
This content originally appeared on HackerNoon and was authored by Misha Epikhin
In this article, I present a study comparing environments for Apache Kafka. The ultimate goal is to find the most effective setup and achieve the best price-performance ratio.
\ Our data platform provides managed services for building analytical platforms for large data sets, competing with other market solutions. To remain competitive, we regularly conduct internal research to identify and improve our strengths, ensuring better deals. This article showcases one such study. Currently, our platform supports AWS and GCP as cloud providers. Both offer multiple compute generations and two CPU architectures (x86 with Intel and AMD, and ARM). I compare these setups using various Java Virtual Machines (JVMs) to evaluate the performance of new versions on newer processors.
\ If you want a TL;DR: ARM rocks. Modern expensive architecture does not always mean “better”. You may jump straight to the results or proceed to find out more about the methodology and setup.
Methodology
I considered testing performance with our own service but wanted to compare it in different environments we haven’t supported yet. I wanted to check out new virtual machines, regions, and even other cloud providers. So, I started by implementing a toy project that uses baseline Kafka with different base container images. This way, I can run benchmark tools on specific hardware and measure performance.
\ I aim to test various configurations to identify the most interesting results. For that, I use the idea of the testing matrix to filter initial findings. I will analyze these findings in-depth using tools like perf and eBPF to refine performance further.
Testing cases
Let’s first describe the testing goals. I have a lot of experience with OpenJDK JVM, but today, there are many alternatives from Microsoft, Amazon, and other companies. Amazon Correto, for instance, includes extra features and patches optimized for AWS. Since most of our customers use AWS, I wanted to include Amazon Correto in the tests to see how these JVMs perform on that platform.
\ I picked these versions for the first comparison:
- OpenJDK 11 (for a retrospective comparison, though it’s outdated)
- OpenJDK 17 (the currently-in-use JVM)
- Amazon Coretto 11.0.22-amzn (an alternative retrospective comparison)
- Amazon Coretto 17.0.10-amzn (an alternative to our current version)
- Amazon Coretto 21.0.2-amzn (a newer LTS version that should be better)
\ Once the versions were defined, I prepared a few scripts to build Kafka images using Amazon Correto and OpenJDK.
Image settings
For the benchmarking tests, I changed Kafka settings to focus on specific performance metrics. I wanted to test different combinations of [JVM] x [instancetype] x [architecture] x [cloudprovider], so it was important to minimize the effects of network connectivity and disk performance. I did this by running containers with tmpfs for data storage:
\
podman run -ti \
--network=host \
--mount type=tmpfs,destination=/tmp \
kfbench:3.6.1-21.0.2-amzn-arm64
\ Naturally, this setup is not meant for production, but isolating the CPU and memory bottlenecks was necessary. The best way is to remove network and disk influences from the tests. Otherwise, those factors would skew the results.
\ I used the benchmark tool on the same instance to ensure minimal latency and higher reproducibility. I also tried tests without host-network configurations and with cgroup-isolated virtual networks, but these only added unnecessary latency and increased CPU usage for packet forwarding.
\ While tmpfs dynamically allocates memory and might cause fragmentation and latency, it was adequate for our test. I could have used ramdisk instead, which allocates memory statically and avoids these issues, but tmpfs was easier to implement and still delivered the insights we were after. For our purposes, it struck the right balance.
\ Additionally, I applied some extra Kafka settings to evict data from memory more frequently:
############################# Benchmark Options #############################
# https://kafka.apache.org/documentation/#brokerconfigs_log.segment.bytes
# Chaged from 1GB to 256MB to rotate files faster
log.segment.bytes = 268435456
# https://kafka.apache.org/documentation/#brokerconfigs_log.retention.bytes
# Changed from -1 (unlimited) to 1GB evict them because we run in tmpfs
log.retention.bytes = 1073741824
# Changed from 5 minutes (300000ms) to delete outdated data faster
log.retention.check.interval.ms=1000
# Evict all data after 15 seconds (default is -1 and log.retention.hours=168 which is ~7 days)
log.retention.ms=15000
# https://kafka.apache.org/documentation/#brokerconfigs_log.segment.delete.delay.ms
# Changed from 60 seconds delay to small value to prevent memory overflows
log.segment.delete.delay.ms = 0
\ Here’s a summary of the changes:
- Log retention time is set to 15 seconds to remove data faster, and Log retention size is limited to 1 GB to manage storage in tmpfs. Log segment size is also changed to 256 MB to rotate files faster
- The Retention check interval is reduced to 1 second to quickly delete old data
- The Segment delete delay is set to 0 to prevent memory issues
\ This configuration is not suitable for production use, but it’s important for our benchmark tests as it reduces the effects of irrelevant factors.
Instance types
At DoubleCloud, as of the time of writing this article, we support these major generations of compute resources:
- s1 family: m5a instances (with i1 representing m5 with Intel processors)
- s2 family: m6a instances (with i2 representing m6i with Intel processors)
- sg1 family: GCP n2-standard instances with AMD Rome processors
\ For Graviton processors, we support:
- g1 family: m6g instances (Graviton 2)
- g2 family: m7g instances (Graviton 3)
\ Additionally, I tested t2a instances on GCP as an alternative to Graviton on Ampere Altra. We don’t offer these to our customers due to AWS’s limited regional support, but I included them in the benchmarks to compare performance. These might be a good option if you are in one of the “right” regions.
Benchmark tool
For benchmarking, I developed a lightweight tool based on franz-go library and example. This tool efficiently saturates Kafka without itself becoming the bottleneck.
\ While librdkafka is known for its reliability and popularity, I avoided it due to potential issues with cgo.
Test
Kafka is well-known for its scalability, allowing topics to be divided into multiple partitions to efficiently distribute workloads horizontally across brokers. However, I concentrated on evaluating single-core performance for our specific focus on the performance-to-price ratio.
\ Therefore, the tests utilized topics with single partitions to utilize individual core capabilities fully.
\ Each test case included two types:
- Synchronous produce: waits for message acknowledgment, ideal for measuring low-latency environments where milliseconds matter, such as real-time applications
- Asynchronous produce: buffers messages and sends them in batches, typical for Kafka clients that balance near real-time needs with tolerable latency of 10-100 ms
\ I used 8 KB messages, larger than an average customer case, to fully saturate topic partition threads.
Results
I present a series of plots comparing different test cases using a synthetic efficiency metric to evaluate different architectures. This metric quantifies millions of rows we can ingest into the Kafka broker per cent, providing a straightforward evaluation of architectural cost-efficiency.
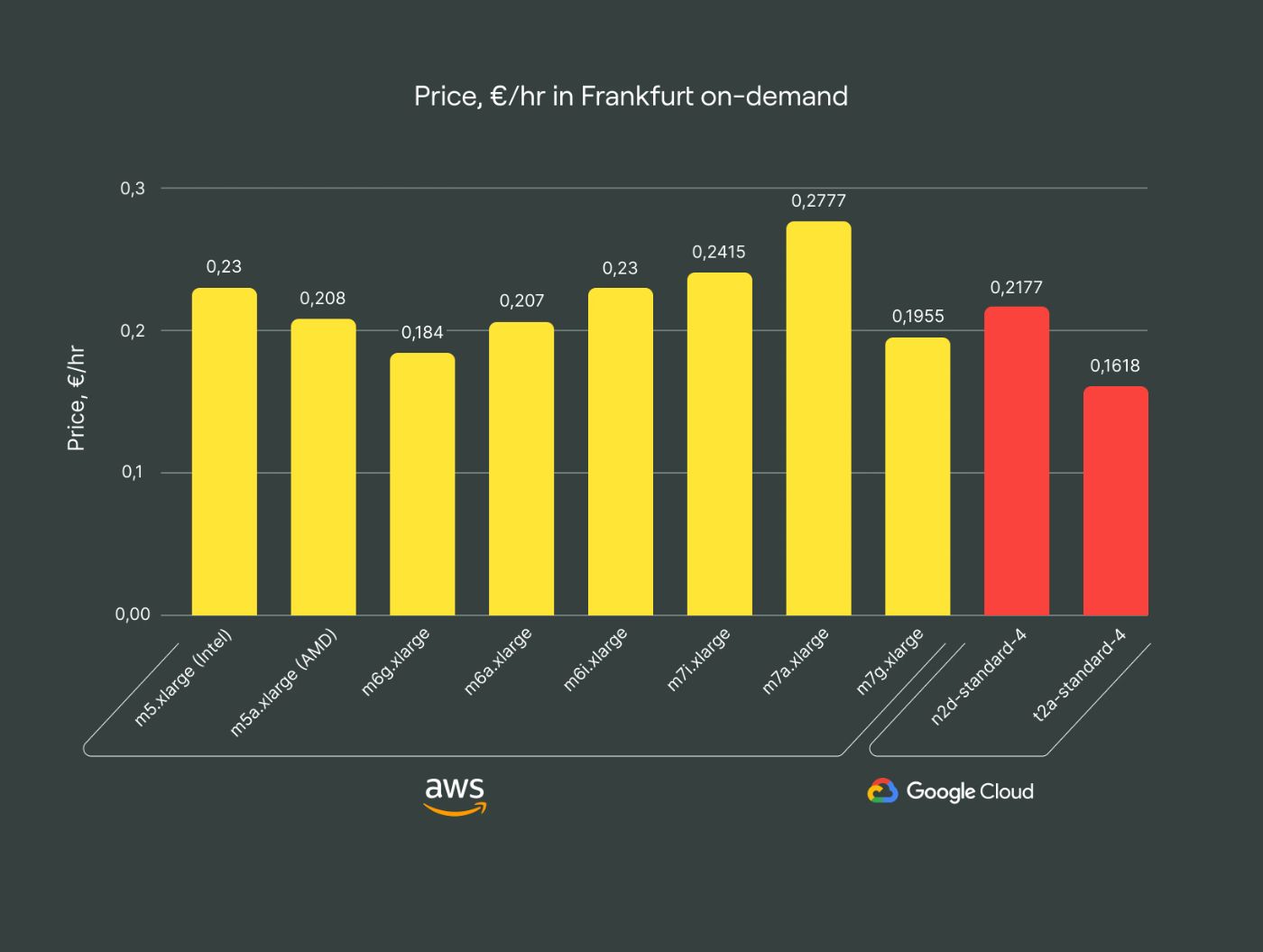
\ It’s important to acknowledge that actual results may vary due to cloud providers’ additional discounts. Whenever possible, the tests were conducted in Frankfurt for both cloud providers (or in the Netherlands in cases where instance-type options were restricted).
Charts
On all charts, I use conventional names for instances, the same their providers use. Instances are sorted first by cloud providers (AWS, then GCP) and then by generation: from older to newer.
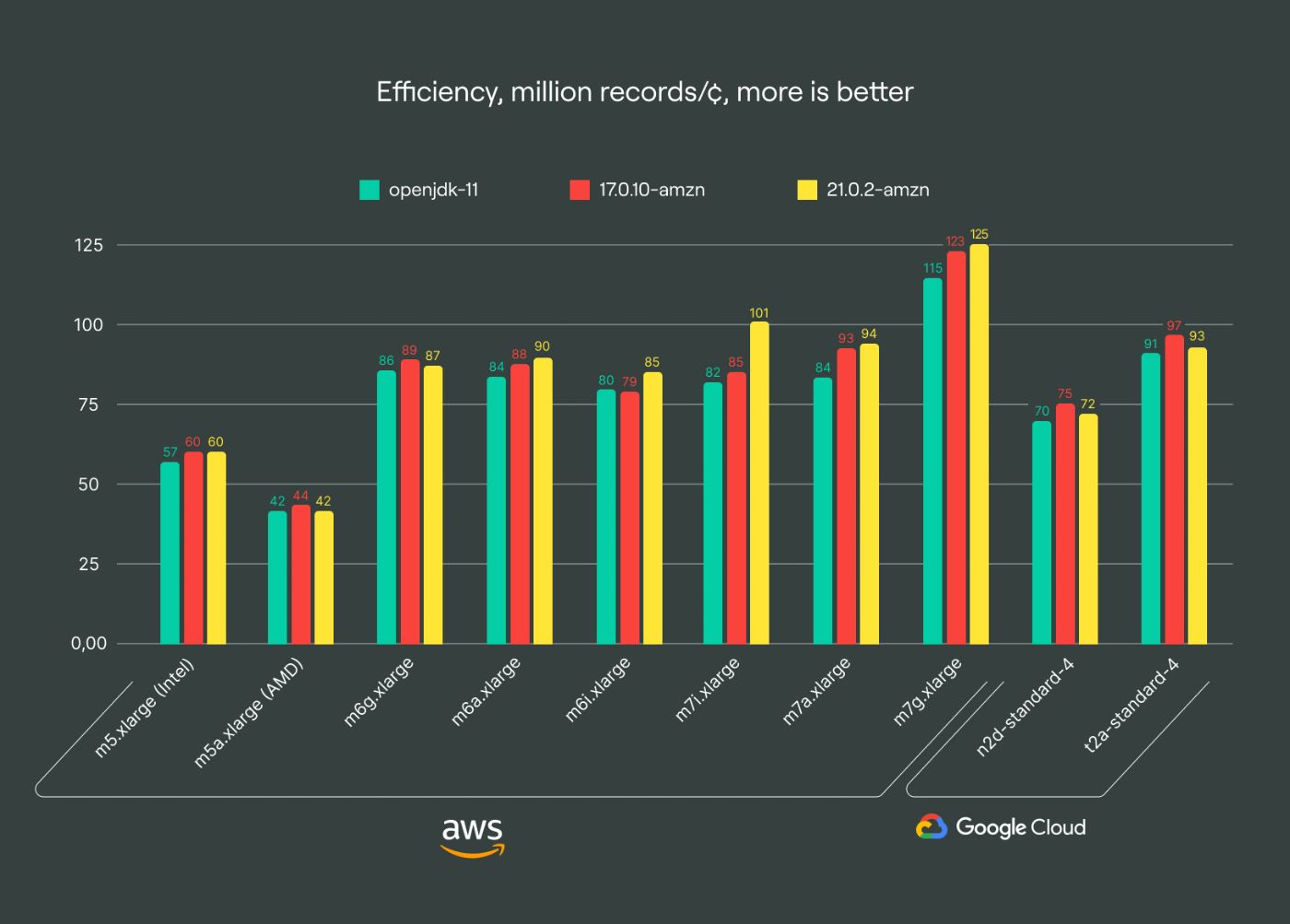
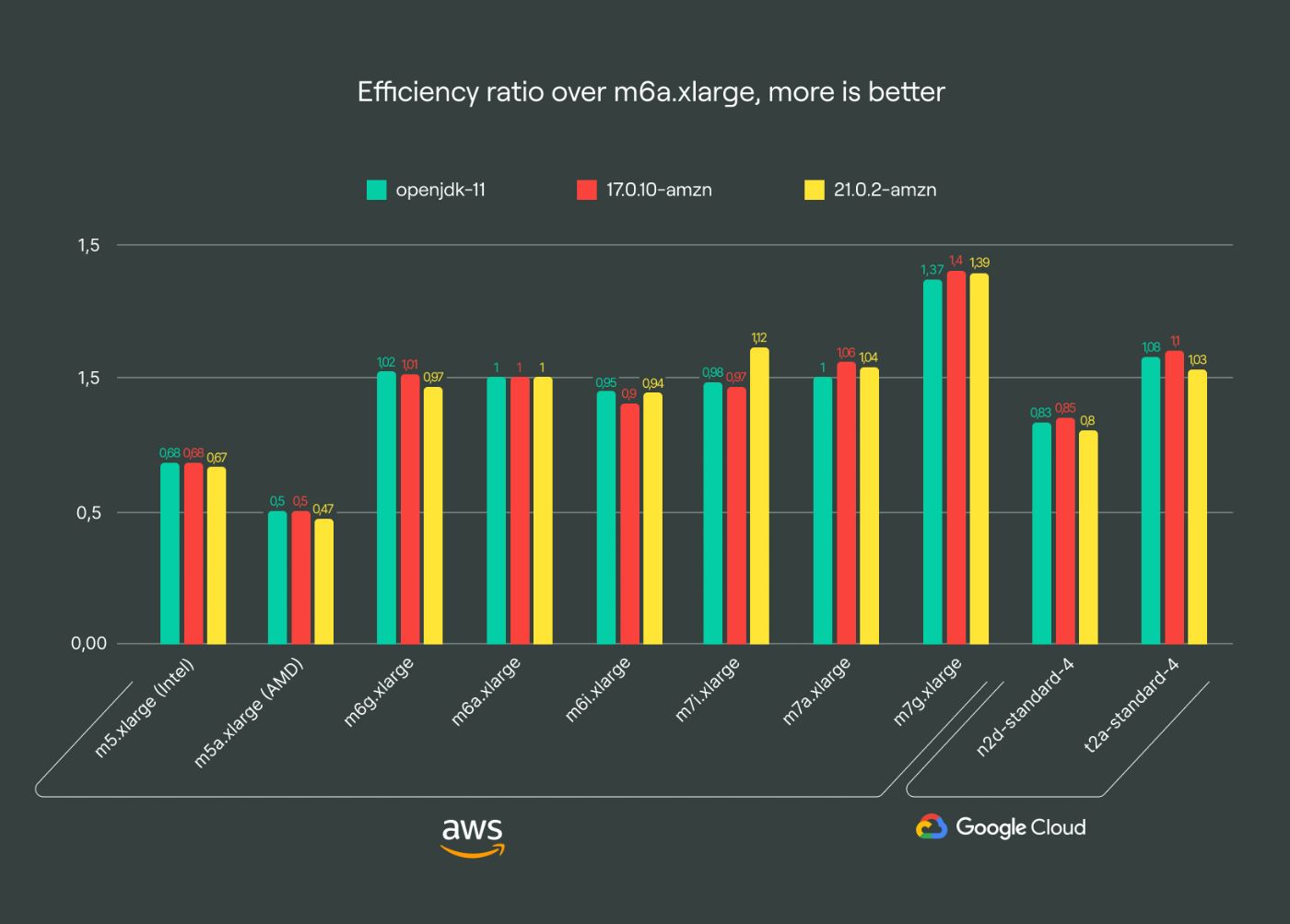
\ The full results, albeit in raw form, are available in my comprehensive benchmarking sheet. There, you can find more data than I present in this article, including latency and bandwidth numbers, and comparative performance of different JVMs.
AWS findings
s1 family: slowest performance
\ The “1st generation” s1 instances based on m5a-generation with AMD EPYC 7571, dating back to Q3 2019, are our legacy option. They’re the least efficient and slowest among our options in Frankfurt, costing approximately ~0.2080 €/hr on-demand. Transitioning to the newer s2 family, costing ~0.2070 €/hr, yields twice the efficiency for basically the same price. We encourage customers to migrate to these more cost-effective and performant options to enhance query times and ingestion speed for analytical applications.
g1 family: comparable efficiency to s2
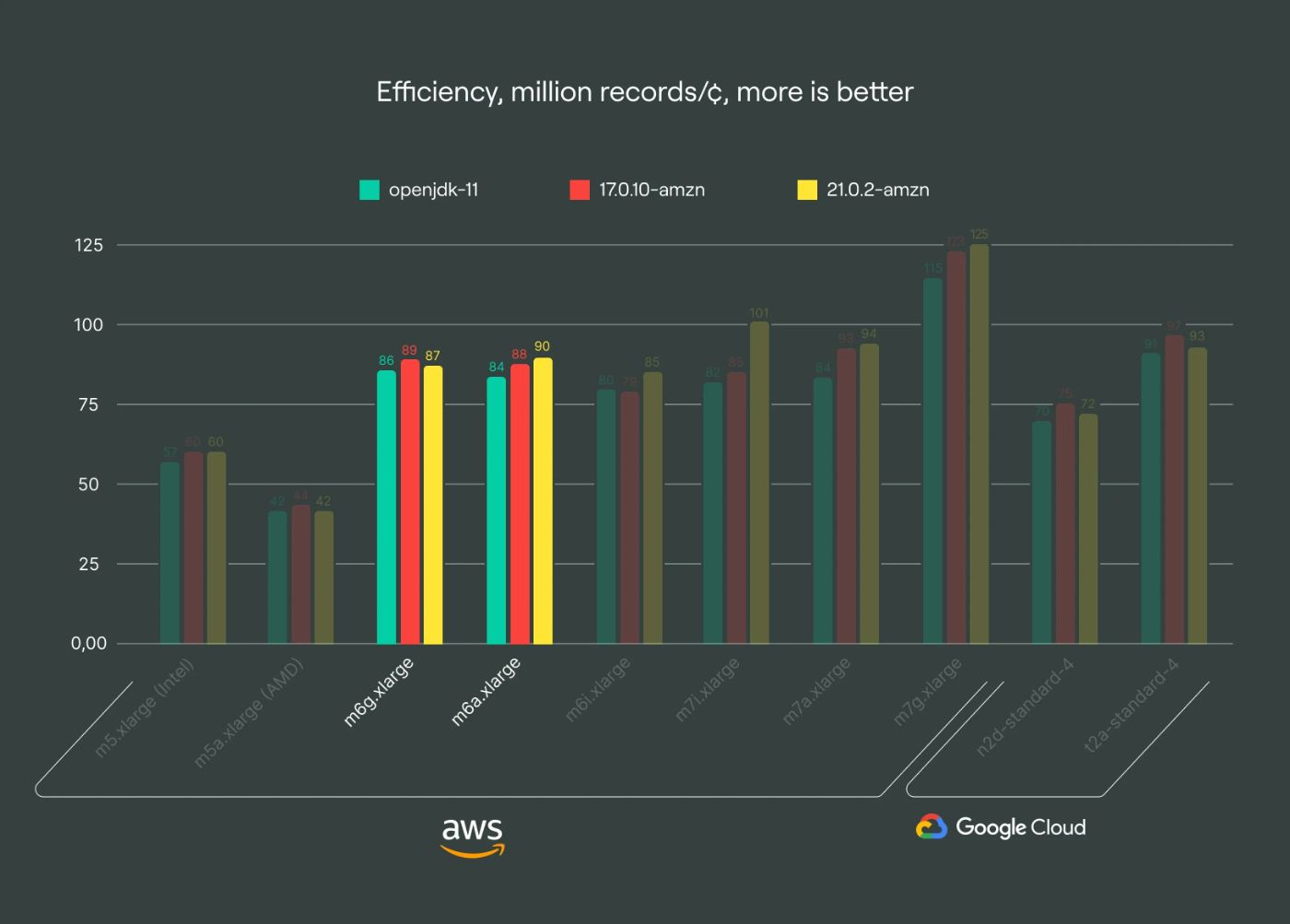
\ The g1 family is based on Graviton 2 and has historically provided good value, but the newer s2 family with AMD processors now matches its efficiency level for Apache Kafka. Despite offering slightly lower bandwidth and a marginal price advantage, the g1 family is now considered outdated compared to the newer options.
g2 family: superior efficiency
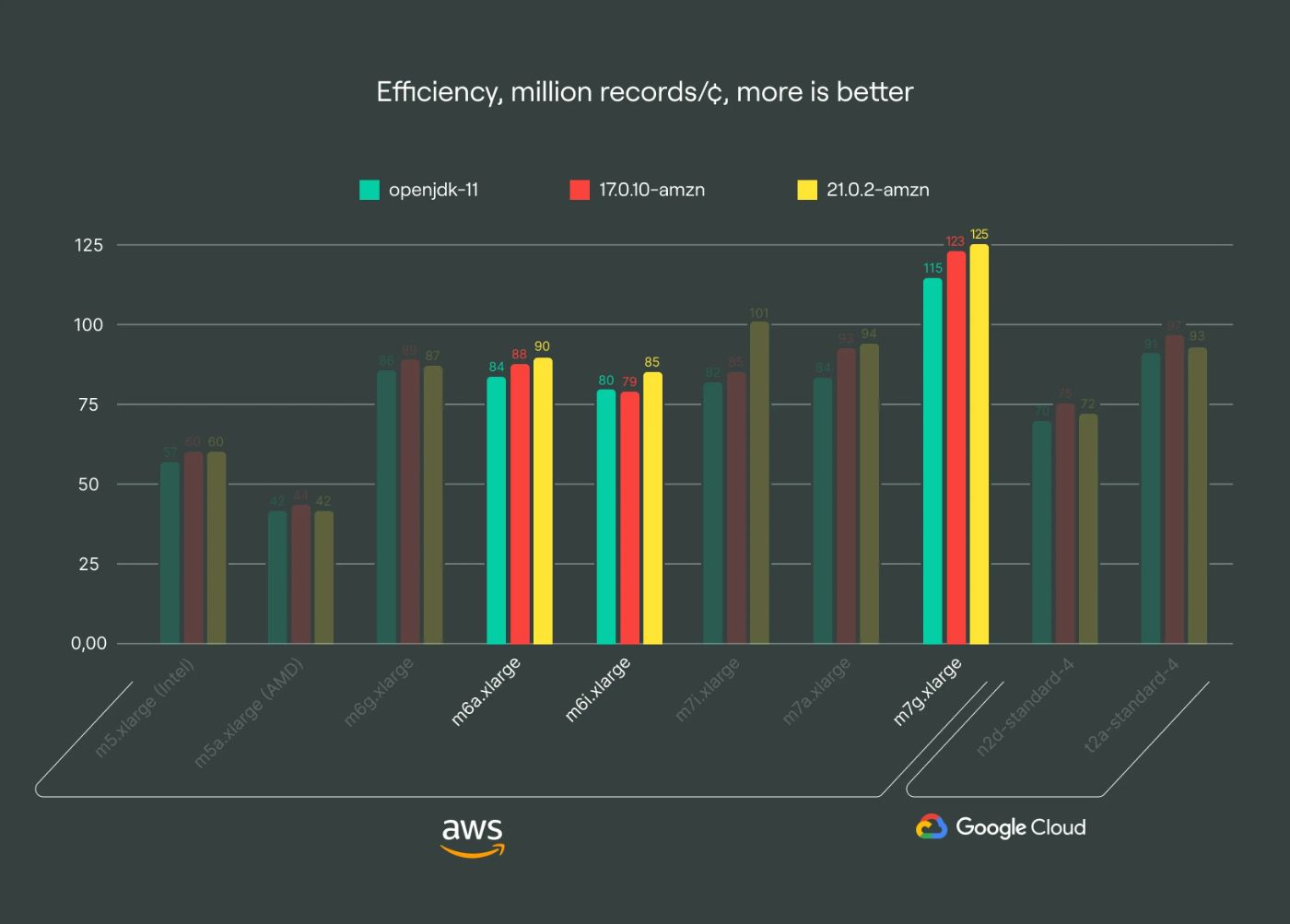
\ The g2 family, powered by Graviton 3, stands out as our top recommendation due to its superior efficiency. It outperforms the s2 and i2 families by up to 39% in certain scenarios, offering a cost-effective solution across nearly all regions, making it ideal for most Apache Kafka use cases. Given Kafka’s typical IO-bound nature, optimizing computational efficiency proves crucial for cost savings. I have observed a growing trend towards adopting arm64 architecture, with nearly half of our clusters already leveraging this newer tech.
x86_64 efficiency trends
The tests show that every new AMD or Intel processor improves in terms of overall throughput and latency. Despite that, the efficiency gains for the newer m6 and m7 generations have plateaued. Even the m7 generation, while potentially offering lower latency in some regions, falls short of the efficiency compared to the g2 family, according to our tests.
m7a family: leading latency performance
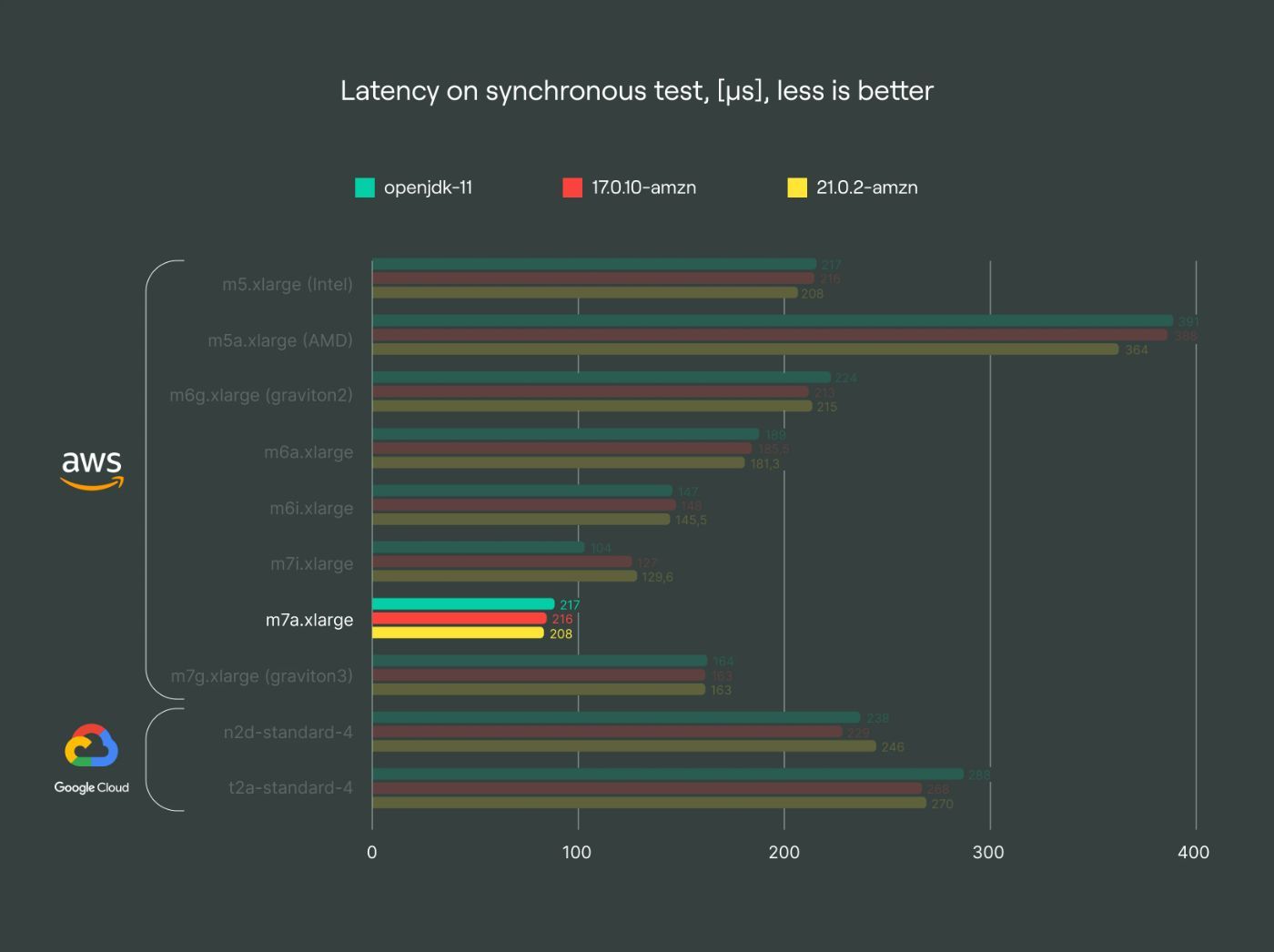
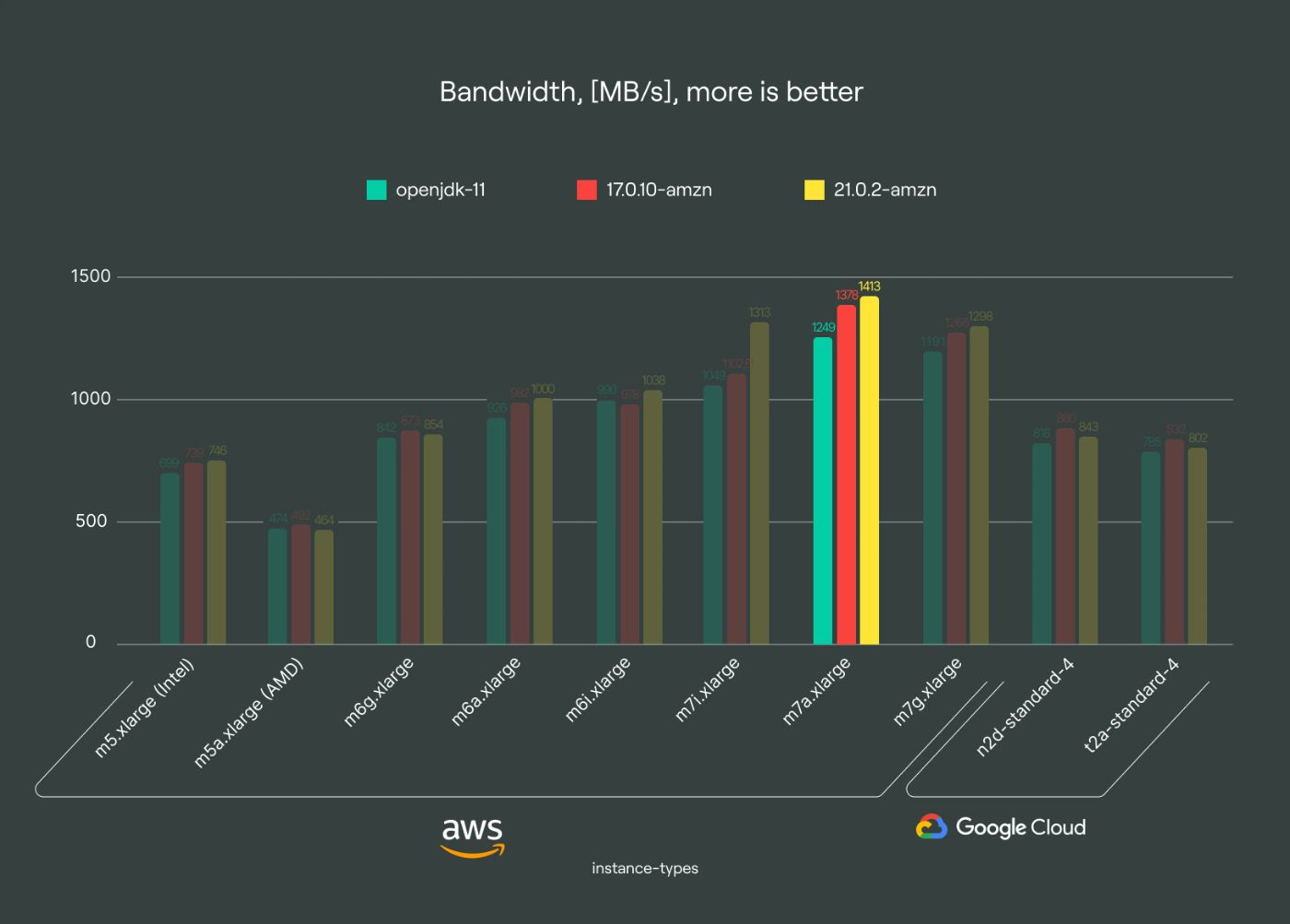
\ The m7a family excels in low-latency applications, surpassing both Intel and previous AMD generations in terms of throughput and latency. While not universally available, this architecture reflects AMD’s progress in enhancing performance. If accessible in your region, consider the m7a for superior results.
GCP findings
Efficiency comparison with AWS
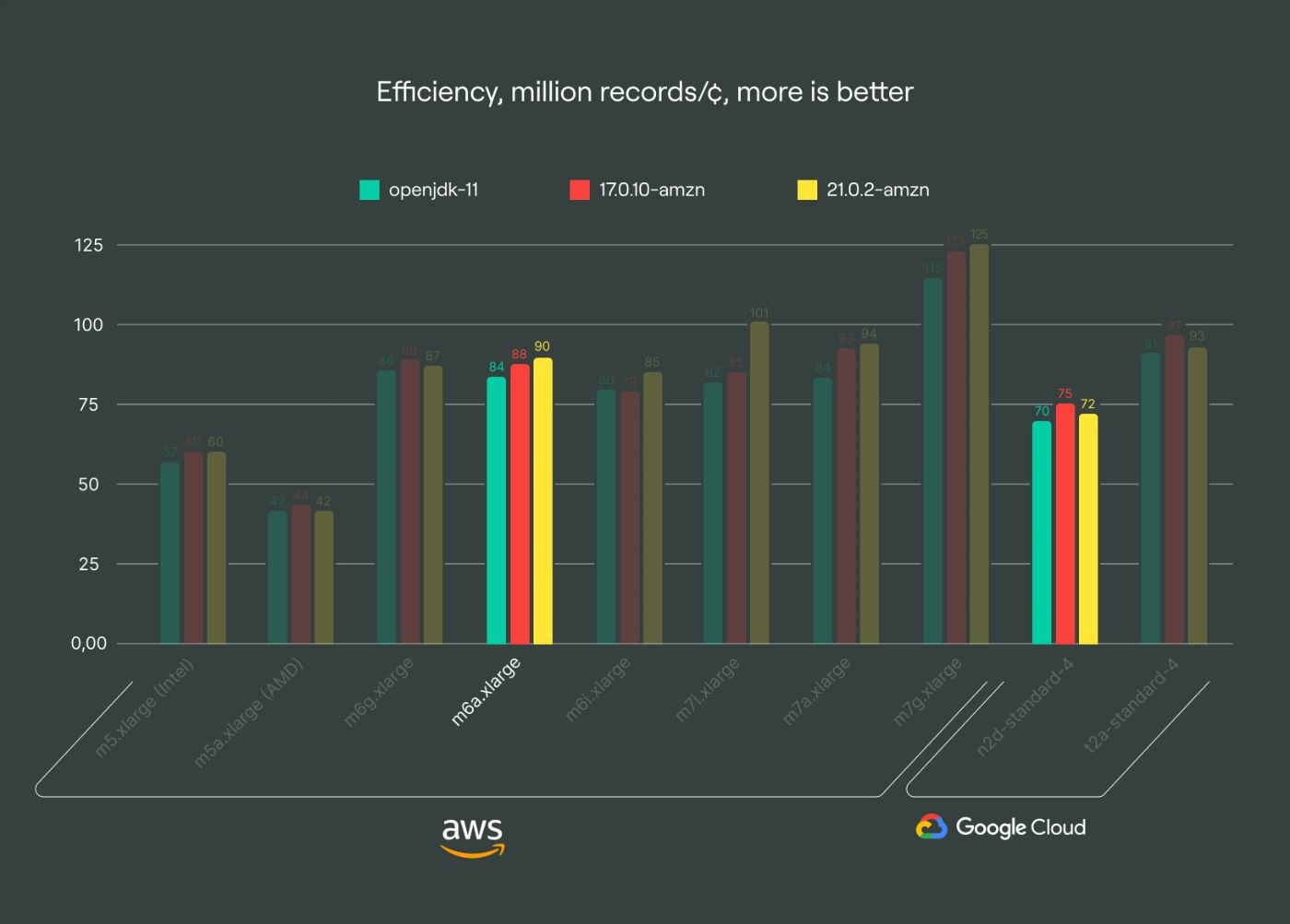
GCP instances generally have lower efficiency than their AWS alternatives. This was a great insight for me, as customers typically prefer GCP for its cost-effectiveness in analytical applications, resulting in lower bills. Our sg1 family utilizes the n2-standard generation, comparable to the AWS s2 family. However, my attempt to extend this comparison to other instance types was constrained by regional availability, especially for the c3 and n2 generations.
Arm Tau processors: cost-effectiveness
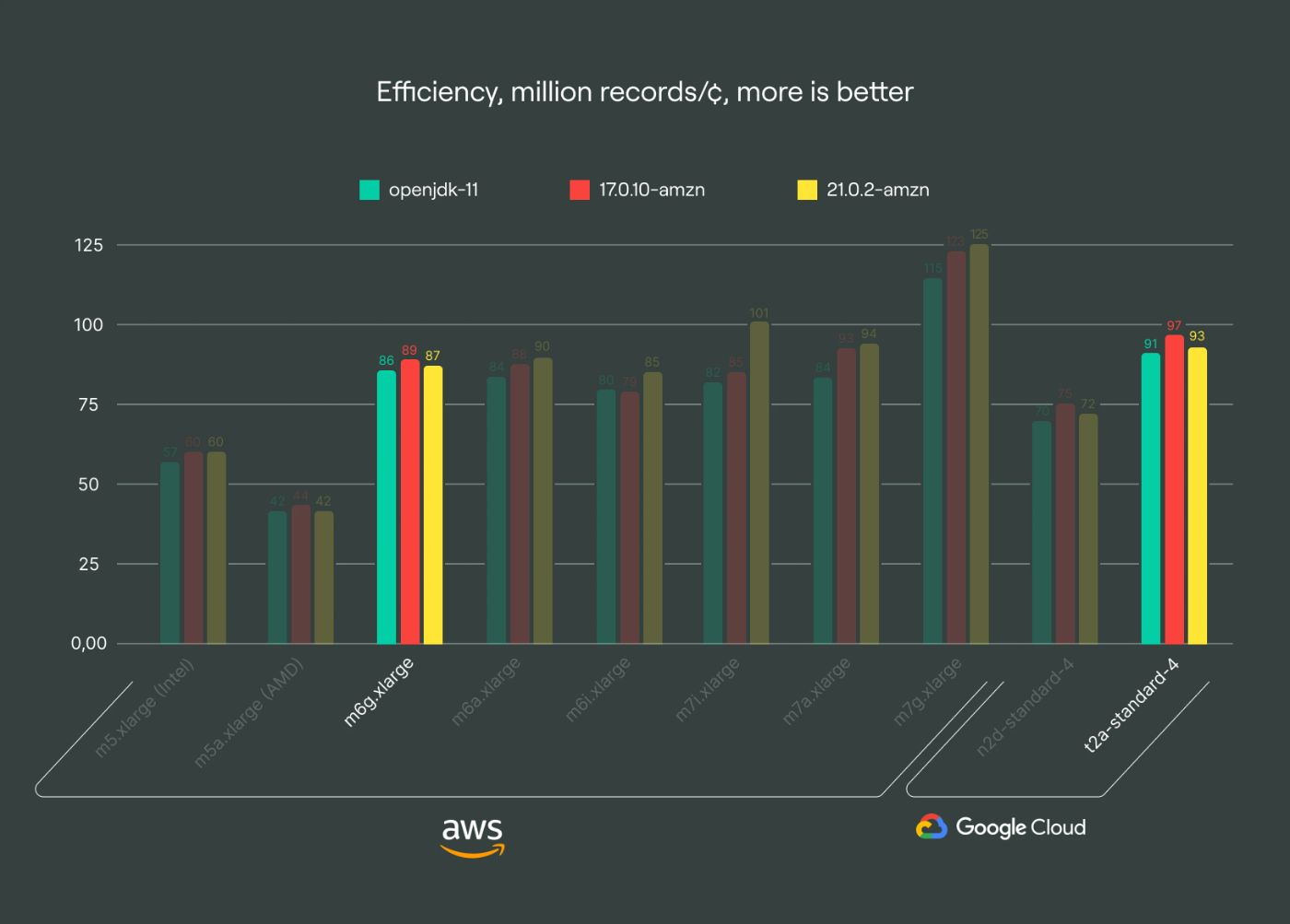
Arm instances using GCP’s Tau processors offer a 5-7% efficiency improvement over Graviton 2, making them a reasonable cost-saving option, if available in your region. Although GCP support for arm instances is limited to four regions, it provides comparable performance and efficiency to the g1 family.
Sustained use discounts
Since Apache Kafka clusters have constant usage of VM, leveraging Sustained Use Discounts allows for up to 20% discounts. This makes even older computational power, like Ampere Altra, competitive with Graviton 3 in terms of efficiency. Direct comparisons are tricky here, though, due to additional AWS discounts that may also apply.
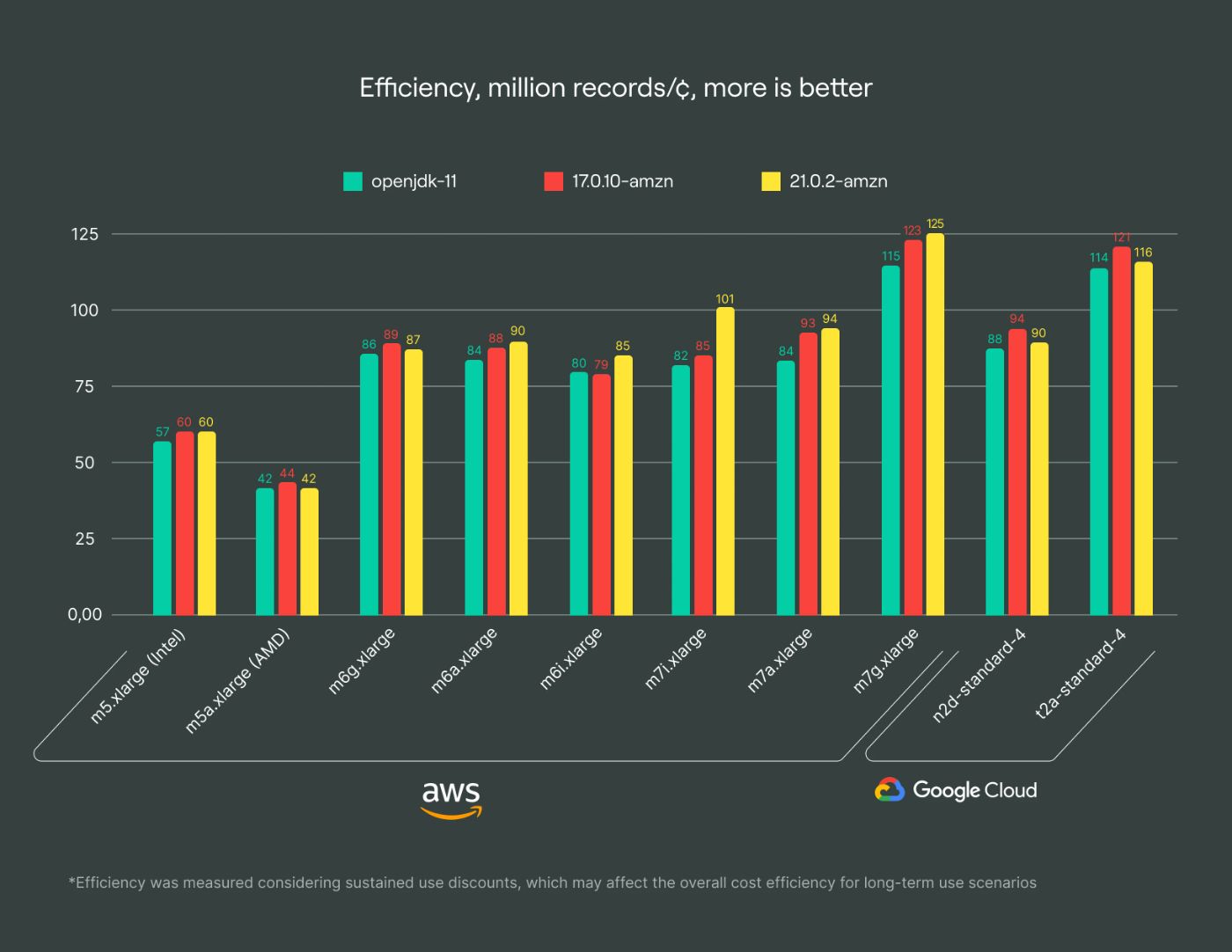
JVM insights
I thought I would see a significant improvement with newer JVM versions on ARM architecture. However, it looks like openjdk-11 and corretto-11 are already quite optimized for ARM. Since newer versions of Kafka require Java 17 and higher, I switched to Java 17, which resulted in approximately 4-8% performance gain in our benchmarks.
Additionally, 21.0.2-amzn seems promising, offering an extra 10-20% performance boost on newer instance types.
Conclusions
From time to time, I perform internal research to find optimal solutions for our production clusters and gather useful insights. The move towards ARM architecture is advantageous for managed services, as it saves money and reduces energy usage.
Relying on ARMs has already proved beneficial, improving performance and cost efficiency of both Managed Service for Apache Kafka and Managed Service for ClickHouse. This research helped refine our testing matrix, identifying the most efficient environments and areas for further optimization. We’re always on it: tweaking and refining under the hood, and I’m happy to share our knowledge with the community. Stay tuned!
This content originally appeared on HackerNoon and was authored by Misha Epikhin
Misha Epikhin | Sciencx (2024-07-12T19:43:42+00:00) Benchmarking Apache Kafka: Performance-per-price. Retrieved from https://www.scien.cx/2024/07/12/benchmarking-apache-kafka-performance-per-price-2/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.