
This content originally appeared on Level Up Coding - Medium and was authored by Shitanshu Bhushan

Continuing in our series of from-scratch implementations, in this article we will cover two famous ensemble algorithms: Random Forest and AdaBoost, but first,
What is Ensemble Learning anyway ???
The idea behind ensemble learning is to train multiple models (classifiers, etc.) and combine them to improve the prediction i.e., reduce bias or variance or both. They are considered meta-algorithms designed to work on top of existing learning algorithms. Some well-known examples of ensemble methods are:
- Bootstrapping
- Bagging (Bootstrap + aggregating)
- Boosting
- Stacking
All the above algorithms follow the basic idea that you have multiple models and then you combine them to make your final prediction, they differ in how they are combined and how each model is generated.
Random Forest (Bagging with a twist)
{kind=link}
In my previous article (Decision Trees: Branching Out Step by Step), we saw that overfitting is one major drawback of decision trees. Random Forest helps improve on that drawback and is basically an ensemble of decision trees with reduced correlation among trees.
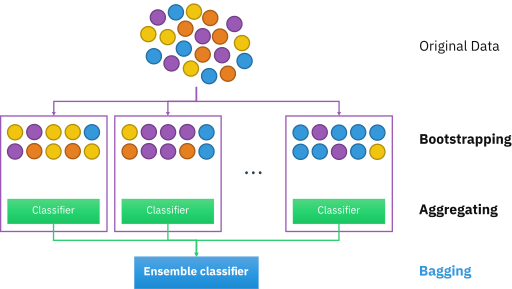
Random Forest is built on the concept of bagging or aggregate bootstrapping. The basic idea is that we draw multiple bootstrapped datasets from the original dataset, learn a classifier for each bootstrapped dataset and the final classifier is the majority vote of all the bootstrapped classifiers. Bagging is a parallel process as we can make all the bootstrapped classifiers in parallel. A key point to note here is that Bagging only reduces variance and not bias i.e., the bias of the bagging model will be equal to the bias of a single bootstrapped model.
Random Forest builds upon this idea of bagging by using only a subset of features at each node of each tree to decide the best split instead of using all the features. The intuition behind this can be thought of as let’s say we use all the features in all our nodes to make the splitting decision, our data could be such that even with bootstrapping we might end up with very similar trees as some features will always have higher information gain. So to be able to create a more diverse set of trees for aggregating, we only select a random subset of features at each node to make the decision, this helps us decorrelate the trees in our ensemble and helps the model in learning relationships it might never have learned through our greedy information gain approach.
So if we have a dataset D with n samples and we create M bootstrapped trees then the Random Forest algorithm can be written as:

Implementing Random Forest from scratch
Now that we have the algorithm as written above, let’s see what it looks like in code:
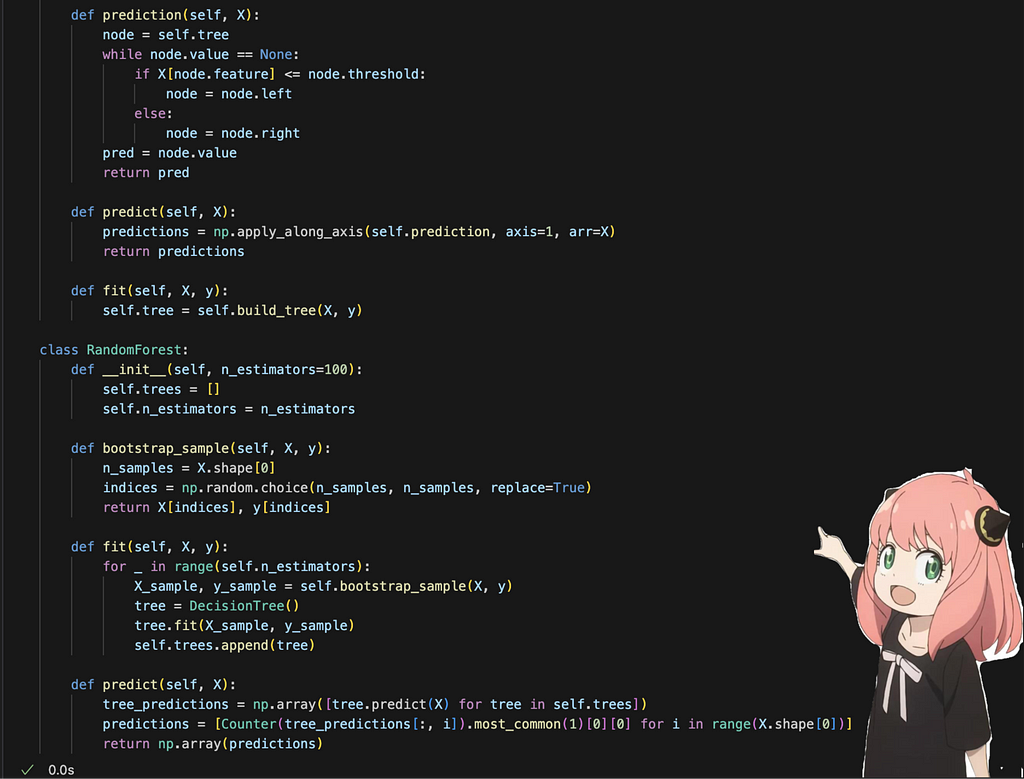
As we can see above, I just created a class called RandomForest which uses the Decision Tree classifier we implemented in the previous article. I then evaluated this against RandomForestClassifier from sklearn and got the same accuracy as them! So pretty good there!
AdaBoost (Adaptive Boosting)
{kind=link}
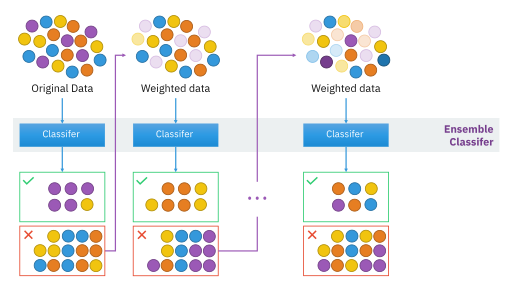
AdaBoost is built on the concept of boosting. Boosting is a way of effectively combining multiple weak learners to construct a strong learner. It is a sequential process of learning one model at a time and in each subsequent model we focus on the hard examples (ones getting misclassified). Compared to bagging, instead of sampling, we will re-weight the data for each successive model. Once we have trained all the models, we use a weighted vote of these weak models. So in simpler terms, we re-weight the data to give higher weights to misclassified samples, each model trained also has some weight assigned to them and the final output is a weighted vote.
Typically, we use weak classifiers in ensemble methods because strong classifiers can easily overfit the data. To prevent overfitting, we intentionally limit the complexity and expressiveness of each individual classifier.
So if we have a dataset D with N samples and we create M boosted trees then the AdaBoost algorithm for multiclass classification can be written as:

The above algorithm is called SAMME and is an adaptation of AdaBoost used for multiclass classification.
Implementing AdaBoost from scratch
Now that we have the algorithm as written above, let’s see what it looks like in code:
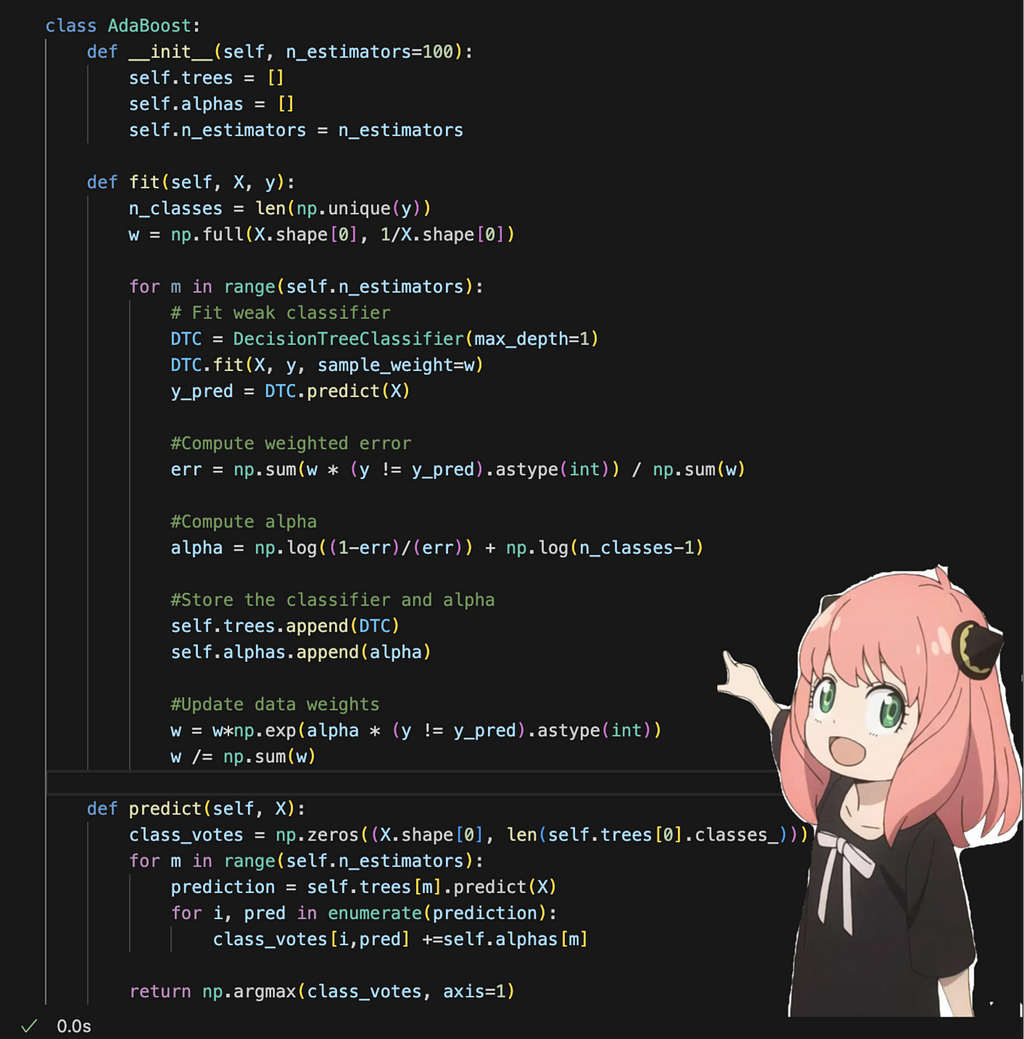
As demonstrated above, we use DecisionTreeClassifier from scikit-learn as our base model. Implementing the SAMME algorithm is straightforward and mirrors the steps outlined in the algorithm description. When I compared my implementation to the AdaBoostClassifier from scikit-learn, both achieved the same accuracy.
Summary
As we saw above, both Random Forest and AdaBoost are simple to understand and implement. While both algorithms effectively combine multiple weak models, they do so in different ways. Random Forest is a parallel process, creating multiple decision trees simultaneously, whereas AdaBoost is a sequential process, focusing on misclassified examples in each iteration. Random Forest is widely used for feature importance and selection, while AdaBoost (and newer boosting models like XGBoost and LightGBM) are particularly popular for tabular data, especially in Kaggle competitions.
All the code for this can be found at — Ensemble Methods from scratch
Random Forest & AdaBoost: Coding Ensemble Methods from Scratch was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Shitanshu Bhushan
Shitanshu Bhushan | Sciencx (2024-07-14T17:24:09+00:00) Random Forest & AdaBoost: Coding Ensemble Methods from Scratch. Retrieved from https://www.scien.cx/2024/07/14/random-forest-adaboost-coding-ensemble-methods-from-scratch/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.