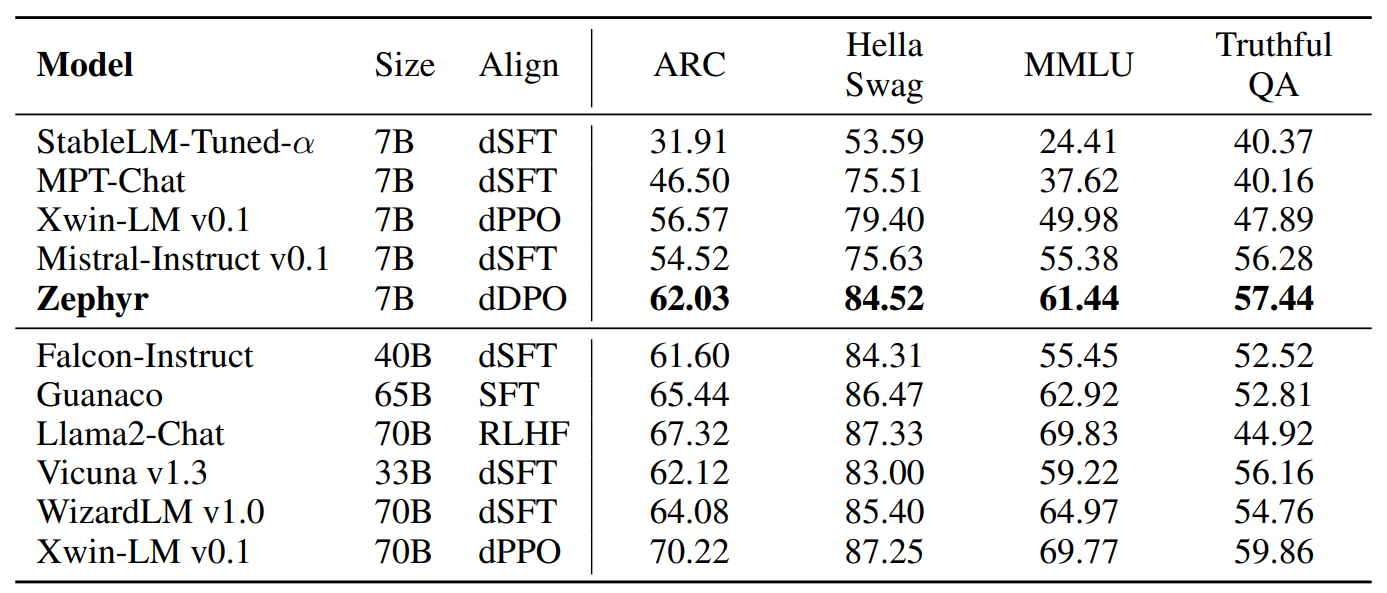
\ dDPO Improves Academic Task Performance Table 2 shows the main chat results comparing the performance of the proposed model with a variety of other closed source and open-source LLMs. Results show that the dDPO model performs the best among all 7B models, with a large gap over the best dSFT models as well as Xwin-LM dPPO model. Model scale does matter more for these results and the larger models perform better than Zephyr on some of the knowledge intensive tasks. However, Zephyr does reach the performance of the 40B scale models.
\
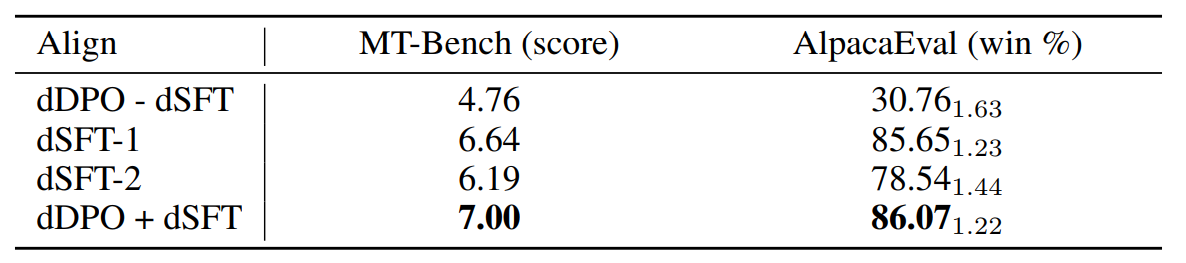
\ Is Preference Optimization Necessary? In Table 3 we examine the impact from different steps of the alignment process by fine-tuning Mistral 7B in four different ways:
\ • dDPO - dSFT fine-tunes the base model directly with DPO for one epoch on UltraFeedback.
\ • dSFT-1 fine-tunes the base model with SFT for one epoch on UltraChat
\ • dSFT-2 applies dSFT-1 first, followed by one more epoch of SFT on the top-ranked completions of UltraFeedback.
\ • dDPO + dSFT applies dSFT-1 first, followed by one epoch of DPO on UltraFeedback.
\ First, we replicate past results (Ouyang et al., 2022) and show that without an initial SFT step (- dSFT), models are not able to learn at all from feedback and perform terribly. Using dSFT improves model score significantly on both chat benchmarks. We also consider running dSFT directly on the feedback data by training on the most preferred output (dSFT-2); however we find that this does not make an impact in performance. Finally, we see that the full Zephyr models (dDPO+dDSFT) gives a large increase in both benchmarks.
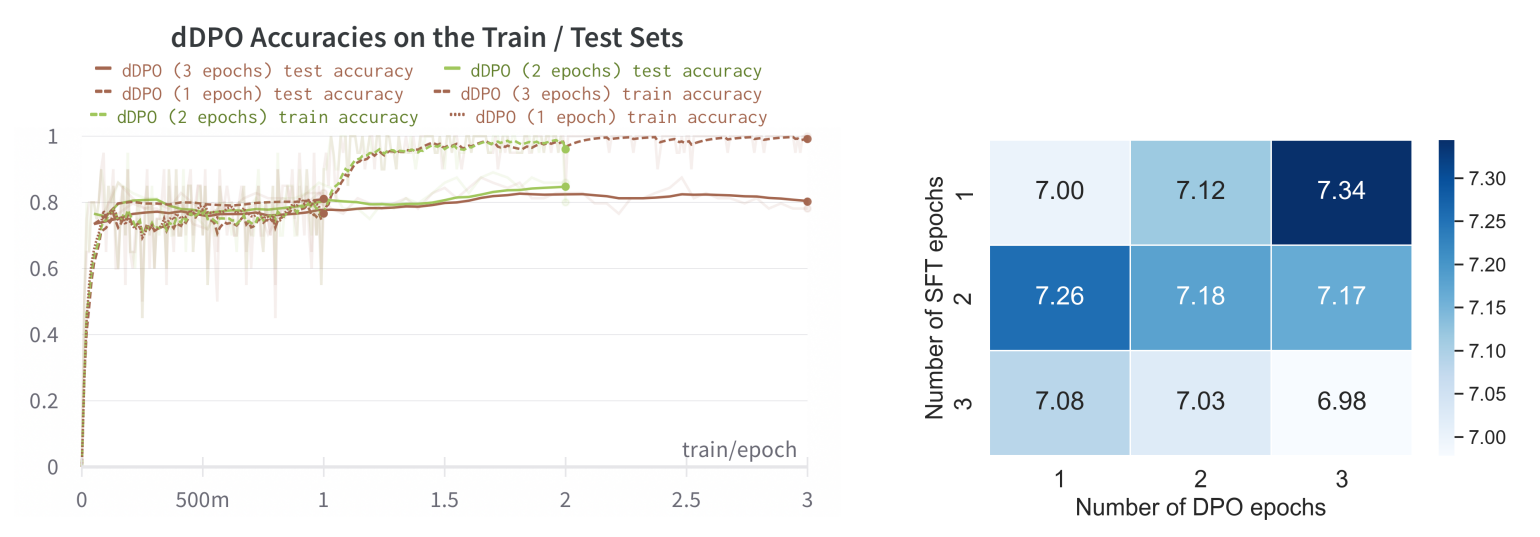
\ Does Overfitting Harm Downstream Performance? In the process of training ZEPHYR-7B we observed that after one epoch of DPO training, the model would strongly overfit, as indicated by perfect training set accuracies in Figure 3. Surprisingly, this did not harm downstream performance on MT-Bench and AlpacaEval; as shown in Figure 3, the strongest model was obtained with one epoch of SFT followed by three epochs of DPO. However, we do observe that if the SFT model is trained for more than one epoch, the DPO step actually induces a performance regression with longer training.
\
\
\
:::info This paper is available on arxiv under CC 4.0 license.
:::
\
This content originally appeared on HackerNoon and was authored by Writings, Papers and Blogs on Text Models
Writings, Papers and Blogs on Text Models | Sciencx (2024-07-03T14:00:21+00:00) Zephyr: Direct Distillation of LM Alignment: Results and Ablations. Retrieved from https://www.scien.cx/2024/07/03/zephyr-direct-distillation-of-lm-alignment-results-and-ablations/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.