
This content originally appeared on HackerNoon and was authored by Frank Z
\ To handle large datasets, distributed databases introduce strategies like partitioning and bucketing. Data is divided into smaller units based on specific rules and distributed across different nodes so databases can perform parallel processing for higher performance and data management flexibility.
\ Like in many databases, Apache Doris shards data into partitions, and then a partition is further divided into buckets. Partitions are typically defined by time or other continuous values. This allows query engines to quickly locate the target data during queries by pruning irrelevant data ranges.
\ Bucketing, on the other hand, distributes data based on the hash values of one or more columns, which prevents data skew.
\ Prior to version 2.1.0, there were two ways you could create data partitions in Apache Doris:
\
Manual Partition: Users specify the partitions in the table creation statement or modify them through DDL statements afterwards.
\
Dynamic Partition: The system automatically maintains partitions within a pre-defined range based on the data ingestion time.
\ In Apache Doris 2.1.0, we have introduced Auto Partition. It supports partitioning data by RANGE or by LIST and further enhances flexibility on top of automatic partitioning.
Evolution of partitioning strategies in Doris
In the design of data distribution, we focus more on partition planning because the choice of partition columns and partition intervals heavily depends on the actual data distribution patterns, and a good partition design can largely improve the query and storage efficiency of the table.
\ In Doris, the data table is divided into partitions and then buckets in a hierarchical manner. The data within the same bucket then forms a data tablet, which is the minimum physical storage unit in Doris for data replication, inter-cluster data scheduling, and load balancing.
\
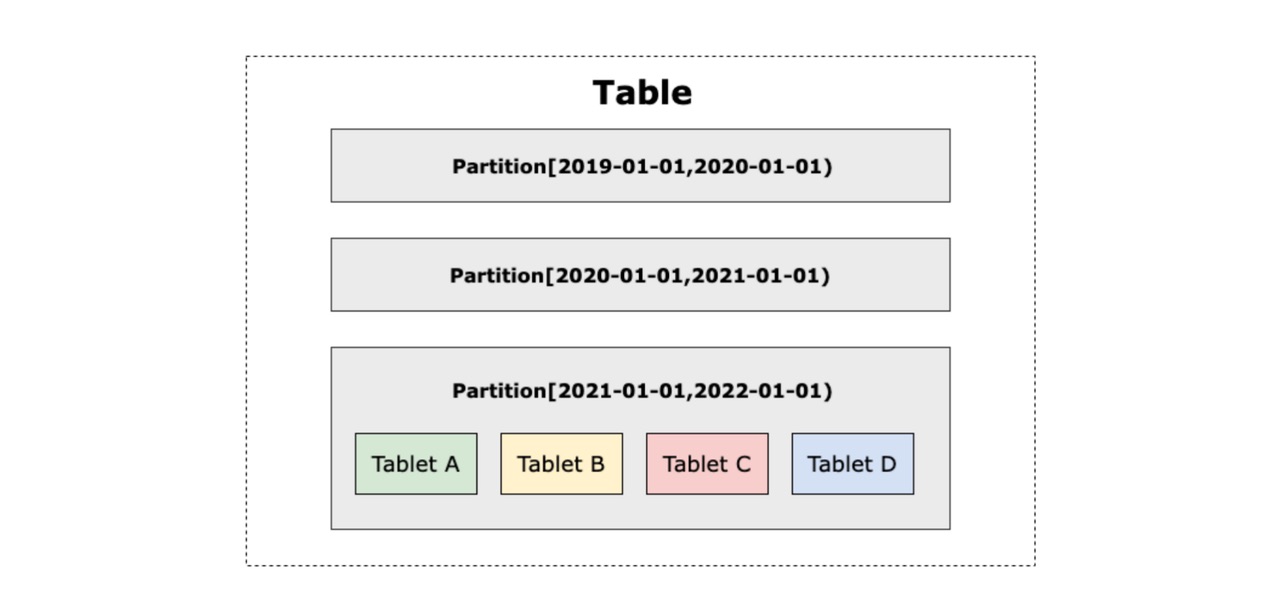
Manual Partition
Doris allows users to manually create data partitions by RANGE and by LIST.
\ For time-stamped data like logs and transaction records, users typically create partitions based on the time dimension. Here's an example of the CREATE TABLE statement:
\
CREATE TABLE IF NOT EXISTS example_range_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "User ID",
`date` DATE NOT NULL COMMENT "Data import date",
`timestamp` DATETIME NOT NULL COMMENT "Data import timestamp",
`city` VARCHAR(20) COMMENT "Location of user",
`age` SMALLINT COMMENT "Age of user",
`sex` TINYINT COMMENT "Sex of user",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "Last visit date of user",
`cost` BIGINT SUM DEFAULT "0" COMMENT "User consumption",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "Maximum dwell time of user",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "Minimum dwell time of user"
)
ENGINE=OLAP
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
PARTITION BY RANGE(`date`)
(
PARTITION `p201701` VALUES LESS THAN ("2017-02-01"),
PARTITION `p201702` VALUES LESS THAN ("2017-03-01"),
PARTITION `p201703` VALUES LESS THAN ("2017-04-01"),
PARTITION `p2018` VALUES [("2018-01-01"), ("2019-01-01"))
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
PROPERTIES
(
"replication_num" = "1"
);
\
The table is partitioned by the data import date date, and 4 partitions have been pre-created. Within each partition, the data is further divided into 16 buckets based on the hash value of the user_id.
\
With this partitioning and bucketing design, when querying data from 2018 onwards, the system only needs to scan the p2018 partition. This is what the query SQL looks like:
\
mysql> desc select count() from example_range_tbl where date >= '20180101';
+--------------------------------------------------------------------------------------+
| Explain String(Nereids Planner) |
+--------------------------------------------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS: |
| count(*)[#11] |
| PARTITION: UNPARTITIONED |
| |
| ...... |
| |
| 0:VOlapScanNode(193) |
| TABLE: test.example_range_tbl(example_range_tbl), PREAGGREGATION: OFF. |
| PREDICATES: (date[#1] >= '2018-01-01') |
| partitions=1/4 (p2018), tablets=16/16, tabletList=561490,561492,561494 ... |
| cardinality=0, avgRowSize=0.0, numNodes=1 |
| pushAggOp=NONE |
| |
+--------------------------------------------------------------------------------------+
\
If the data is distributed unevenly across partitions, the hash-based bucketing mechanism can further divide the data based on the user_id. This helps to avoid load imbalance on some machines during querying and storage.
\ However, in real-world business scenarios, one cluster may have tens of thousands of tables, which means it is impossible to manage them manually.
\
CREATE TABLE `DAILY_TRADE_VALUE`
(
`TRADE_DATE` datev2 NOT NULL COMMENT 'Trade date',
`TRADE_ID` varchar(40) NOT NULL COMMENT 'Trade ID',
......
)
UNIQUE KEY(`TRADE_DATE`, `TRADE_ID`)
PARTITION BY RANGE(`TRADE_DATE`)
(
PARTITION p_200001 VALUES [('2000-01-01'), ('2000-02-01')),
PARTITION p_200002 VALUES [('2000-02-01'), ('2000-03-01')),
PARTITION p_200003 VALUES [('2000-03-01'), ('2000-04-01')),
PARTITION p_200004 VALUES [('2000-04-01'), ('2000-05-01')),
PARTITION p_200005 VALUES [('2000-05-01'), ('2000-06-01')),
PARTITION p_200006 VALUES [('2000-06-01'), ('2000-07-01')),
PARTITION p_200007 VALUES [('2000-07-01'), ('2000-08-01')),
PARTITION p_200008 VALUES [('2000-08-01'), ('2000-09-01')),
PARTITION p_200009 VALUES [('2000-09-01'), ('2000-10-01')),
PARTITION p_200010 VALUES [('2000-10-01'), ('2000-11-01')),
PARTITION p_200011 VALUES [('2000-11-01'), ('2000-12-01')),
PARTITION p_200012 VALUES [('2000-12-01'), ('2001-01-01')),
PARTITION p_200101 VALUES [('2001-01-01'), ('2001-02-01')),
......
)
DISTRIBUTED BY HASH(`TRADE_DATE`) BUCKETS 10
PROPERTIES (
......
);
\ In the above example, data is partitioned on a monthly basis. This requires the database administrator (DBA) to manually add a new partition each month and maintain table schema regularly. Imagine the case of real-time data processing, where you might need to create partitions daily or even hourly, manually doing this is no long a choice. That's why we introduced Dynamic Partition.
Dynamic Partition
By Dynamic Partition, Doris automatically creates and reclaims data partitions as long as the user specifies the partition unit, the number of historical partitions, and the number of future partitions. This functionality relies on a fixed thread on the Doris Frontend. It continuously polls and checks for new partitions to be created or old partitions to be reclaimed, and updates the partition schema of the table.
\
This is an example CREATE TABLE statement for a table that is partitioned by day. The start and end parameters are set to -7 and 3, respectively, meaning that data partitions for the next 3 days will be pre-created, and the historical partitions that are older than 7 days will be reclaimed.
\
CREATE TABLE `DAILY_TRADE_VALUE`
(
`TRADE_DATE` datev2 NOT NULL COMMENT 'Trade date',
`TRADE_ID` varchar(40) NOT NULL COMMENT 'Trade ID',
......
)
UNIQUE KEY(`TRADE_DATE`, `TRADE_ID`)
PARTITION BY RANGE(`TRADE_DATE`) ()
DISTRIBUTED BY HASH(`TRADE_DATE`) BUCKETS 10
PROPERTIES (
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-7",
"dynamic_partition.end" = "3",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "10"
);
\
Over time, the table will always maintain partitions within the range of [current date - 7, current date + 3]. Dynamic Partition is particularly useful for real-time data ingestion scenarios, such as when the ODS (Operational Data Store) layer directly receives data from external sources like Kafka.
\
The start and end parameters define a fixed range for the partitions, allowing the user to manage the partitions only within this range. However, if the user needs to include more historical data, they would have to dial up the startvalue, and that could lead to unnecessary metadata overhead in the cluster.
\ Therefore, when applying Dynamic Partition, there is a trade-off between the convenience and efficiency of metadata management.
Developers' words
As the complexity of business adds up, Dynamic Partition becomes inadequate because:
\
- It only supports partitioning by RANGE but not by LIST.
- It can only be applied to the current real-world timestamps.
- It only supports a single continuous partition range and cannot accommodate partitions outside of that range.
\ Given these functional limitations, we started to plan a new partitioning mechanism that can both automate partition management and simplify data table maintenance.
\ We figured out that the ideal partitioning implementation should:
\
- Save the need for manually creating partitions after table creation;
- Be able to accommodate all ingested data in corresponding partitions.
\ The former stands for automation and the latter for flexibility. The essence of realizing them both is associating partition creation with the actual data.
\ Then we started to think about the following: What if we hold off on creating partitions until the data is ingested, rather than doing it during table creation or through regular polling? Instead of pre-constructing the partition distribution, we can define the "data-to-partition" mapping rules so that the partitions are created after data arrives.
\ Compared to Manual Partition, this whole process would be fully automated, eliminating the need for human maintenance. Compared to Dynamic Partition, it avoids having partitions that are not used or partitions that are needed but not present.
Auto Partition
With Apache Doris 2.1.0, we bring the above plan to fruition. During data ingestion, Doris creates data partitions based on the configured rules. The Doris Backend nodes that are responsible for data processing and distribution will attempt to find the appropriate partition for each row of data in the DataSink operator of the execution plan. It no longer filters out data that does not fit into any existing partition or reports an error for such a situation but automatically generates partitions for all ingested data.
Auto Partition by RANGE
Auto Partition by RANGE provides an optimized partitioning solution based on the time dimension. It is more flexible than Dynamic Partition in terms of parameter configuration. The syntax for it is as follows:
\
AUTO PARTITION BY RANGE (FUNC_CALL_EXPR)
()
FUNC_CALL_EXPR ::= DATE_TRUNC ( <partition_column>, '<interval>' )
\
The <partition_column> above is the partition column (i.e., the column that the partitioning is based on). <interval>specifies the partition unit, which is the desired width of each partition.
\
For example, if the partition column is k0 and you want to partition by month, the partition statement would be AUTO PARTITION BY RANGE (DATE_TRUNC(k0, 'month')). For all the imported data, the system will call DATE_TRUNC(k0, 'month') to calculate the left endpoint of the partition, and then the right endpoint by adding one interval.
\
Now, we can apply Auto Partition to the DAILY_TRADE_VALUE table introduced in the previous section on Dynamic Partition.
\
CREATE TABLE DAILY_TRADE_VALUE
(
`TRADE_DATE` DATEV2 NOT NULL COMMENT 'Trade Date',
`TRADE_ID` VARCHAR(40) NOT NULL COMMENT 'Trade ID',
......
)
AUTO PARTITION BY RANGE (DATE_TRUNC(`TRADE_DATE`, 'month'))
()
DISTRIBUTED BY HASH(`TRADE_DATE`) BUCKETS 10
PROPERTIES
(
......
);
\ After importing some data, these are the partitions we get:
\
mysql> show partitions from DAILY_TRADE_VALUE;
Empty set (0.10 sec)
mysql> insert into DAILY_TRADE_VALUE values ('2015-01-01', 1), ('2020-01-01', 2), ('2024-03-05', 10000), ('2024-03-06', 10001);
Query OK, 4 rows affected (0.24 sec)
{'label':'label_2a7353a3f991400e_ae731988fa2bc568', 'status':'VISIBLE', 'txnId':'85097'}
mysql> show partitions from DAILY_TRADE_VALUE;
+-------------+-----------------+----------------+---------------------+--------+--------------+--------------------------------------------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+
| PartitionId | PartitionName | VisibleVersion | VisibleVersionTime | State | PartitionKey | Range | DistributionKey | Buckets | ReplicationNum | StorageMedium | CooldownTime | RemoteStoragePolicy | LastConsistencyCheckTime | DataSize | IsInMemory | ReplicaAllocation | IsMutable | SyncWithBaseTables | UnsyncTables |
+-------------+-----------------+----------------+---------------------+--------+--------------+--------------------------------------------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+
| 588395 | p20150101000000 | 2 | 2024-06-01 19:02:40 | NORMAL | TRADE_DATE | [types: [DATEV2]; keys: [2015-01-01]; ..types: [DATEV2]; keys: [2015-02-01]; ) | TRADE_DATE | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL |
| 588437 | p20200101000000 | 2 | 2024-06-01 19:02:40 | NORMAL | TRADE_DATE | [types: [DATEV2]; keys: [2020-01-01]; ..types: [DATEV2]; keys: [2020-02-01]; ) | TRADE_DATE | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL |
| 588416 | p20240301000000 | 2 | 2024-06-01 19:02:40 | NORMAL | TRADE_DATE | [types: [DATEV2]; keys: [2024-03-01]; ..types: [DATEV2]; keys: [2024-04-01]; ) | TRADE_DATE | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL |
+-------------+-----------------+----------------+---------------------+--------+--------------+--------------------------------------------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+
3 rows in set (0.09 sec)
\ As is shown, partitions are automatically created for the imported data, and it doesn't create partitions that are beyond the range of the existing data.
Auto Partition by LIST
Auto Partition by LIST is to shard data based on non-time-based dimensions, such as region and department. It fills that gap for Dynamic Partition, which does not support data partitioning by LIST.
\ Auto Partition by RANGE provides an optimized partitioning solution based on the time dimension. It is more flexible than Dynamic Partition in terms of parameter configuration. The syntax for it is as follows:
\
AUTO PARTITION BY LIST (`partition_col`)
()
\
This is an example of Auto Partition by LIST using city as the partition column:
\
mysql> CREATE TABLE `str_table` (
-> `city` VARCHAR NOT NULL,
-> ......
-> )
-> DUPLICATE KEY(`city`)
-> AUTO PARTITION BY LIST (`city`)
-> ()
-> DISTRIBUTED BY HASH(`city`) BUCKETS 10
-> PROPERTIES (
-> ......
-> );
Query OK, 0 rows affected (0.09 sec)
mysql> insert into str_table values ("Denver"), ("Boston"), ("Los_Angeles");
Query OK, 3 rows affected (0.25 sec)
mysql> show partitions from str_table;
+-------------+-----------------+----------------+---------------------+--------+--------------+-------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+
| PartitionId | PartitionName | VisibleVersion | VisibleVersionTime | State | PartitionKey | Range | DistributionKey | Buckets | ReplicationNum | StorageMedium | CooldownTime | RemoteStoragePolicy | LastConsistencyCheckTime | DataSize | IsInMemory | ReplicaAllocation | IsMutable | SyncWithBaseTables | UnsyncTables |
+-------------+-----------------+----------------+---------------------+--------+--------------+-------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+
| 589685 | pDenver7 | 2 | 2024-06-01 20:12:37 | NORMAL | city | [types: [VARCHAR]; keys: [Denver]; ] | city | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL |
| 589643 | pLos5fAngeles11 | 2 | 2024-06-01 20:12:37 | NORMAL | city | [types: [VARCHAR]; keys: [Los_Angeles]; ] | city | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL |
| 589664 | pBoston8 | 2 | 2024-06-01 20:12:37 | NORMAL | city | [types: [VARCHAR]; keys: [Boston]; ] | city | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL |
+-------------+-----------------+----------------+---------------------+--------+--------------+-------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+
3 rows in set (0.10 sec)
\ After inserting data for the cities of Denver, Boston, and Los Angeles, the system automatically created corresponding partitions based on the city names. Previously, this type of custom partitioning could only be achieved through manual DDL statements. This is how Auto Partition by LIST simplifies database maintenance.
Tips & notes
Manually adjust historical partitions
For tables that receive both real-time data and occasional historical updates, since Auto Partition does not automatically reclaim historical partitions, we recommend two options:
\
Use Auto Partition, which will automatically create partitions for the occasional historical data updates.
Use Auto Partition and manually create a
LESS THANpartition to accommodate the historical updates. This allows for a clearer separation of historical and real-time data and makes data management easier.\
mysql> CREATE TABLE DAILY_TRADE_VALUE
-> (
-> `TRADE_DATE` DATEV2 NOT NULL COMMENT 'Trade Date',
-> `TRADE_ID` VARCHAR(40) NOT NULL COMMENT 'Trade ID'
-> )
-> AUTO PARTITION BY RANGE (DATE_TRUNC(`TRADE_DATE`, 'DAY'))
-> (
-> PARTITION `pHistory` VALUES LESS THAN ("2024-01-01")
-> )
-> DISTRIBUTED BY HASH(`TRADE_DATE`) BUCKETS 10
-> PROPERTIES
-> (
-> "replication_num" = "1"
-> );
Query OK, 0 rows affected (0.11 sec)
mysql> insert into DAILY_TRADE_VALUE values ('2015-01-01', 1), ('2020-01-01', 2), ('2024-03-05', 10000), ('2024-03-06', 10001);
Query OK, 4 rows affected (0.25 sec)
{'label':'label_96dc3d20c6974f4a_946bc1a674d24733', 'status':'VISIBLE', 'txnId':'85092'}
mysql> show partitions from DAILY_TRADE_VALUE;
+-------------+-----------------+----------------+---------------------+--------+--------------+--------------------------------------------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+
| PartitionId | PartitionName | VisibleVersion | VisibleVersionTime | State | PartitionKey | Range | DistributionKey | Buckets | ReplicationNum | StorageMedium | CooldownTime | RemoteStoragePolicy | LastConsistencyCheckTime | DataSize | IsInMemory | ReplicaAllocation | IsMutable | SyncWithBaseTables | UnsyncTables |
+-------------+-----------------+----------------+---------------------+--------+--------------+--------------------------------------------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+
| 577871 | pHistory | 2 | 2024-06-01 08:53:49 | NORMAL | TRADE_DATE | [types: [DATEV2]; keys: [0000-01-01]; ..types: [DATEV2]; keys: [2024-01-01]; ) | TRADE_DATE | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL |
| 577940 | p20240305000000 | 2 | 2024-06-01 08:53:49 | NORMAL | TRADE_DATE | [types: [DATEV2]; keys: [2024-03-05]; ..types: [DATEV2]; keys: [2024-03-06]; ) | TRADE_DATE | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL |
| 577919 | p20240306000000 | 2 | 2024-06-01 08:53:49 | NORMAL | TRADE_DATE | [types: [DATEV2]; keys: [2024-03-06]; ..types: [DATEV2]; keys: [2024-03-07]; ) | TRADE_DATE | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL |
+-------------+-----------------+----------------+---------------------+--------+--------------+--------------------------------------------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+
3 rows in set (0.10 sec)
\ NULL partition
With Auto Partition by LIST, Doris supports storing NULL values in NULL partitions. For example:
\
mysql> CREATE TABLE list_nullable
-> (
-> `str` varchar NULL
-> )
-> AUTO PARTITION BY LIST (`str`)
-> ()
-> DISTRIBUTED BY HASH(`str`) BUCKETS auto
-> PROPERTIES
-> (
-> "replication_num" = "1"
-> );
Query OK, 0 rows affected (0.10 sec)
mysql> insert into list_nullable values ('123'), (''), (NULL);
Query OK, 3 rows affected (0.24 sec)
{'label':'label_f5489769c2f04f0d_bfb65510f9737fff', 'status':'VISIBLE', 'txnId':'85089'}
mysql> show partitions from list_nullable;
+-------------+---------------+----------------+---------------------+--------+--------------+------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+
| PartitionId | PartitionName | VisibleVersion | VisibleVersionTime | State | PartitionKey | Range | DistributionKey | Buckets | ReplicationNum | StorageMedium | CooldownTime | RemoteStoragePolicy | LastConsistencyCheckTime | DataSize | IsInMemory | ReplicaAllocation | IsMutable | SyncWithBaseTables | UnsyncTables |
+-------------+---------------+----------------+---------------------+--------+--------------+------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+
| 577297 | pX | 2 | 2024-06-01 08:19:21 | NORMAL | str | [types: [VARCHAR]; keys: [NULL]; ] | str | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL |
| 577276 | p0 | 2 | 2024-06-01 08:19:21 | NORMAL | str | [types: [VARCHAR]; keys: []; ] | str | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL |
| 577255 | p1233 | 2 | 2024-06-01 08:19:21 | NORMAL | str | [types: [VARCHAR]; keys: [123]; ] | str | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL |
+-------------+---------------+----------------+---------------------+--------+--------------+------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+
3 rows in set (0.11 sec)
\
However, Auto Partition by RANGE does not support NULL partitions, because the NULL values will be stored in the smallest LESS THAN partition, and it is impossible to reliably determine the appropriate range for it. If Auto Partition were to create a NULL partition with a range of (-INFINITY, MINVALUE), there would be a risk of this partition being inadvertently deleted in production, as the MINVALUE boundary may not accurately represent the intended business logic.
Summary
Auto Partition covers most of the use cases of Dynamic Partition, while introducing the benefit of upfront partition rule definition. Once the rules are defined, the bulk of partition creation work is automatically handled by Doris instead of a DBA.
\ Before utilizing Auto Partition, it's important to understand the relevant limitations:
\
Auto Partition by LIST supports partitioning based on multiple columns, but each automatically created partition only contains one single value, and the partition name cannot exceed 50 characters in length. Note that the partition names follow specific naming conventions, which have particular implications for metadata management. That means not all of the 50-character space is at the user's disposal.
\
Auto Partition by RANGE only supports a single partition column, which must be of type DATE or DATETIME.
\
Auto Partition by LIST supports NULLABLE partition column and inserting NULL values. Auto Partition by RANGE does not support NULLABLE partition column.
\
It is not recommended to use Auto Partition in conjunction with Dynamic Partition after Apache Doris 2.1.3.
Performance comparison
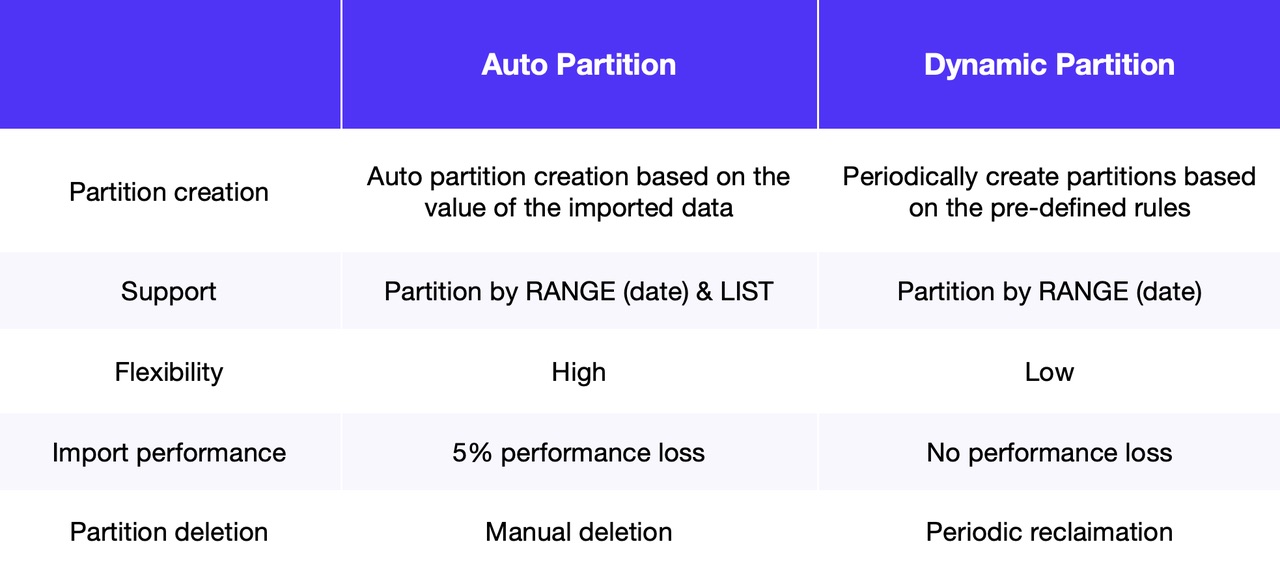
The main functional differences between Auto Partition and Dynamic Partition lie in partition creation and deletion, supported partition types, and their impact on import performance.
\ Dynamic Partition uses fixed threads to periodically create and reclaim partitions. It only supports partitioning by RANGE. In contrast, Auto Partition supports both partitioning by RANGE and by LIST. It automatically creates partitions on-demand based on specific rules during data ingestion, providing a higher level of automation and flexibility.
\ Dynamic Partition does not slow down data ingestion speed, while Auto Partition causes certain time overheads because it firstly checks for existing partitions and then creates new ones on demand. We will present the performance test results.
\
\
Auto Partition: ingestion workflow
This part is about how data ingestion is implemented with the Auto Partition mechanism, and we use Stream Load as an example. When Doris initiates a data import, one of the Doris Backend nodes takes on the role of the Coordinator. It is responsible for the initial data processing work and then dispatching the data to the appropriate BE nodes, known as the Executors, for execution.
\
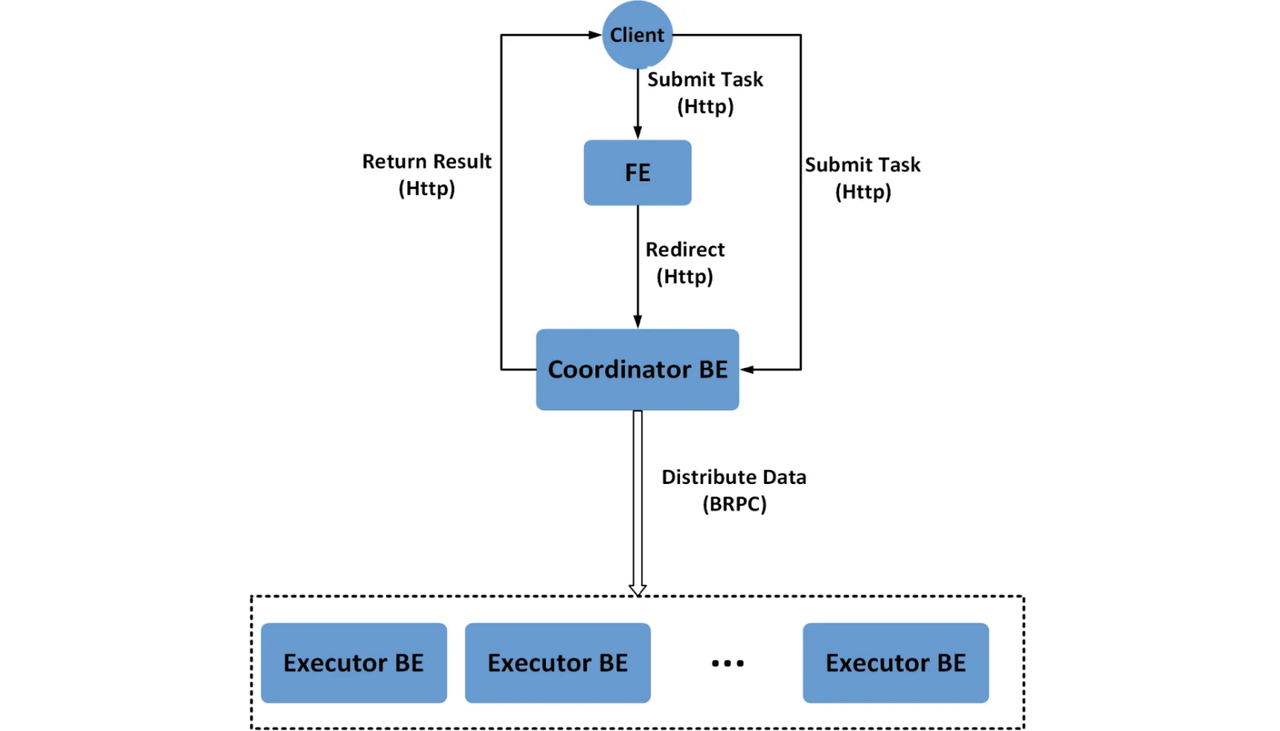
\ In the final Datasink Node of the Coordinator's execution pipeline, the data needs to be routed to the correct partitions, buckets, and Doris Backend node locations before it can be successfully transmitted and stored.
\ To enable this data transfer, the Coordinator and Executor nodes establish communication channels:
\
- The sending end is called the Node Channel.
- The receiving end is called the Tablets Channel.
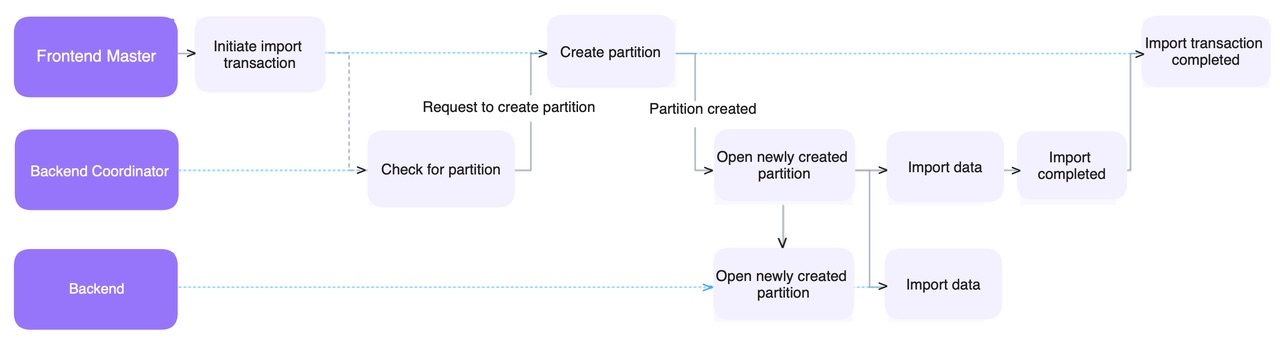
\ This is how Auto Partition comes into play during the process of determining the correct partitions for the data:
\
\
Previously, without Auto Partition, when a table does not have the required partition, the behavior in Doris is for the BE nodes to accumulate errors until a DATA_QUALITY_ERROR is reported. Now, with Auto Partition enabled, a request will be initiated to the Doris Frontend to create the necessary partition on-the-fly. After the partition creation transaction is completed, the Doris Frontend responds to the Coordinator, which then opens the corresponding communication channels (Node Channel and Tablets Channel) to continue the data ingestion process. This is a seamless experience for users.
\ In a real-world cluster environment, the time spent by the Coordinator waiting for the Doris Frontend to complete partition creation can incur large overheads. This is due to the inherent latency of Thrift RPC calls, as well as lock contention on the Frontend under high load conditions.
\ To improve the data ingestion efficiency in Auto Partition, Doris has implemented batching to largely reduce the number of RPC calls made to the FE. This brings a notable performance enhancement for data write operations.
\ Note that when the FE Master completes the partition creation transaction, the new partition becomes immediately visible. However, if the import process ultimately fails or is canceled, the created partitions are not automatically reclaimed.
Auto Partition performance
We tested the performance and stability of Auto Partition in Doris, covering different use cases:
\ Case 1: 1 Frontend + 3 Backend; 6 randomly generated datasets, each having 100 million rows and 2,000 partitions; ingested the 6 datasets concurrently into 6 tables
\
Objective: Evaluate the performance of Auto Partition under high pressure and check for any performance degradation.
\
Results: Auto Partition brings an average performance loss less than 5%, with all import transactions running stably.
\
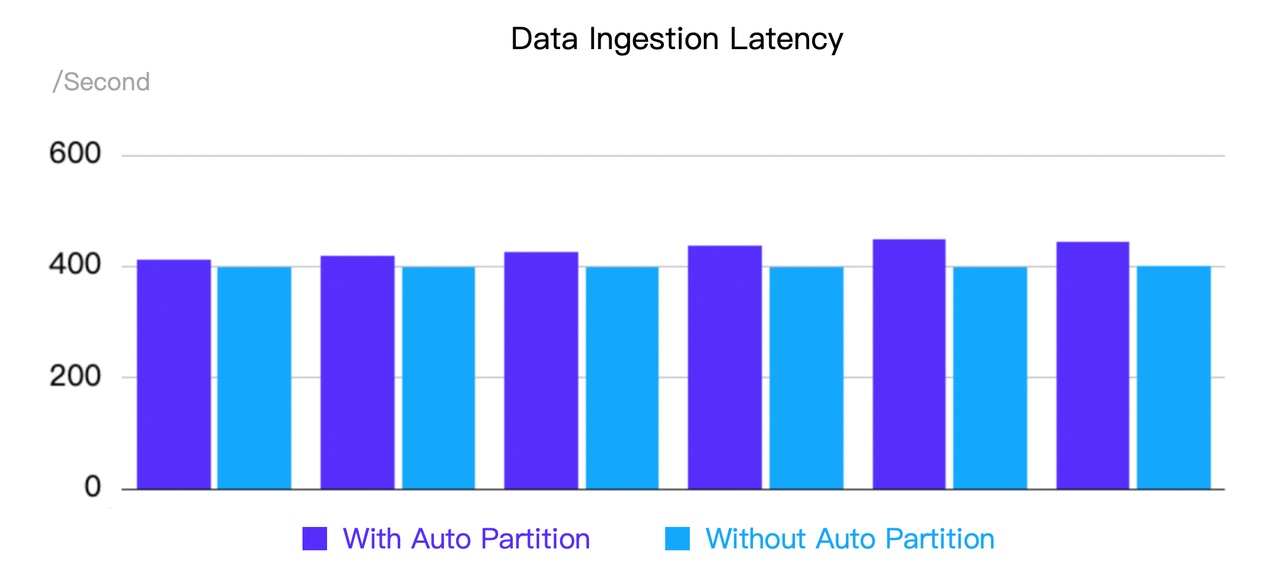
\ Case 2: 1 Frontend + 3 Backend; ingesting 100 rows per second from Flink by Routine Load; testing with 1, 10, and 20 concurrent transactions (tables), respectively
\
Objective: Identify any potential data backlog issues that could arise with Auto Partition under different concurrency levels.
\
Results: With or without Auto Partition enabled, the data ingestion was successful without any backpressure issues across all the concurrency levels tested, even at 20 concurrent transactions when the CPU utilization reached close to 100%.
\
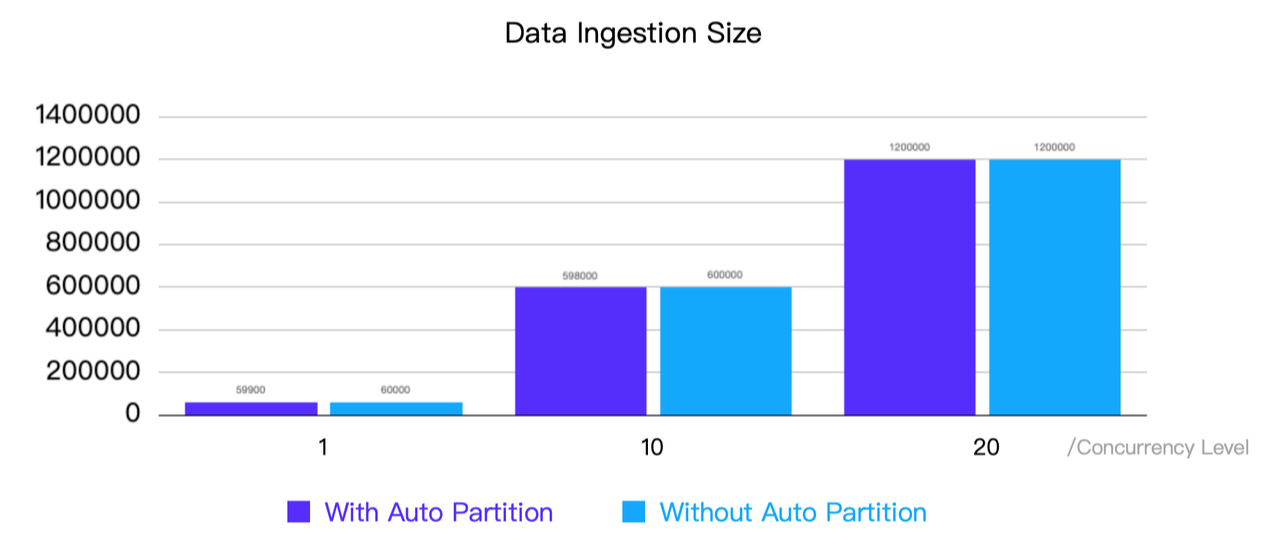
\ To conclude the results of these tests, the impact of enabling Auto Partition on data ingestion performance is minimal.
Conclusion and Future Plans
Auto Partition has simplified DDL and partition management since Apache Doris 2.1.0. It is useful in large-scale data processing and makes it easy for users to migrate from other database systems to Apache Doris.
\ Moreover, we are committed to expanding the capabilities of Auto Partition to support more complex data types.
\ Plans for Auto Partition by RANGE:
\
Support numeric values;
\
Allowing users to specify the left and right boundaries of the partition range.
\
Plans for Auto Partition by LIST:
\
- Allow merging multiple values into the same partition based on specific rules.
\
This content originally appeared on HackerNoon and was authored by Frank Z
Frank Z | Sciencx (2024-07-20T14:00:22+00:00) Evolution of Data Sharding Towards Automation and Flexibility in Apache Doris. Retrieved from https://www.scien.cx/2024/07/20/evolution-of-data-sharding-towards-automation-and-flexibility-in-apache-doris/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.