
This content originally appeared on HackerNoon and was authored by Nasser Maronie
In an era where data privacy is paramount, setting up your own local language model (LLM) provides a crucial solution for companies and individuals alike. This tutorial is designed to guide you through the process of creating a custom chatbot using Ollama, Python 3, and ChromaDB, all hosted locally on your system. Here are the key reasons why you need this tutorial:
\
- Full Customization: Hosting your own Retrieval-Augmented Generation (RAG) application locally means you have complete control over the setup and customization. You can fine-tune the model to fit your specific needs without relying on external services.
- Enhanced Privacy: By setting up your LLM model locally, you avoid the risks associated with sending sensitive data over the internet. This is especially important for companies that handle confidential information. Training your model with private data locally ensures that your data stays within your control.
- Data Security: Using third-party LLM models can expose your data to potential breaches and misuse. Local deployment mitigates these risks by keeping your training data, such as PDF documents, within your secure environment.
- Control Over Data Processing: When you host your own LLM, you have the ability to manage and process your data exactly how you want. This includes embedding your private data into your ChromaDB vector store, ensuring that your data processing meets your standards and requirements.
- Independence from Internet Connectivity: Running your chatbot locally means you are not dependent on an internet connection. This guarantees uninterrupted service and access to your chatbot, even in offline scenarios.
\ This tutorial will empower you to build a robust and secure local chatbot, tailored to your needs, without compromising on privacy or control.

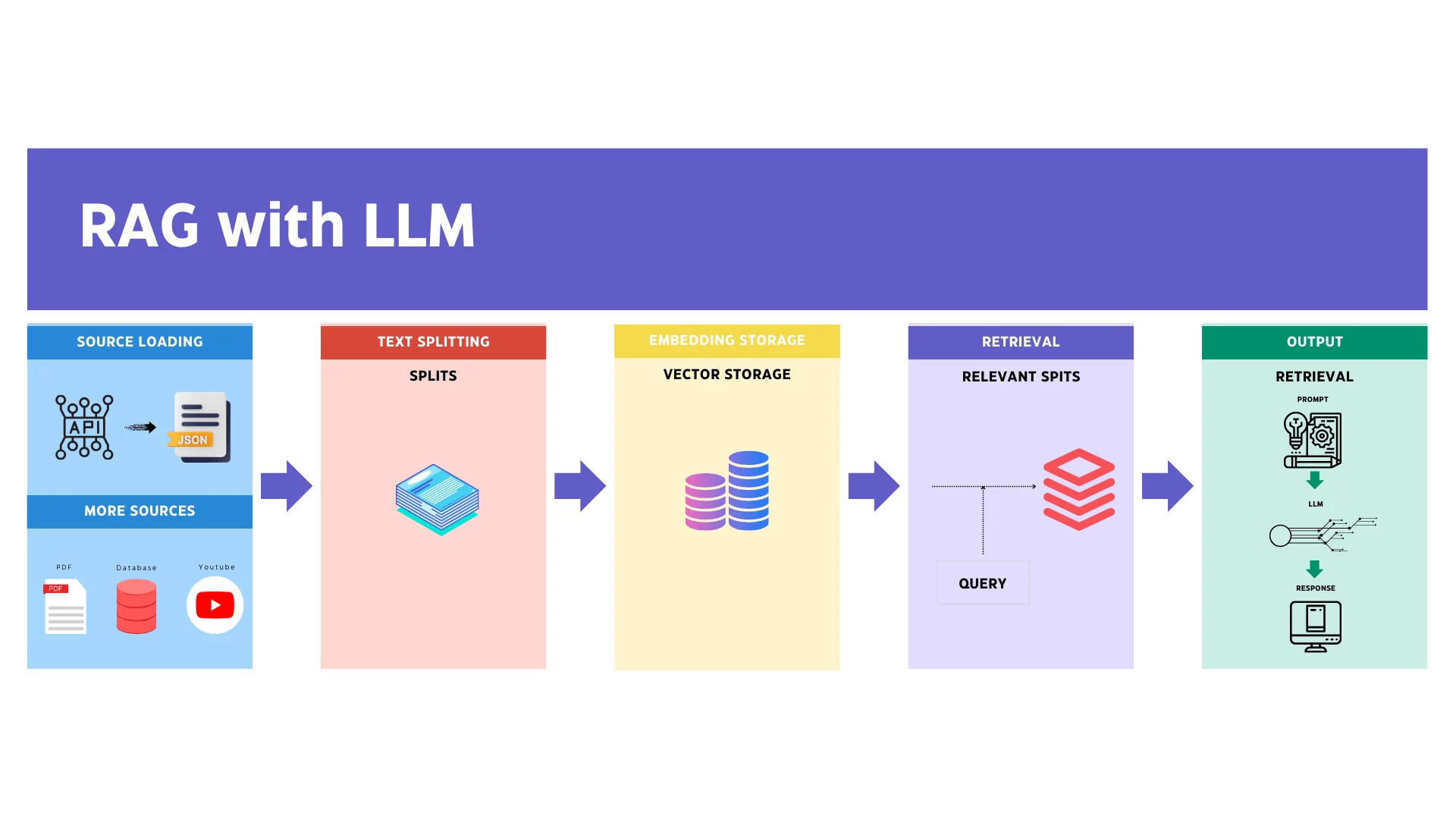
Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) is an advanced technique that combines the strengths of information retrieval and text generation to create more accurate and contextually relevant responses. Here's a breakdown of how RAG works and why it's beneficial:
What is RAG?
RAG is a hybrid model that enhances the capabilities of language models by incorporating an external knowledge base or document store. The process involves two main components:
- Retrieval: In this phase, the model retrieves relevant documents or pieces of information from an external source, such as a database or a vector store, based on the input query.
- Generation: The retrieved information is then used by a generative language model to produce a coherent and contextually appropriate response.
How Does RAG Work?
- Query Input: The user inputs a query or question.
- Document Retrieval: The system uses the query to search an external knowledge base, retrieving the most relevant documents or snippets of information.
- Response Generation: The generative model processes the retrieved information, integrating it with its own knowledge to generate a detailed and accurate response.
- Output: The final response, enriched with specific and relevant details from the knowledge base, is presented to the user.
Benefits of RAG
- Enhanced Accuracy: By leveraging external data, RAG models can provide more precise and detailed answers, especially for domain-specific queries.
- Contextual Relevance: The retrieval component ensures that the generated response is grounded in relevant and up-to-date information, improving the overall quality of the response.
- Scalability: RAG systems can be easily scaled to incorporate vast amounts of data, enabling them to handle a wide range of queries and topics.
- Flexibility: These models can be adapted to various domains by simply updating or expanding the external knowledge base, making them highly versatile.
Why Use RAG Locally?
- Privacy and Security: Running a RAG model locally ensures that sensitive data remains secure and private, as it does not need to be sent to external servers.
- Customization: You can tailor the retrieval and generation processes to suit your specific needs, including integrating proprietary data sources.
- Independence: A local setup ensures that your system remains operational even without internet connectivity, providing consistent and reliable service.
By setting up a local RAG application with tools like Ollama, Python, and ChromaDB, you can enjoy the benefits of advanced language models while maintaining control over your data and customization options.
GPU
Running large language models (LLMs) like the ones used in Retrieval-Augmented Generation (RAG) requires significant computational power. One of the key components that enable efficient processing and embedding of data in these models is the Graphics Processing Unit (GPU). Here's why GPUs are essential for this task and how they impact the performance of your local LLM setup:
What is a GPU?
A GPU is a specialized processor designed to accelerate the rendering of images and videos. Unlike Central Processing Units (CPUs), which are optimized for sequential processing tasks, GPUs excel at parallel processing. This makes them particularly well-suited for the complex mathematical computations required by machine learning and deep learning models.
Why GPUs Matter for LLMs
- Parallel Processing Power: GPUs can handle thousands of operations simultaneously, significantly speeding up tasks such as training and inference in LLMs. This parallelism is crucial for the heavy computational loads associated with processing large datasets and generating responses in real-time.
- Efficiency in Handling Large Models: LLMs like those used in RAG require substantial memory and computational resources. GPUs are equipped with high-bandwidth memory (HBM) and multiple cores, making them capable of managing the large-scale matrix multiplications and tensor operations needed by these models.
- Faster Data Embedding and Retrieval: In a local RAG setup, embedding data into a vector store like ChromaDB and retrieving relevant documents quickly is essential for performance. High-performance GPUs can accelerate these processes, ensuring that your chatbot responds promptly and accurately.
- Improved Training Times: Training an LLM involves adjusting millions (or even billions) of parameters. GPUs can drastically reduce the time required for this training phase compared to CPUs, enabling more frequent updates and refinements to your model.
Choosing the Right GPU
When setting up a local LLM, the choice of GPU can significantly impact performance. Here are some factors to consider:
- Memory Capacity: Larger models require more GPU memory. Look for GPUs with higher VRAM (video RAM) to accommodate extensive datasets and model parameters.
- Compute Capability: The more CUDA cores a GPU has, the better it can handle parallel processing tasks. GPUs with higher compute capabilities are more efficient for deep learning tasks.
- Bandwidth: Higher memory bandwidth allows for faster data transfer between the GPU and its memory, improving overall processing speed.
Examples of High-Performance GPUs for LLMs
- NVIDIA RTX 3090: Known for its high VRAM (24 GB) and powerful CUDA cores, it's a popular choice for deep learning tasks.
- NVIDIA A100: Designed specifically for AI and machine learning, it offers exceptional performance with large memory capacity and high compute power.
- AMD Radeon Pro VII: Another strong contender, with high memory bandwidth and efficient processing capabilities.
Investing in a high-performance GPU is crucial for running LLM models locally. It ensures faster data processing, efficient model training, and quick response generation, making your local RAG application more robust and reliable. By leveraging the power of GPUs, you can fully realize the benefits of hosting your own custom chatbot, tailored to your specific needs and data privacy requirements.
Prerequisites
Before diving into the setup, ensure you have the following prerequisites in place:
- Python 3: Python is a versatile programming language that you'll use to write the code for your RAG app.
- ChromaDB: A vector database that will store and manage the embeddings of our data.
- Ollama: To download and serve custom LLMs in our local machine.
Step 1: Install Python 3 and setup your environment
To install and setup our Python 3 environment, follow these steps: Download and setup Python 3 on your machine. Then make sure your Python 3 installed and run successfully:
$ python3 --version
# Python 3.11.7
Create a folder for your project, for example, local-rag:
$ mkdir local-rag
$ cd local-rag
Create a virtual environment named venv:
$ python3 -m venv venv
Activate the virtual environment:
$ source venv/bin/activate
# Windows
# venv\Scripts\activate
Step 2: Install ChromaDB and other dependencies
Install ChromaDB using pip:
$ pip install --q chromadb
Install Langchain tools to work seamlessly with your model:
$ pip install --q unstructured langchain langchain-text-splitters
$ pip install --q "unstructured[all-docs]"
Install Flask to serve your app as a HTTP service:
$ pip install --q flask
Step 3: Install Ollama
To install Ollama, follow these steps: Head to Ollama download page, and download the installer for your operating system. Verify your Ollama installation by running:
$ ollama --version
# ollama version is 0.1.47
Pull the LLM model you need. For example, to use the Mistral model:
$ ollama pull mistral
Pull the text embedding model. For instance, to use the Nomic Embed Text model:
$ ollama pull nomic-embed-text
Then run your Ollama models:
$ ollama serve
Build the RAG app
Now that you've set up your environment with Python, Ollama, ChromaDB and other dependencies, it's time to build your custom local RAG app. In this section, we'll walk through the hands-on Python code and provide an overview of how to structure your application.
app.py
This is the main Flask application file. It defines routes for embedding files to the vector database, and retrieving the response from the model.
import os
from dotenv import load_dotenv
load_dotenv()
from flask import Flask, request, jsonify
from embed import embed
from query import query
from get_vector_db import get_vector_db
TEMP_FOLDER = os.getenv('TEMP_FOLDER', './_temp')
os.makedirs(TEMP_FOLDER, exist_ok=True)
app = Flask(__name__)
@app.route('/embed', methods=['POST'])
def route_embed():
if 'file' not in request.files:
return jsonify({"error": "No file part"}), 400
file = request.files['file']
if file.filename == '':
return jsonify({"error": "No selected file"}), 400
embedded = embed(file)
if embedded:
return jsonify({"message": "File embedded successfully"}), 200
return jsonify({"error": "File embedded unsuccessfully"}), 400
@app.route('/query', methods=['POST'])
def route_query():
data = request.get_json()
response = query(data.get('query'))
if response:
return jsonify({"message": response}), 200
return jsonify({"error": "Something went wrong"}), 400
if __name__ == '__main__':
app.run(host="0.0.0.0", port=8080, debug=True)
embed.py
This module handles the embedding process, including saving uploaded files, loading and splitting data, and adding documents to the vector database.
import os
from datetime import datetime
from werkzeug.utils import secure_filename
from langchain_community.document_loaders import UnstructuredPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from get_vector_db import get_vector_db
TEMP_FOLDER = os.getenv('TEMP_FOLDER', './_temp')
# Function to check if the uploaded file is allowed (only PDF files)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in {'pdf'}
# Function to save the uploaded file to the temporary folder
def save_file(file):
# Save the uploaded file with a secure filename and return the file path
ct = datetime.now()
ts = ct.timestamp()
filename = str(ts) + "_" + secure_filename(file.filename)
file_path = os.path.join(TEMP_FOLDER, filename)
file.save(file_path)
return file_path
# Function to load and split the data from the PDF file
def load_and_split_data(file_path):
# Load the PDF file and split the data into chunks
loader = UnstructuredPDFLoader(file_path=file_path)
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=7500, chunk_overlap=100)
chunks = text_splitter.split_documents(data)
return chunks
# Main function to handle the embedding process
def embed(file):
# Check if the file is valid, save it, load and split the data, add to the database, and remove the temporary file
if file.filename != '' and file and allowed_file(file.filename):
file_path = save_file(file)
chunks = load_and_split_data(file_path)
db = get_vector_db()
db.add_documents(chunks)
db.persist()
os.remove(file_path)
return True
return False
query.py
This module processes user queries by generating multiple versions of the query, retrieving relevant documents, and providing answers based on the context.
import os
from langchain_community.chat_models import ChatOllama
from langchain.prompts import ChatPromptTemplate, PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain.retrievers.multi_query import MultiQueryRetriever
from get_vector_db import get_vector_db
LLM_MODEL = os.getenv('LLM_MODEL', 'mistral')
# Function to get the prompt templates for generating alternative questions and answering based on context
def get_prompt():
QUERY_PROMPT = PromptTemplate(
input_variables=["question"],
template="""You are an AI language model assistant. Your task is to generate five
different versions of the given user question to retrieve relevant documents from
a vector database. By generating multiple perspectives on the user question, your
goal is to help the user overcome some of the limitations of the distance-based
similarity search. Provide these alternative questions separated by newlines.
Original question: {question}""",
)
template = """Answer the question based ONLY on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
return QUERY_PROMPT, prompt
# Main function to handle the query process
def query(input):
if input:
# Initialize the language model with the specified model name
llm = ChatOllama(model=LLM_MODEL)
# Get the vector database instance
db = get_vector_db()
# Get the prompt templates
QUERY_PROMPT, prompt = get_prompt()
# Set up the retriever to generate multiple queries using the language model and the query prompt
retriever = MultiQueryRetriever.from_llm(
db.as_retriever(),
llm,
prompt=QUERY_PROMPT
)
# Define the processing chain to retrieve context, generate the answer, and parse the output
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
response = chain.invoke(input)
return response
return None
get_vector_db.py
This module initializes and returns the vector database instance used for storing and retrieving document embeddings.
import os
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.vectorstores.chroma import Chroma
CHROMA_PATH = os.getenv('CHROMA_PATH', 'chroma')
COLLECTION_NAME = os.getenv('COLLECTION_NAME', 'local-rag')
TEXT_EMBEDDING_MODEL = os.getenv('TEXT_EMBEDDING_MODEL', 'nomic-embed-text')
def get_vector_db():
embedding = OllamaEmbeddings(model=TEXT_EMBEDDING_MODEL,show_progress=True)
db = Chroma(
collection_name=COLLECTION_NAME,
persist_directory=CHROMA_PATH,
embedding_function=embedding
)
return db
Run your app!
Create .env file to store your environment variables:
TEMP_FOLDER = './_temp'
CHROMA_PATH = 'chroma'
COLLECTION_NAME = 'local-rag'
LLM_MODEL = 'mistral'
TEXT_EMBEDDING_MODEL = 'nomic-embed-text'
Run the app.py file to start your app server:
$ python3 app.py
Once the server is running, you can start making requests to the following endpoints:
- Example command to embed a PDF file (e.g., resume.pdf):
$ curl --request POST \
--url http://localhost:8080/embed \
--header 'Content-Type: multipart/form-data' \
--form file=@/Users/nassermaronie/Documents/Nasser-resume.pdf
# Response
{
"message": "File embedded successfully"
}
- Example command to ask a question to your model:
$ curl --request POST \
--url http://localhost:8080/query \
--header 'Content-Type: application/json' \
--data '{ "query": "Who is Nasser?" }'
# Response
{
"message": "Nasser Maronie is a Full Stack Developer with experience in web and mobile app development. He has worked as a Lead Full Stack Engineer at Ulventech, a Senior Full Stack Engineer at Speedoc, a Senior Frontend Engineer at Irvins, and a Software Engineer at Tokopedia. His tech stacks include Typescript, ReactJS, VueJS, React Native, NodeJS, PHP, Golang, Python, MySQL, PostgresQL, MongoDB, Redis, AWS, Firebase, and Supabase. He has a Bachelor's degree in Information System from Universitas Amikom Yogyakarta."
}
Conclusion
By following these instructions, you can effectively run and interact with your custom local RAG app using Python, Ollama, and ChromaDB, tailored to your needs. Adjust and expand the functionality as necessary to enhance the capabilities of your application.
By harnessing the capabilities of local deployment, you not only safeguard sensitive information but also optimize performance and responsiveness. Whether you're enhancing customer interactions or streamlining internal processes, a locally deployed RAG application offers flexibility and robustness to adapt and grow with your requirements.
Check the source code in this repo:
https://github.com/firstpersoncode/local-rag
\ Happy coding!
This content originally appeared on HackerNoon and was authored by Nasser Maronie
Nasser Maronie | Sciencx (2024-07-04T10:00:15+00:00) Build Your Own RAG App: A Step-by-Step Guide to Setup LLM locally using Ollama, Python, and ChromaDB. Retrieved from https://www.scien.cx/2024/07/04/build-your-own-rag-app-a-step-by-step-guide-to-setup-llm-locally-using-ollama-python-and-chromadb/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.