
This content originally appeared on Level Up Coding - Medium and was authored by Pavan Belagatti
While LLMs are all good and trending for all the positive reasons, they also pose some disadvantages if not used properly. Yes, LLMs can sometimes produce the responses that aren’t expected, they can be fake, made up information or even biased. Now, this can happen for various reasons. We call this process of generating misinformation by LLMs as hallucination.
There are some notable approaches to mitigate the LLM hallucinations such as fine-tuning, prompt engineering, retrieval augmented generation (RAG) etc.Retrieval augmented generation (RAG) has been the most talked about approach in mitigating the hallucinations faced by large language models.
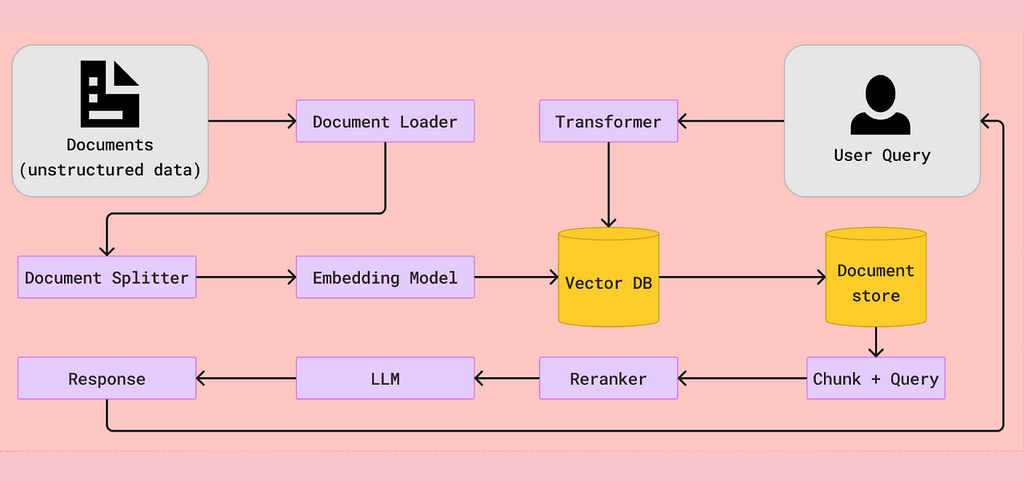
Large Language Models (LLMs) sometimes produce hallucinated answers and one of the techniques to mitigate these hallucinations is by RAG. For an user query, RAG tends to retrieve the information from the provided source/information/data that is stored in a vector database. A vector database is the one that is a specialized database other than the traditional databases where vector data is stored.
Vector data is in the form of embeddings that captures the context and meaning of the objects. For example, think of a scenario where you would like to get custom responses from your AI application.
First, the organization’s documents are converted into embeddings through an embedding model and stored in a vector database. When a query is sent to the AI application, it gets converted into a vector query embedding and goes through the vector database to find the most similar object by vector similarity search. This way, your LLM-powered application doesn’t hallucinate since you have already instructed it to provide custom responses and is fed with the custom data.
One simple use case would be the customer support application, where the custom data is fed to the application stored in a vector database and when a user query comes in, it generates the most appropriate response related to your products or services and not some generic answer. This way, RAG is revolutionizing many other fields in the world.
RAG pipeline
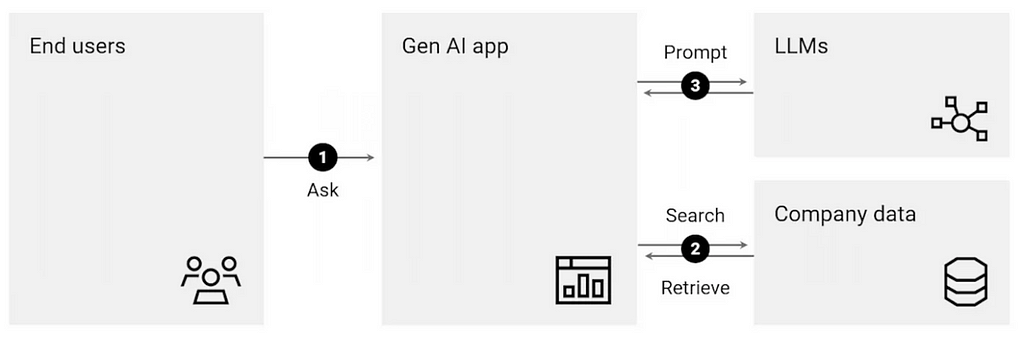
The RAG pipeline basically involves three critical components: Retrieval component, Augmentation component, Generation component.
- Retrieval: This component helps you fetch the relevant information from the external knowledge base like a vector database for any given user query. This component is very crucial as this is the first step in curating the meaningful and contextually correct responses.
- Augmentation: This part involves enhancing and adding more relevant context to the retrieved response for the user query.
- Generation: Finally, a final output is presented to the user with the help of a large language model (LLM). The LLM uses its own knowledge and the provided context and comes up with an apt response to the user’s query.
These three components are the basis of a RAG pipeline to help users to get the contextually-rich and accurate responses they are looking for. That is the reason why RAG is so special when it comes to building chatbots, question-answering systems, etc.
Chunking Strategies in RAG
mproving the efficiency of LLM applications via RAG is all great.
BUT the question is, what should be the right chunking strategy?
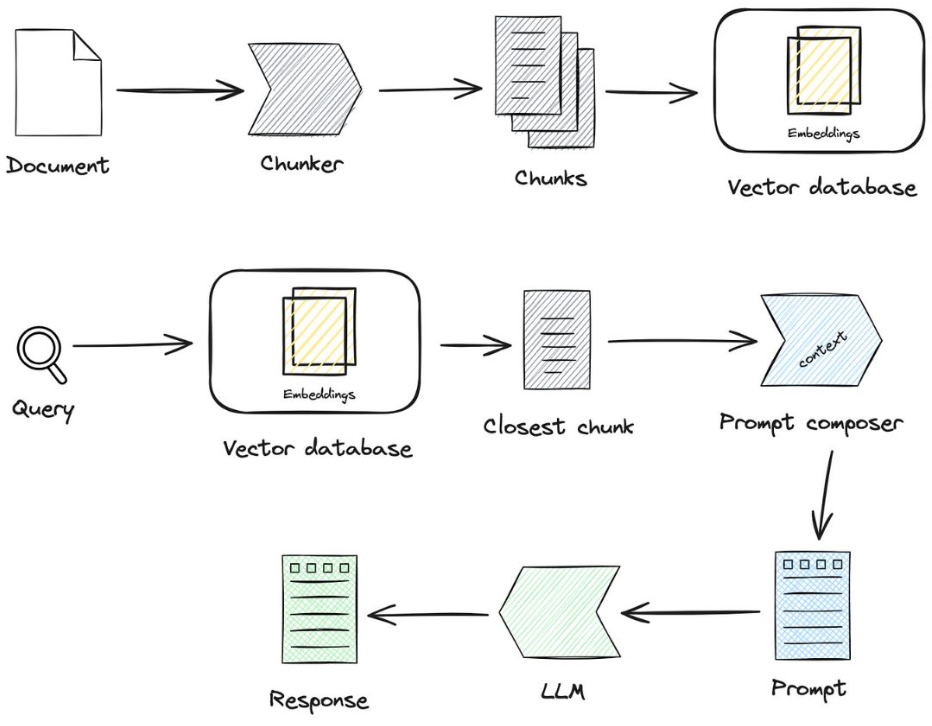
Chunking is the method of breaking down the large files into more manageable segments/chunks so the LLM applications can get proper context and the retrieval can be easy.
In a video on YouTube, Greg Kamradt provides overview of different chunking strategies. Let’s understand them one by one.
They have been classified into five levels based on the complexity and effectiveness.
⮕ Level 1 : Fixed Size Chunking
This is the most crude and simplest method of segmenting the text. It breaks down the text into chunks of a specified number of characters, regardless of their content or structure.Langchain and llamaindex framework offer CharacterTextSplitter and SentenceSplitter (default to spliting on sentences) classes for this chunking technique.
⮕ Level 2: Recursive Chunking
While Fixed size chunking is easier to implement, it doesn’t consider the structure of text. Recursive chunking offers an alternative. In this method, we divide the text into smaller chunk in a hierarchical and iterative manner using a set of separators. Langchain framework offers RecursiveCharacterTextSplitter class, which splits text using default separators (“\n\n”, “\n”, “ “,””)
⮕ Level 3 : Document Based Chunking
In this chunking method, we split a document based on its inherent structure. This approach considers the flow and structure of content but may not be as effective documents lacking clear structure.
⮕ Level 4: Semantic Chunking
All above three levels deals with content and structure of documents and necessitate maintaining constant value of chunk size. This chunking method aims to extract semantic meaning from embeddings and then assess the semantic relationship between these chunks. The core idea is to keep together chunks that are semantic similar.Llamindex has SemanticSplitterNodeParse class that allows to split the document into chunks using contextual relationship between chunks.
⮕ Level 5: Agentic Chunking
This chunking strategy explore the possibility to use LLM to determine how much and what text should be included in a chunk based on the context.
Know more about these chunking strategies in this article.
Here is the Greg’s video.
As you all know, I talk a lot about RAG and strategies to enhance AI applications. In my daily search and while reading about RAG, I found this amazing API by trufflepig that can help our RAG applications with great retrieval.
Using RAG to make unstructured data accessible by AI is popular but presents significant challenges. These include managing the unpredictability of unstructured datasets and ensuring retrieval quality. trufflepig addresses these challenges directly by allowing developers to upload data as-is and receive relevant results based on a query.
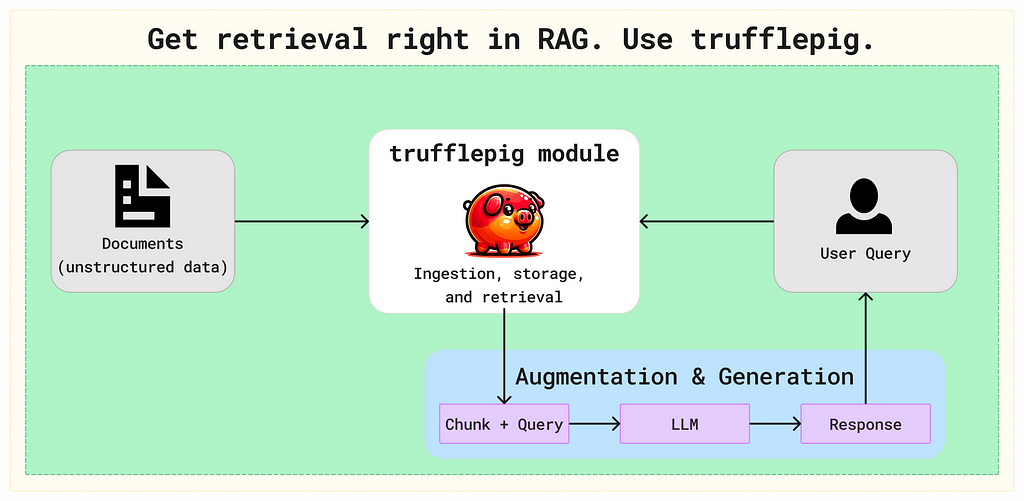
trufflepig is a fully managed retrieval API that makes unstructured data searchable through natural language. It provides an end-to-end solution for the retrieval step of RAG, so you can focus on perfecting the business-specific aspects of your application instead of creating and managing infrastructure.
trufflepig’s retrieval approach eliminates the tinkering involved with other frameworks or RAG tools. Forget managing separate document stores, custom chunking logic, or ingestion. Our system intelligently indexes your data based on its semantic structure for lightning-fast, relevant retrieval.
Try trufflepig’s API at https://bit.ly/3KHEuwM and start building better RAG with state-of-the-art retrieval.
RAG Pain Points & Solutions
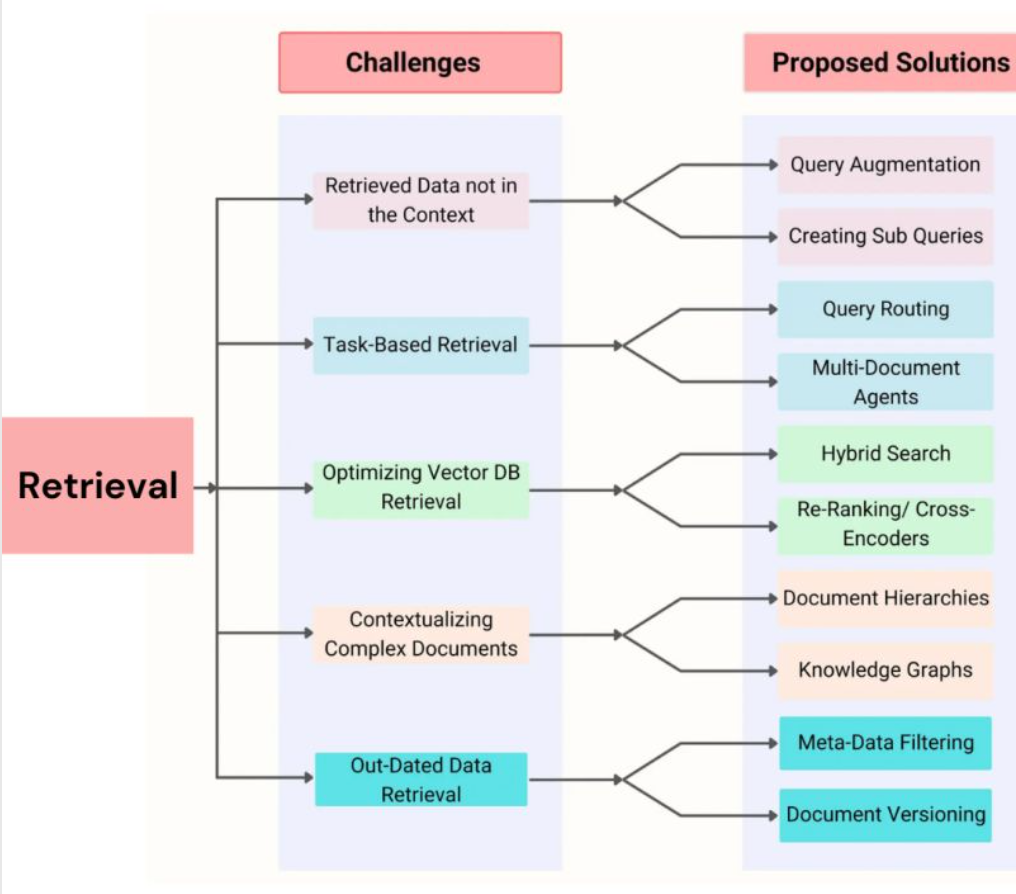
RAG might seem easy at first glance but that may not be true. Effective retrieval is a pain, and you can encounter several issues during this important stage.
Here are some common pain points and possible solutions in the retrival stage.
⮕ Challenge: Retrieved data not in context & there can be several reasons for this.
➤ Missed Top Rank Documents: The system sometimes doesn’t include essential documents that contain the answer in the top results returned by the system’s retrieval component.
➤ Incorrect Specificity: Responses may not provide precise information or adequately address the specific context of the user’s query.
➤ Losing Relevant Context During Reranking: This occurs when documents containing the answer are retrieved from the database but fail to make it into the context for generating an answer.
Here are the Proposed Solutions
➤ Query Augmentation: Query augmentation enables RAG to retrieve information that is in context by enhancing the user queries with additional contextual details or modifying them to maximize relevancy. This involves improving the phrasing, adding company-specific context, and generating sub-questions that help contextualize and generate accurate responses
- Rephrasing
- Hypothetical document embeddings
- Sub-queries
➤ Tweak retrieval strategies: Llama Index offers a range of retrieval strategies, from basic to advanced, to ensure accurate retrieval in RAG pipelines. By exploring these strategies, developers can improve the system’s ability to incorporate relevant information into the context for generating accurate responses.
- Small-to-big sentence window retrieval
- recursive retrieval
- semantic similarity scoring
➤ Hyperparameter tuning for chunk size and similarity_top_k: This solution involves adjusting the parameters of the retrieval process in RAG models. More specifically, we can tune the parameters related to chunk size and similarity_top_k.The chunk_size parameter determines the size of the text chunks used for retrieval, while similarity_top_k controls the number of similar chunks retrieved. By experimenting with different values for these parameters, developers can find the optimal balance between computational efficiency and the quality of retrieved information.
➤ Reranking: Reranking retrieval results before they are sent to the language model has proven to improve RAG systems’ performance significantly.This reranking process can be implemented by incorporating the reranker as a postprocessor in the RAG pipeline.
Know more about the other pain points & possible solutions explained in detail.
RAG Using LlamaIndex
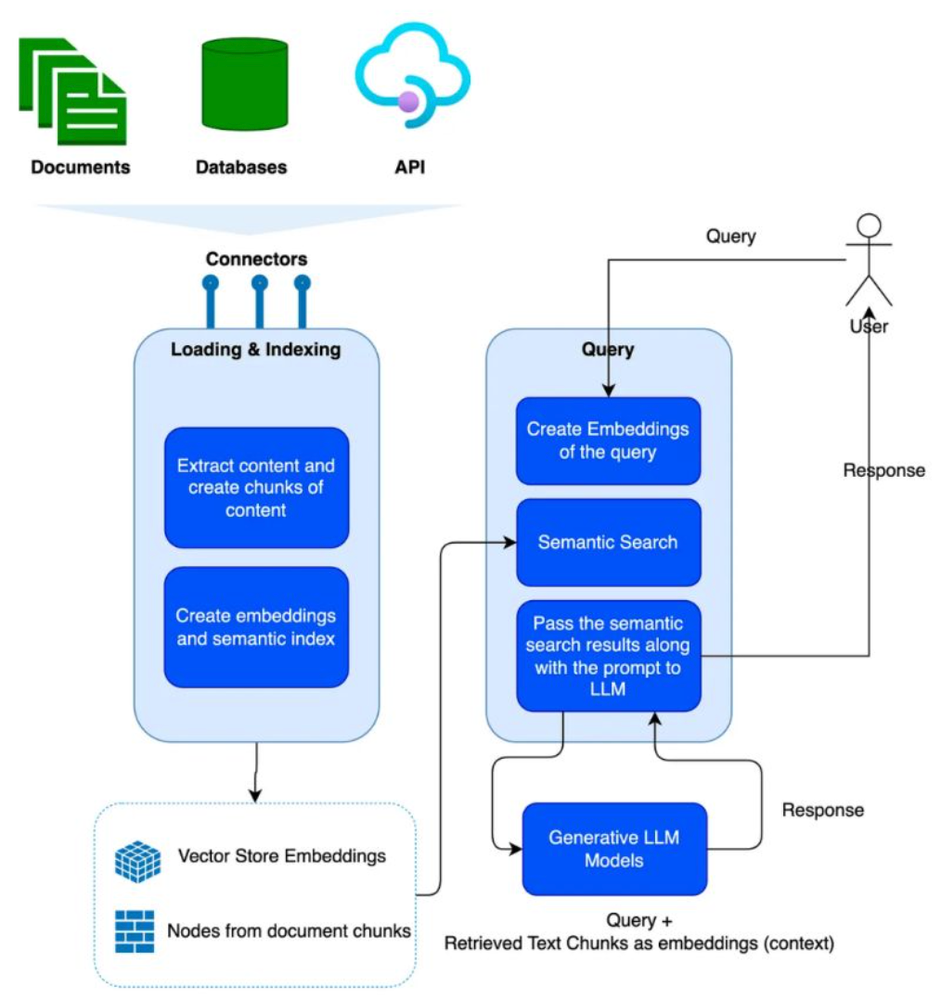
LlamaIndex is a framework, that provides libraries to create advanced RAG applications. The image shows a high level approach of how LlamaIndex works. Let’s understand the LlamaIndex workflow better.
⮕ LlamaIndex provides a framework to ingest various types of content, such as documents, databases, and APIs, which makes it a powerful framework to build LLM applications, that have multiple types of content, and you want to have an integrated response to your queries.
⮕ LlamaIndex has 2 major phases. Loading/Indexing and querying.
⮕ In the loading & indexing phase, the documents that are ingested are broken down into chunks of content. These chunks are converted to embedding, using embedding models. This creates a vector representation of the content, with similar content mapped closer in a Multi-dimensional space. This vector is stored in a vector DB (use SingleStore as your vector database for free), LlamaIndex also stores the index, for faster semantic search.
⮕ When a query is issued, the query is converted to embedding vectors, and a semantic search is performed on the vector database, to retrieve all similar content, which can serve as the context to the query. This is then passed to the large language model, for a response.
Know more in the original article. If you are a beginner and trying to understand LlamaIndex, here is my beginner level article on LlamaIndex.
RAG Using LangChain
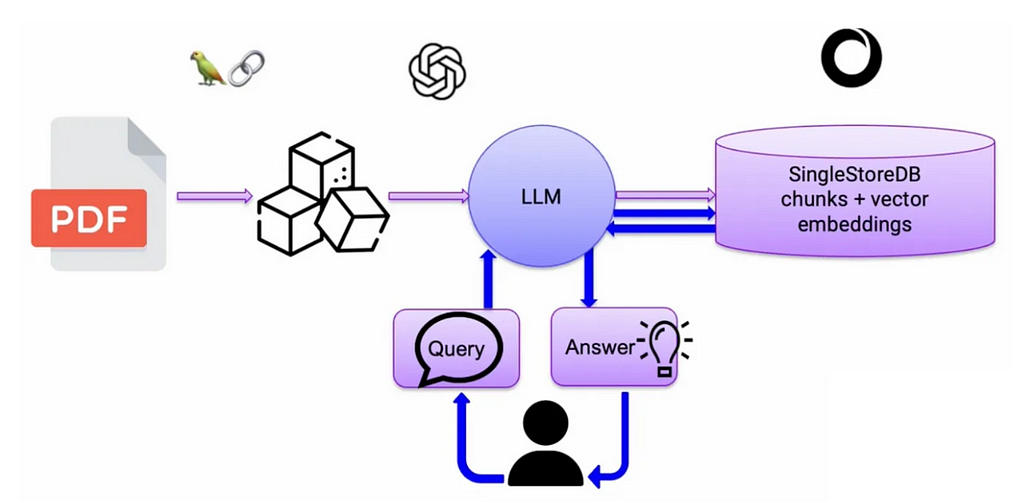
LangChain is an open-source AI framework developed by Harrison Chase to help developers to create robust AI applications by provisioning all the components required. LangChain is equipped with memory capabilities, integrations with vector databases, tools to connect with external data sources, logic and APIs. This makes LangChain a powerful framework for building LLM-powered applications.
See the above image for example, the PDF is our external knowledge base that is stored in a vector database in the form of vector embeddings (vector data). Basically, the PDF document gets split into small chunks of words and these words are then assigned with numerical numbers known as vector embeddings. You need an embedding model to convert text, image, audio, video, into embeddings.
The user query goes through the same LLM to convert it into an embedding and then through the vector database to find the most relevant document. Once the relevant document is found, it is then added with more context through the LLM and finally the response is generated. This way, RAG has become the bread and butter of most of the LLM-powered applications to retrieve the most accurate if not relevant responses. Well, there are some notable AI frameworks such as LangChain and LlamaIndex that help these LLM applications to be robust by providing all the toolkit required.
Let’s understand using LangChain in the RAG setup through this tutorial.
RAG Evaluation Strategies
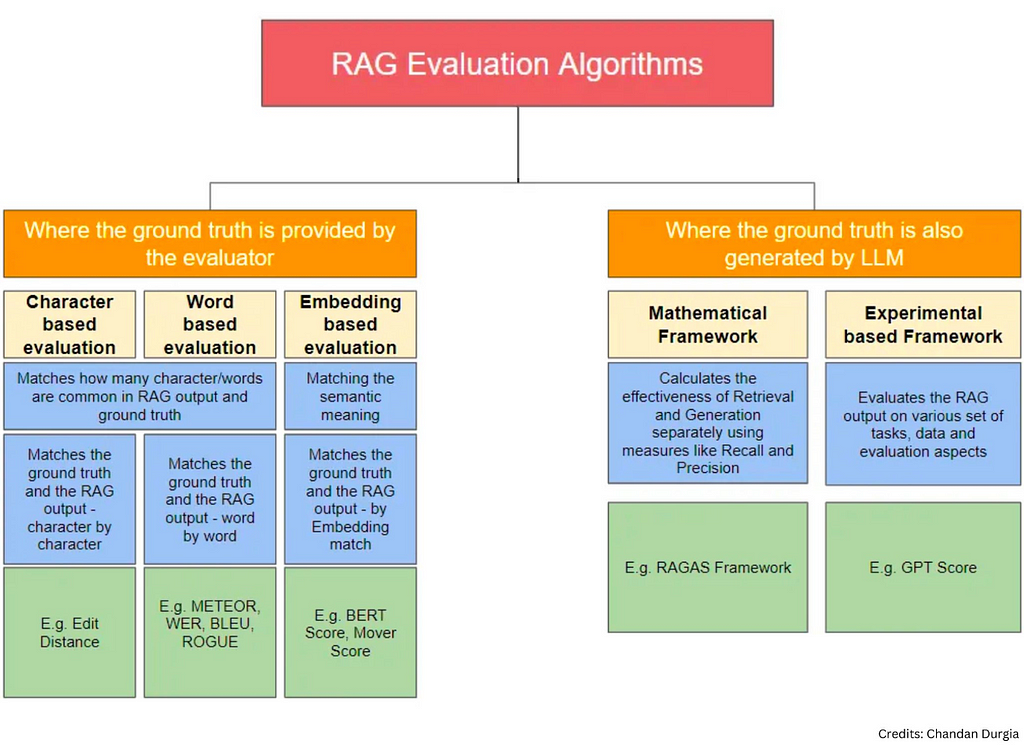
The field of RAG evaluation continues to evolve & it is very important for AI/ML/Data engineers to know these concepts thoroughly.
RAG evaluation includes the evaluation of retrieval & the generation component with the specific input text.
At a high level, RAG evaluation algorithms can be bifurcated into two categories. 1) Where the ground truth (the ideal answer) is provided by the evaluator/user 2) Where the ground truth (the ideal answer) is also generated by another LLM.
For the ease of understanding, the author has further classified these categories into 5 sub-categories.
1. Character based evaluation
2. Word based evaluation
3. Embedding based evaluation
4. Mathematical Framework
5. Experimental based framework
Let’s take a look at each of these evaluation categories:
1. Where the ground truth is provided by the evaluator.
→ Character based evaluation algorithm:
As the name indicates, this algorithm finds a score which is the character by character difference between the reference (ground truth) and the RAG translation output.
→ Word based evaluation algorithm:
As the name indicates, this algorithm finds a score which is the word by word difference between the reference (ground truth) and the RAG output.
→ Embedding based evaluation algorithms:
Embedding based algorithms works in two steps.
Step 1: Create embeddings for both the generated text and the reference text using a particular embedding technique
Step 2: Use a distance measure (like cosine similarity) to evaluate the distance between the embeddings of the generated text and the reference text.
2. Where the ground truth is also generated by LLM (LLM assisted evaluation)
→ Mathematical Framework — RAGAS Score
RAGAS is one of the most common and comprehensive frameworks to assess the RAG accuracy and relevance. RAG bifurcates the evaluation from Retrieval and Generation perspective.
→ Experimental Based Framework — GPT score
The effectiveness of this approach in achieving desired text evaluations through natural language instructions is demonstrated by evaluating experimental results on four text generation tasks, 22 evaluation aspects, and 37 corresponding datasets.
Know more about RAG evaluation in this original article.
The Many Facets of RAG: From Data to Intelligent Applications was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Pavan Belagatti
Pavan Belagatti | Sciencx (2024-07-05T13:47:47+00:00) The Many Facets of RAG: From Data to Intelligent Applications. Retrieved from https://www.scien.cx/2024/07/05/the-many-facets-of-rag-from-data-to-intelligent-applications/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.