
This content originally appeared on HackerNoon and was authored by Gamifications
:::info Authors:
(1) Omri Avrahami, Google Research and The Hebrew University of Jerusalem;
(2) Amir Hertz, Google Research;
(3) Yael Vinker, Google Research and Tel Aviv University;
(4) Moab Arar, Google Research and Tel Aviv University;
(5) Shlomi Fruchter, Google Research;
(6) Ohad Fried, Reichman University;
(7) Daniel Cohen-Or, Google Research and Tel Aviv University;
(8) Dani Lischinski, Google Research and The Hebrew University of Jerusalem.
:::
Table of Links
- Abstract and Introduction
- Related Work
- Method
- Experiments
- Limitations and Conclusions
- A. Additional Experiments
- B. Implementation Details
- C. Societal Impact
- References
C. Societal Impact
We believe that the emergence of technology that facilitates the effortless creation of consistent characters holds exciting promise in a variety of creative and practical applications. It can empower storytellers and content creators to bring their narratives to life with vivid and unique characters, enhancing the immersive quality of their work. In addition, it may offer accessibility to those who may not possess traditional artistic skills, democratizing character design in the creative industry. Furthermore, it can reduce the cost of advertising, and open up new opportunities for small and underprivileged entrepreneurs, enabling them to reach a wider audience and compete in the market more effectively.
\ On the other hand, as any other generative AI technology, it can be misused by creating false and misleading visual content for deceptive purposes. Creating fake characters or personas can be used for online scams, disinformation campaigns, etc., making it challenging to discern genuine information from fabricated content. Such technologies underscore the vital importance of developing generated content detection systems, making it a compelling research direction to address.
\

\

\
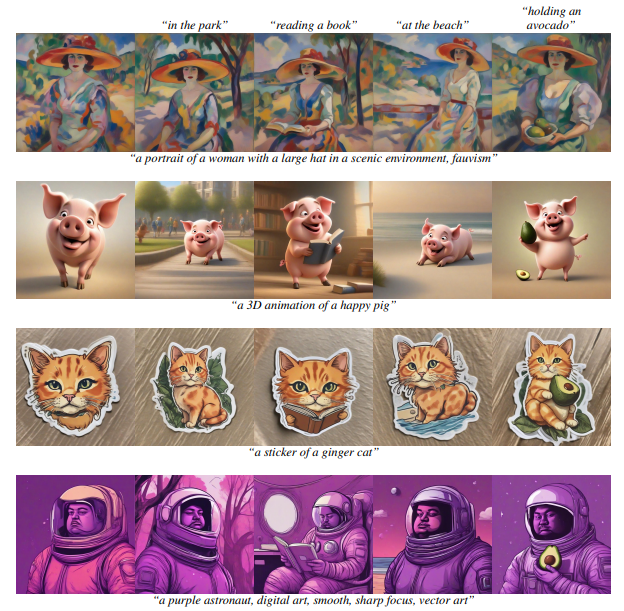
\

\

\

\
![Figure 18. Qualitative comparison to na¨ıve baselines. We tested two additional na¨ıve baselines against our method: TI [20] and LoRA DB [71] that were trained on a small dataset of 5 images generated from the same prompt. The baselines are referred to as TI multi (left column) and LoRA DB multi (middle column). As can be seen, both of these baselines fail to extract a consistent identity](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-56e3znj.png)
\
![Figure 19. Comparison to na¨ıve baselines. We tested two additional na¨ıve baselines against our method: TI [20] and LoRADB [71] that were trained on a small dataset of 5 images generated from the same prompt. The baselines are referred to as TI multi and LoRA DB multi. Our automatic testing procedure, described in Section 4.1, measures identity consistency and prompt similarity. As can be seen, both of these baselines fail to achieve high identity consistency.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-fuf3zs9.png)
\
![Figure 20. Comparison of feature extractors. We tested two additional feature extractors in our method: DINOv1 [14] and CLIP [61]. Our automatic testing procedure, described in Section 4.1, measures identity consistency and prompt similarity. As can be seen, DINOv1 produces higher identity consistency by sacrificing prompt similarity, while CLIP results in higher prompt similarity at the expense of lower identity consistency. In practice, however, the DINOv1 results are similar to those obtained with DINOv2 features in terms of prompt adherence (see Figure 21).](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-jtg3ztv.png)
\
![Figure 21. Comparison of feature extractors. We experimented with two additional feature extractors in our method: DINOv1 [14] and CLIP [61]. As can be seen, DINOv1 results are qualitatively similar to DINOv2, whereas CLIP produces results with a slightly lower identity consistency.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-qbh3z6n.png)
\

\
![Figure 23. Dataset non-memorization. We found the top 5 nearest neighbors in the LAION-5B dataset [73], in terms of CLIP [61] image similarity, for a few representative characters from our paper, using an open-source solution [68]. As can be seen, our method does not simply memorize images from the LAION-5B dataset.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-09j3zof.png)
\
![Figure 24. Our method using Stable Diffusion v2.1 backbone. We experimented with a version of our method that uses the Stable Diffusion v2.1 [69] model. As can be seen, our method can extract a consistent character, however, as expected, the results are of a lower quality than when using the SDXL [57] backbone that we use in the rest of this paper.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-g9k3ztf.png)
\
:::info This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.
:::
\
This content originally appeared on HackerNoon and was authored by Gamifications
Gamifications | Sciencx (2024-07-18T12:00:28+00:00) The Chosen One: Consistent Characters in Text-to-Image Diffusion Models: Societal Impact. Retrieved from https://www.scien.cx/2024/07/18/the-chosen-one-consistent-characters-in-text-to-image-diffusion-models-societal-impact/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.