
This content originally appeared on HackerNoon and was authored by Gamifications
:::info Authors:
(1) Omri Avrahami, Google Research and The Hebrew University of Jerusalem;
(2) Amir Hertz, Google Research;
(3) Yael Vinker, Google Research and Tel Aviv University;
(4) Moab Arar, Google Research and Tel Aviv University;
(5) Shlomi Fruchter, Google Research;
(6) Ohad Fried, Reichman University;
(7) Daniel Cohen-Or, Google Research and Tel Aviv University;
(8) Dani Lischinski, Google Research and The Hebrew University of Jerusalem.
:::
Table of Links
- Abstract and Introduction
- Related Work
- Method
- Experiments
- Limitations and Conclusions
- A. Additional Experiments
- B. Implementation Details
- C. Societal Impact
- References
4. Experiments
In Section 4.1 we compare our method against several baselines, both qualitatively and quantitatively. Next, in Section 4.2 we describe the user study we conducted and present its results. The results of an ablation study are reported in Section 4.3. Finally, in Section 4.4 we demonstrate several applications of our method.
4.1. Qualitative and Quantitative Comparison
We compared our method against the most related personalization techniques [20, 42, 71, 89, 93]. In each experiment, each of these techniques is used to extract a character from a single image, generated by SDXL [57] from an input prompt p. The same prompt p is also provided as input to our method. Textual Inversion (TI) [20] optimizes a textual token using several images of the same concept, and we converted it to support SDXL by learning two text tokens, one for each of its text encoders, as we did in our method. In addition, we used LoRA DreamBooth [71] (LoRA DB), which we found less prone to overfitting than standard DB. Furthermore, we compared against all available image encoder techniques that encode a single image into the textual space of the diffusion model for later generation in novel contexts: BLIP-Diffusion [42], ELITE [89], and IP-adapter [93]. For all the baselines, we used the same prompt p to generate a single image, and used it to extract the identity via optimization (TI and LoRA DB) or encoding (ELITE, BLIP-diffusion and IP-adapter).
\ In Figure 5 we qualitatively compare our method against the above baselines. While TI [20], BLIP-diffusion [42] and IP-adapter [93] are able to follow the specified prompt, they fail to produce a consistent character. LoRA DB [71] succeeds in consistent generation, but it does not always respond to the prompt. Furthermore, the resulting character is generated in the same fixed pose. ELITE [90] struggles with prompt following and the generated characters tend to be deformed. In comparison, our method is able to follow the prompt and maintain consistency, while generating appealing characters in different poses and viewing angles.
\ In order to automatically evaluate our method and the baselines quantitatively, we instructed ChatGPT [53] to generate prompts for characters of different types (e.g., animals, creatures, objects, etc.) in different styles (e.g., stickers, animations, photorealistic images, etc.). Each of these prompts was then used to extract a consistent character by our method and by each of the baselines. Next, we generated these characters in a predefined collection of novel contexts. For a visual comparison, please refer to the supplementary material.
\ We employ two standard evaluation metrics: prompt similarity and identity consistency, which are commonly used in the personalization literature [6, 20, 70]. Prompt similarity measures the correspondence between the generated images and the input text prompt. We use the standard CLIP [61] similarity, i.e., the normalized cosine similarity between the CLIP image embedding of the generated images and the CLIP text embedding of the source prompts. For measuring identity consistency, we calculate the similarity between the CLIP image embeddings of generated images of the same concept across different contexts.
\
![Figure 5. Qualitative comparison. We compare our method against several baselines: TI [20], BLIP-diffusion [42] and IP-adapter [93] are able to follow the target prompts, but do not preserve a consistent identity. LoRA DB [71] is able to maintain consistency, but it does not always follow the prompt. Furthermore, the character is generated in the same fixed pose. ELITE [90] struggles with prompt following and also tends to generate deformed characters. On the other hand, our method is able to follow the prompt and maintain consistent identities, while generating the characters in different poses and viewing angles.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-7k83z4c.png)
\
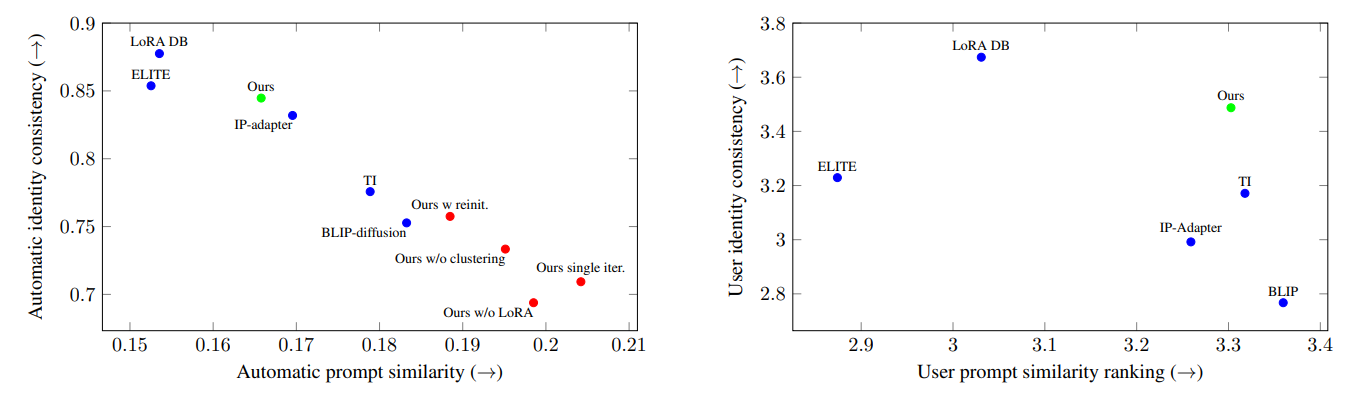
\ As can be seen in Figure 6 (left), there is an inherent trade-off between prompt similarity and identity consistency: LoRA DB and ELITE exhibit high identity consistency, while sacrificing prompt similarity. TI and BLIPdiffusion achieve high prompt similarity but low identity consistency. Our method and IP-adapter both lie on the Pareto front. However, our method achieves better identity consistency than IP-adapter, which is significant from the user’s perspective, as supported by our user study.
4.2. User Study
We conducted a user study to evaluate our method, using the Amazon Mechanical Turk (AMT) platform [2]. We used the same generated prompts and samples that were used in Section 4.1 and asked the evaluators to rate the prompt similarity and identity consistency of each result on a Likert scale of 1–5. For ranking the prompt similarity, the evaluators were presented with the target text prompt and the result of our method and the baselines on the same page, and were asked to rate each of the images. For identity consistency, for each of the generated concepts, we compared our method and the baselines by randomly choosing pairs of generated images with different target prompts, and the evaluators were asked to rate on a scale of 1–5 whether the images contain the same main character. Again, all the pairs of the same character for the different baselines were shown on the same page.
\ As can be seen in Figure 6 (right), our method again exhibits a good balance between identity consistency and prompt similarity, with a wider gap separating it from the baselines. For more details and statistical significance analbaselines. For more details and statistical significance analysis, read the supplementary material.
4.3. Ablation Study
We conducted an ablation study for the following cases: (1) Without clustering — we omit the clustering step described in Section 3.1, and instead simply generate 5 images according to the input prompt. (2) Without LoRA — we reduce the optimizable representation Θ in the identity extraction stage, as described in Section 3.2, to consist of only the newly-added text tokens without the additional LoRA weights. (3) With re-initialization — instead of using the latest representation Θ in each of the optimization iterations, as described in Section 3.3, we re-initialize it in each iteration. (4) Single iteration — rather than iterating until convergence (Section 3.3), we stop after a single iteration.
\ As can be seen in Figure 6 (left), all of the above key components are crucial for achieving a consistent identity in the final result: (1) removing the clustering harms the identity extraction stage because the training set is too diverse, (2) reducing the representation causes underfitting, as the model does not have enough parameters to properly capture the identity, (3) re-initializing the representation in each iteration, or (4) performing a single iteration, does not allow the model to converge into a single identity.
\ For a visual comparison of the ablation study, as well as comparison of alternative feature extractors (DINOv1 [14] and CLIP [61]), please refer to the supplementary material.
4.4. Applications
As demonstrated in Figure 7, our method can be used for various down-stream tasks, such as (a) Illustrating a story by breaking it into a different scenes and using the same consistent character for all of them. (b) Local text-driven image editing by integrating Blended Latent Diffusion [5, 7] — a consistent character can be injected into a specified location of a provided background image, in a novel pose specified by a text prompt. (c) Generating a consistent character with an additional pose control using ControlNet [97]. For more details, please refer to the supplementary material.
\
![Figure 7. Applications. Our method can be used for various applications: (a) Illustrating a full story with the same consistentcharacter. (b) Local text-driven image editing via integration with Blended Latent Diffusion [5, 7]. (c) Generating a consistent character with an additional pose control via integration with ControlNet [97].](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-v5a3zvb.png)
\
:::info This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.
:::
\
This content originally appeared on HackerNoon and was authored by Gamifications
Gamifications | Sciencx (2024-07-18T12:00:17+00:00) The Chosen One: Consistent Characters in Text-to-Image Diffusion Models: Experiments. Retrieved from https://www.scien.cx/2024/07/18/the-chosen-one-consistent-characters-in-text-to-image-diffusion-models-experiments/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.