
This content originally appeared on HackerNoon and was authored by How Hash Functions Function
:::info Authors:
(1) Busra Tabak [0000 −0001 −7460 −3689], Bogazici University, Turkey {busra.tabak@boun.edu.tr};
(2) Fatma Basak Aydemir [0000 −0003 −3833 −3997], Bogazici University, Turkey {basak.aydemir@boun.edu.tr}.
:::
Table of Links
- Abstract and Introduction
- Background
- Approach
- Experiments and Results
- Discussion and Qualitative Analysis
- Related Work
- Conclusions and Future Work, and References
2 Background
To understand our approach, it is essential to have a solid understanding of the structure of software issues in Issue Tracking Systems (ITS).
2.1 Software Issues in ITS
This section explores software issues within ITS, covering their anatomy, life cycle, and significance in software projects.
\ Issue Tracking Systems (ITS) An issue tracking system (ITS) is a software application that manages and maintains lists of issues. It provides a database of issue reports for a software project. Members of the software development team stay aligned and collaborate faster with the help of these tools. Users can log in with a password and post a new issue report or comment on an already-posted issue. There are various issue-tracking tools that are used in software development projects, such as JIRA, Bugzilla, and Azure DevOps. Although there are some differences among these tools, they all share a similar basic structure. We developed our approach with a data set of a company that uses JIRA software.
\ Anatomy of an Issue The issue report in ITS contains various fields, each of which contains a different piece of information as shown in Figure 1. The following details [48] could typically be included in the generic process of reporting an issue:
\ – Summary: Title of the issue.
\ – Description: Issue details including its cause, location, and timing.
\ – Version: Version of the project to which the issue belongs.
\ – Component: The predetermined component on which the issue depends.
\ – Attachment: Attaches such as pictures, videos, and documents uploaded to the issue.
\ – Priority: Urgency level of the issue.
\ – Severity: Frequent occurrence and systemic effects.
\ – Status: Current status of the issue.
\ – Reporter: Person who creates the issue.
\ – Assignee: Person to whom the issue is assigned.
\ – Revision History: Historical changes of the issue.
\ – Estimated time: Estimated time spent to develop or solve the issue.
\ – Comments: Additional details that can be used to understand the issue.
\
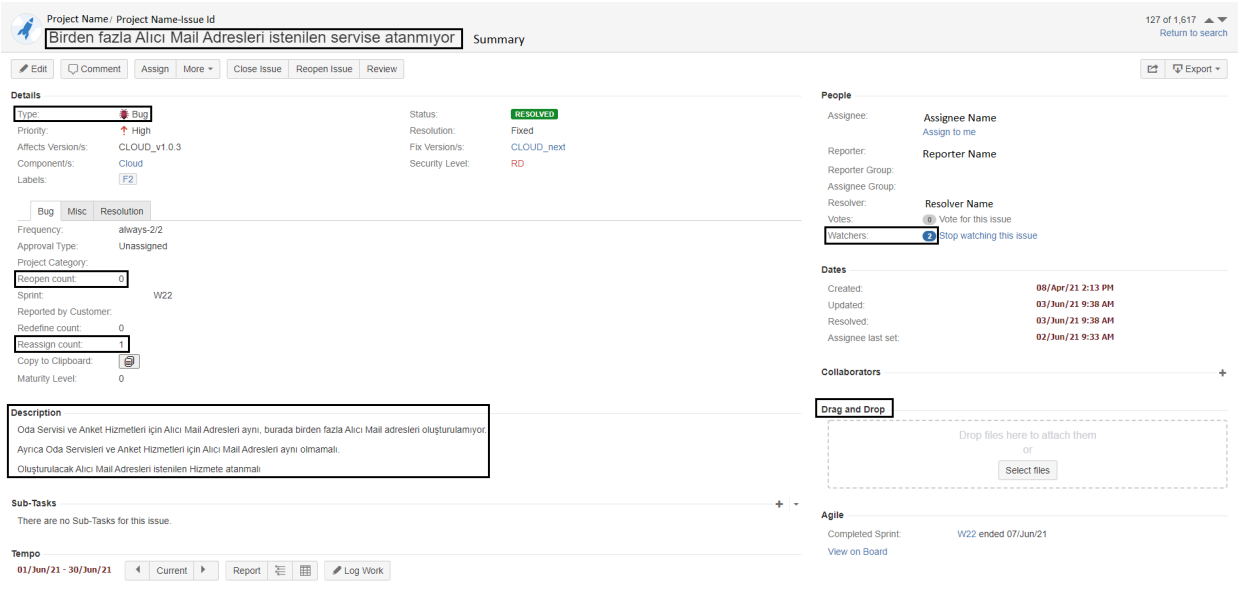
\ The summary, description, and comments all contain textual details about the issue. In our methodology, we extract numerical features using the language structure of summary and description. Version is the current version of the project which differs with each release. The issue can have a predefined tag or component added to it. (e.g. project v1.1.0) Users can upload files to help others understand the issue, an attachment refers to it. Priority, severity, and status are the categorical features of the issue. Priority is the urgency level, severity is the frequency of occurrence and status is the current status of the issue such as committed or done. People play different roles as they interact with reports in ITS. The person who submits the report is the reporter and the assignee is the person to whom the issue is assigned. If the issue has been reported previously, historical changes are shown in the revision history. The estimated time is the time spent on the development and varies depending on the effort metric. The fields offered by each ITS vary, and not all fields are filled out for each project. Our strategy makes use of the fields that are largely filled in.
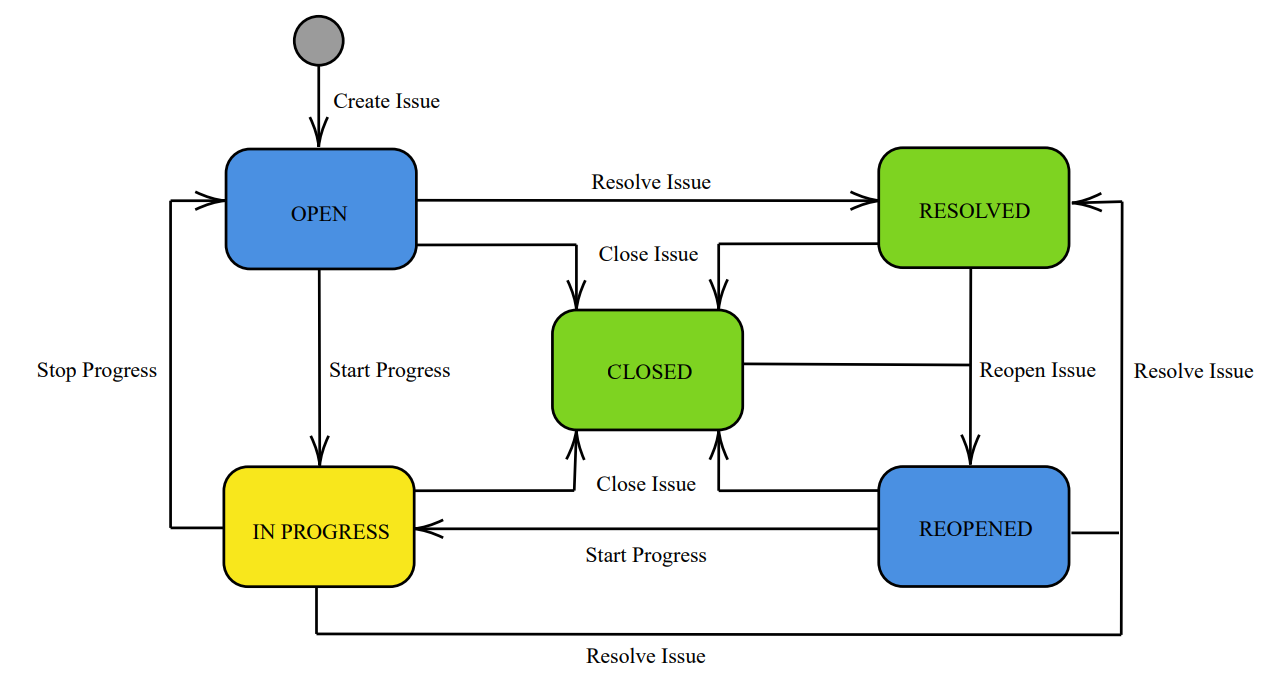
\ Life Cycle of an Issue The series of phases and phase changes that an issue experiences throughout its life cycle is referred to as a “workflow.” Workflows for issues typically represent development cycles and business processes. Figure 2 shows a standard workflow of JIRA. The following stages of the JIRA workflow must be monitored as soon as an issue is created:
\ – Open: The issue is open after creation and can be assigned to the assignee to begin working on it.
\ – In Progress: The assignee has taken the initiative to begin working on the issue.
\ – Resolved: The issue’s sub-tasks and works have all been finished. The reporter is currently waiting to confirm the matter. If verification is successful, the case will be closed or reopened depending on whether any additional changes are needed.
\ – Reopened: Although this issue has already been solved, the solution is either flawed, omitted some important details, or needs some modifications. Issues are classified as assigned or resolved at the Reopened stage.
\ – Closed: The issue is now regarded as resolved, and the current solution is accurate. Issues that have been closed can be reopened at a later time as needed.
\
\
:::info This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.
:::
\
This content originally appeared on HackerNoon and was authored by How Hash Functions Function
How Hash Functions Function | Sciencx (2024-07-05T11:00:29+00:00) Comparison of Machine Learning Methods: Background. Retrieved from https://www.scien.cx/2024/07/05/comparison-of-machine-learning-methods-background/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.