
This content originally appeared on Level Up Coding - Medium and was authored by Abhijeet Singh

Overview
In Google Cloud, you can build data pipelines that execute Python code to ingest and transform data from publicly available datasets into BigQuery using these Google Cloud services:
- Cloud Storage
- Dataflow
- BigQuery
What you’ll do
You learn how to:
- Build and run Dataflow pipelines (Python) for data ingestion
- Build and run Dataflow pipelines (Python) for data transformation and enrichment
Note: To view a menu with a list of Google Cloud products and services, click the Navigation menu at the top-left.

Ensure that the Dataflow API is successfully enabled
To ensure access to the necessary API, restart the connection to the Dataflow API.
Important: even if the API is already enabled, follow steps 1–4 below to disable, and then reenable the API, in order to restart the API successfully.
- In the Cloud Console, enter “Dataflow API” in the top search bar. Click on the result for Dataflow API.
- Click Manage.
- Click Disable API.
If asked to confirm, click Disable.
- Click Enable.
When the API has been enabled again, the page will show the option to disable.
Download the starter code
- Run the following command in the Cloud Shell to get Dataflow Python Examples from Google Cloud’s professional services GitHub:
gsutil -m cp -R gs://spls/gsp290/dataflow-python-examples .
2 . Now, in Cloud Shell, set a variable equal to your project id .
export PROJECT=
gcloud config set project $PROJECT
Create a Cloud Storage bucket
- Use the make bucket command in the Cloud Shell to create a new regional bucket in the givem region within your project (take project ID as bucket name which is unique):
gsutil mb -c regional -l gs://$PROJECT
Copy files to your bucket
Use the gsutil command in the Cloud Shell to copy files into the Cloud Storage bucket you just created:
gsutil cp gs://spls/gsp290/data_files/usa_names.csv gs://$PROJECT/data_files/
gsutil cp gs://spls/gsp290/data_files/head_usa_names.csv gs://$PROJECT/data_files/
Create a BigQuery dataset
- In the Cloud Shell, create a dataset in BigQuery Dataset called lake. This is where all of your tables will be loaded in BigQuery:
bq mk lake
Build a Dataflow pipeline
In this section you will create an append-only Dataflow which will ingest data into the BigQuery table. You can use the built-in code editor which will allow you to view and edit the code in the Google Cloud console.
Open the Cloud Shell Code Editor
- Navigate to the source code by clicking on the Open Editor icon in the Cloud Shell:

2 . If prompted, click on Open in a New Window. It will open the code editor in new window. The Cloud Shell Editor allows you to edit files in the Cloud Shell environment, from the Editor you can return to the Cloud Shell by Clicking on Open Terminal.
Data ingestion with a Dataflow Pipeline
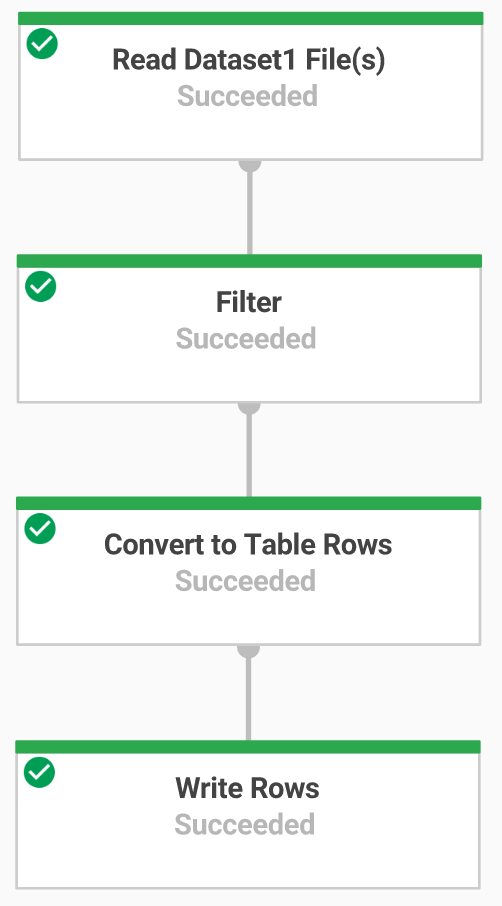
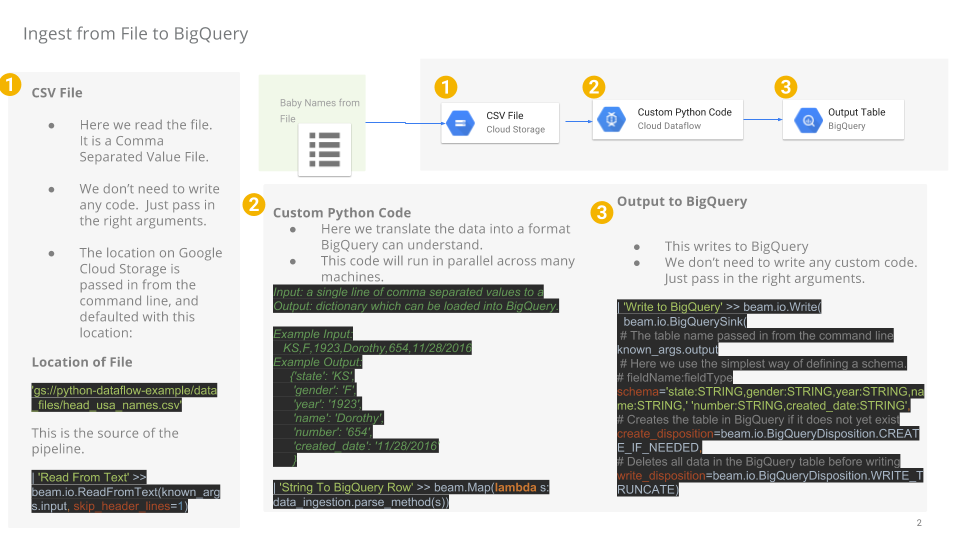
You will now build a Dataflow pipeline with a TextIO source and a BigQueryIO destination to ingest data into BigQuery. More specifically, it will:
- Ingest the files from Cloud Storage.
- Filter out the header row in the files.
- Convert the lines read to dictionary objects.
- Output the rows to BigQuery.
Review pipeline Python code
In the Code Editor navigate to dataflow-python-examples > dataflow_python_examples and open the data_ingestion.py file. Read through the comments in the file, which explain what the code is doing. This code will populate the dataset lake with a table in BigQuery.
Run the Apache Beam pipeline
- Return to your Cloud Shell session for this step. You will now do a bit of set up for the required python libraries.
The Dataflow job in this lab requires Python3.8. To ensure you're on the proper version, you will run the Dataflow processes in a Python 3.8 Docker container.
2 . Run the following in Cloud Shell to start up a Python Container:
docker run -it -e PROJECT=$PROJECT -v $(pwd)/dataflow-python-examples:/dataflow python:3.8 /bin/bash
This command will pull a Docker container with the latest stable version of Python 3.8 and execute a command shell to run the next commands within the container. The -v flag provides the source code as a volume for the container so that we can edit in Cloud Shell editor and still access it within the running container.
3 . Once the container finishes pulling, and starts executing in the Cloud Shell, run the following to install apache-beam in that running container:
pip install apache-beam[gcp]==2.24.0
4 . Next, in the running container in the Cloud Shell, change directories into where you linked the source code:
cd dataflow/
Run the ingestion Dataflow pipeline in the cloud
5 . The following will spin up the workers required, and shut them down when complete:
python dataflow_python_examples/data_ingestion.py \
--project=$PROJECT --region= \
--runner=DataflowRunner \
--machine_type=e2-standard-2 \
--staging_location=gs://$PROJECT/test \
--temp_location gs://$PROJECT/test \
--input gs://$PROJECT/data_files/head_usa_names.csv \
--save_main_session
6 . Return to the Cloud Console and open the Navigation menu > Dataflow to view the status of your job.

7 . Click on the name of your job to watch it’s progress. Once your Job Status is Succeeded, you can move to the next step. This Dataflow pipeline will take approximately five minutes to start, complete the work, and then shutdown.
8 . Navigate to BigQuery (Navigation menu > BigQuery) see that your data has been populated.
9 . Click on your project name to see the usa_names table under the lake dataset.

10 . Click on the table then navigate to the Preview tab to see examples of the usa_names data.
Note: If you don’t see the usa_names table, try refreshing the page or view the tables using the classic BigQuery UI.
Data transformation
You will now build a Dataflow pipeline with a TextIO source and a BigQueryIO destination to ingest data into BigQuery. More specifically, you will:
- Ingest the files from Cloud Storage.
- Convert the lines read to dictionary objects.
- Transform the data which contains the year to a format BigQuery understands as a date.
- Output the rows to BigQuery.
Review transformation pipeline python code
In the Code Editor, open data_transformation.py file. Read through the comments in the file which explain what the code is doing.
Run the Dataflow transformation pipeline
You will run the Dataflow pipeline in the cloud. This will spin up the workers required, and shut them down when complete.
- Run the following commands to do so:
python dataflow_python_examples/data_transformation.py \
--project=$PROJECT \
--region= \
--runner=DataflowRunner \
--machine_type=e2-standard-2 \
--staging_location=gs://$PROJECT/test \
--temp_location gs://$PROJECT/test \
--input gs://$PROJECT/data_files/head_usa_names.csv \
--save_main_session
- Navigate to Navigation menu > Dataflow and click on the name of this job to view the status of your job. This Dataflow pipeline will take approximately five minutes to start, complete the work, and then shutdown.
- When your Job Status is Succeeded in the Dataflow Job Status screen, navigate to BigQuery to check to see that your data has been populated.
- You should see the usa_names_transformed table under the lake dataset.
- Click on the table and navigate to the Preview tab to see examples of the usa_names_transformed data.
Note: If you don’t see the usa_names_transformed table, try refreshing the page or view the tables using the classic BigQuery UI.
Data enrichment
You will now build a Dataflow pipeline with a TextIO source and a BigQueryIO destination to ingest data into BigQuery. More specifically, you will:
- Ingest the files from Cloud Storage.
- Filter out the header row in the files.
- Convert the lines read to dictionary objects.
- Output the rows to BigQuery.
Review data enrichment pipeline ython code
- In the Code Editor, open data_enrichment.py file.
- Check out the comments which explain what the code is doing. This code will populate the data in BigQuery.
Line 83 currently looks like:
values = [x.decode('utf8') for x in csv_row]3 . Edit it to look like the following:
values = [x for x in csv_row]
4 . When you have finished editing this line, remember to Save this updated file by selecting the File pull down in the Editor and clicking on Save
Run the Data Enrichment Dataflow pipeline
Here you’ll run the Dataflow pipeline in the cloud.
- Run the following in the Cloud Shell to spin up the workers required, and shut them down when complete:
python dataflow_python_examples/data_enrichment.py \
--project=$PROJECT \
--region= \
--runner=DataflowRunner \
--machine_type=e2-standard-2 \
--staging_location=gs://$PROJECT/test \
--temp_location gs://$PROJECT/test \
--input gs://$PROJECT/data_files/head_usa_names.csv \
--save_main_session
2 . Navigate to Navigation menu > Dataflow to view the status of your job. This Dataflow pipeline will take approximately five minutes to start, complete the work, and then shutdown.
3 . Once your Job Status is Succeed in the Dataflow Job Status screen, navigate to BigQuery to check to see that your data has been populated.
You should see the usa_names_enriched table under the lake dataset.
4 . Click on the table and navigate to the Preview tab to see examples of the usa_names_enriched data.
Note: If you don’t see the usa_names_enriched table, try refreshing the page or view the tables using the classic BigQuery UI.
Data lake to Mart and Review pipeline python code
Now build a Dataflow pipeline that reads data from two BigQuery data sources, and then joins the data sources. Specifically, you:
- Ingest files from two BigQuery sources.
- Join the two data sources.
- Filter out the header row in the files.
- Convert the lines read to dictionary objects.
- Output the rows to BigQuery.
In the Code Editor, open data_lake_to_mart.py file. Read through the comments in the file which explain what the code is doing. This code will join two tables and populate the resulting data in BigQuery.
Run the Apache Beam Pipeline to perform the Data Join and create the resulting table in BigQuery
Now run the Dataflow pipeline in the cloud.
- Run the following code block, in the Cloud Shell, to spin up the workers required, and shut them down when complete:
python dataflow_python_examples/data_lake_to_mart.py \
--worker_disk_type="compute.googleapis.com/projects//zones//diskTypes/pd-ssd" \
--max_num_workers=4 \
--project=$PROJECT \
--runner=DataflowRunner \
--machine_type=e2-standard-2 \
--staging_location=gs://$PROJECT/test \
--temp_location gs://$PROJECT/test \
--save_main_session \
--region=
2 . Navigate to Navigation menu > Dataflow and click on the name of this new job to view the status. This Dataflow pipeline will take approximately five minutes to start, complete the work, and then shutdown.
3. Once your Job Status is Succeeded in the Dataflow Job Status screen, navigate to BigQuery to check to see that your data has been populated.
You should see the orders_denormalized_sideinput table under the lake dataset.
4 . Click on the table and navigate to the Preview section to see examples of orders_denormalized_sideinput data.
Note: If you don’t see the orders_denormalized_sideinput table, try refreshing the page or view the tables using the classic BigQuery UI.
Congratulations!
You executed Python code using Dataflow to ingest data into BigQuery and transform the data.
Conclusion
In this tutorial, we successfully demonstrated how to build and execute ETL (Extract, Transform, Load) pipelines on Google Cloud using Dataflow and BigQuery with Python. We covered the essential steps, from setting up the environment to running various Dataflow pipelines for data ingestion, transformation, enrichment, and joining datasets.
We started by enabling the Dataflow API and configuring our Google Cloud project. We created a Cloud Storage bucket to store our data files and a BigQuery dataset to hold our tables. We then built and ran Dataflow pipelines to perform data ingestion, transformation, and enrichment, showcasing the power and flexibility of Apache Beam for processing large datasets.
The hands-on approach provided practical insights into managing data pipelines, ensuring data quality, and optimizing performance using Google Cloud services. By following this guide, you should now have a solid foundation in using Dataflow and BigQuery for ETL processes, enabling you to build robust data pipelines for your projects.
This tutorial is a stepping stone to mastering data engineering on Google Cloud. Whether you’re working with real-time data streams or batch processing, Dataflow and BigQuery offer scalable and efficient solutions to meet your data processing needs. Happy coding!
If you have any questions, I will be happy to answer them in the comments section below!
And Don’t forget to share this with the world to help make it a better place. Maybe your click will change someone’s life
Don’t Miss my upcoming updates. Join me:
https://abhijeetas8660211.medium.com/subscribe
If you are interested how AI in Cloud working then read my another blog on Document AI on medium: — https://levelup.gitconnected.com/create-and-test-a-document-ai-processor-gcp-lab-0510e51a43da
Level Up Coding
Thanks for being a part of my journey! Before you go:
- 👏 Clap for the story and follow the author 👉
- 🔔 Don’t forget to subscribe to my Medium! 📬
ETL Processing on Google Cloud Using Dataflow and BigQuery (Python) was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Abhijeet Singh
Abhijeet Singh | Sciencx (2024-07-09T15:34:51+00:00) ETL Processing on Google Cloud Using Dataflow and BigQuery (Python). Retrieved from https://www.scien.cx/2024/07/09/etl-processing-on-google-cloud-using-dataflow-and-bigquery-python/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.