
This content originally appeared on HackerNoon and was authored by Idempotent Tech
:::info Authors:
(1) Li Siyao, S-Lab, Nanyang Technological University;
(2) Tianpei Gu, Lexica and Work completed at UCLA;
(3) Weiye Xiao, Southeast University;
(4) Henghui Ding, S-Lab, Nanyang Technological University;
(5) Ziwei Liu, S-Lab, Nanyang Technological University;
(6) Chen Change Loy, S-Lab, Nanyang Technological University and a Corresponding Author.
:::
Table of Links
5. Experiment

\
\ Evaluation Metric. Following [16, 5], we adopt the chamfer distance (CD) as the evaluation metric, which has been initially introduced to measure the similarity between two point clouds. Formally, CD is computed as:
\

5.1. Comparison to Existing Methods

\
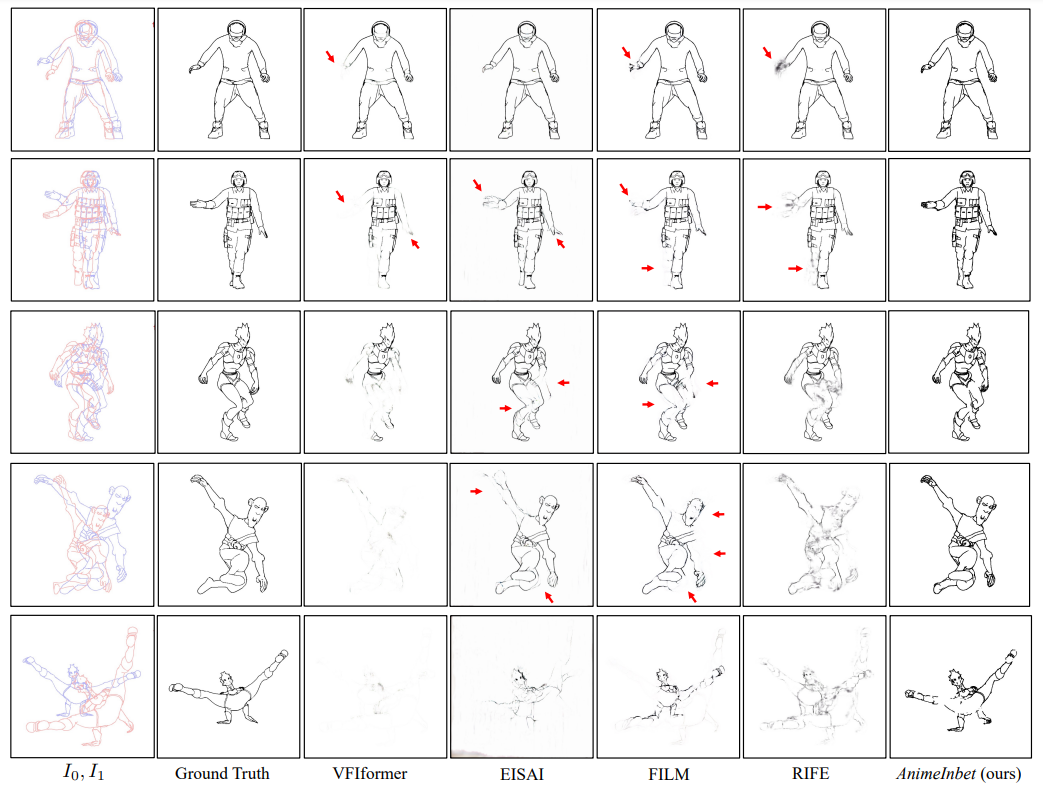
\ As shown in Table 2, our AnimeInbet favorably outperforms all compared methods on both the validation set and the test set of MixamoLine240. On the validation set, our approach achieves an average CD value of 11.53, representing a significant improvement over the best-performing compared method, FILM, with over 30% enhancement. Upon closer inspection, the advantage of AnimeInbet becomes more pronounced as the frame gap increases (0.98, 5.72 and 9.47 for gaps of 1, 5, and 9, respectively), indicating that our method is more robust in handling larger motions. On the test set, our method maintains its lead over the other compared methods, with improvements of 0.70 (20%), 5.25 (29%), and 10.30 (31%) from the best-performing compared method FILM for the frame gaps of 1, 5, and 9, respectively. Given that both the characters and actions in the test set are new, our method’s superiority on the test set provides more convincing evidence of its advantages over the existing frame interpolation methods.
\ To illustrate the advantages of our method, we present several inbetweening results in Figure 8. We arranged these examples in increasing levels of difficulty from top to bottom. When the motion is simple, compared methods can interpolate a relatively complete shape of the main body of the drawing. However, they tend to produce strong blurring (RIFE) or disappearance (VFIformer, EISAI, and FILM) of noticeable moving compositions (indicated by red arrows). In contrast, our method maintains a concise line structure in these key areas. When the input frames involve the whole body’s movement within large magnitudes, the intermediate frames predicted by the compared methods become indistinguishable and patchy, rendering the results invalid for further
\
\

\ use. However, our AnimeInbet method can still preserve the general shape in the correct positions, even with a partial loss of details, which can be easily fixed with minor manual effort.
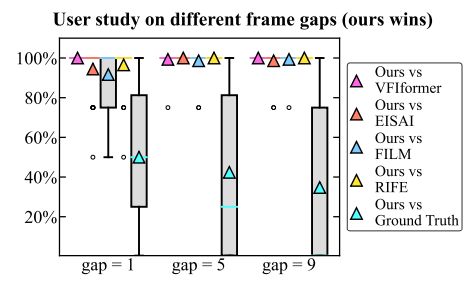
\ User Study. To further evaluate the visual performance of our methods, we conduct a user study among 36 participants. For each participant, we randomly show 60 pairs, each composed of a result of AnimeInbet and that of a compared method, and ask the participant to select the better. To allow participants to take temporal consistency into the decision, we display these results in GIF formats formed by triplets of input frames and the inbetweened one. The winning rates of our method are shown in Figure 9, where AnimeInbet wins over 92% versus the compared methods. Notably, for “gap = 5” and “gap = 9” slots, the winning rates of our methods are close to 100% with smaller deviations than “gap = 1”, suggesting the advantages of our method on cases within large motions.
5.2. Ablation Study
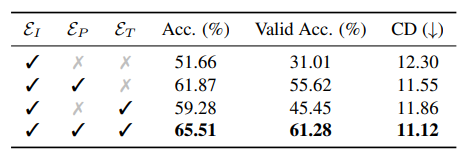
Embedding Features. To investigate the effectiveness of the three types of embeddings mentioned in Section 4.1, we trained several variants by removing the corresponding modules. As shown in Table 3, for each variant, we list the matching accuracy for all vertices (“Acc.”), the accuracy for non-occluded vertices (“Valid Acc.”) and the final CD values of inbetweening on the validation set (gap = 5). If removing the positional embedding EP , the “Valid Acc.” and the CD value drop 15.83% and 0.74, respectively; while the lacking of topological embedding ET lowers “Valid Acc.” by 5.66% and worsens CD by 0.43, which reveals the importance of these two components.
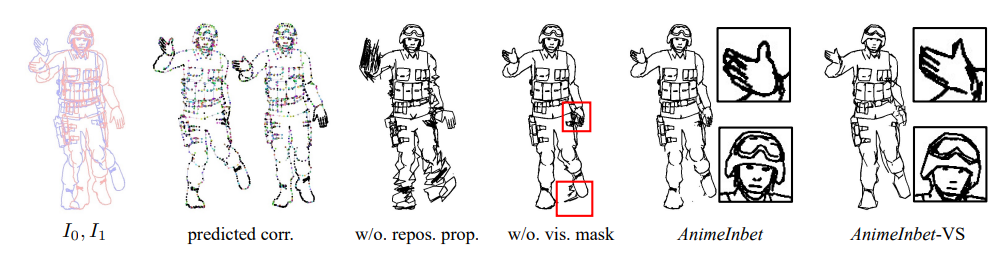
\ Repositioning Propagation and Visibility Mask. We demonstrate the contribution of repositioning propagation (prepos. prop.) and visibility mask (vis. mask) both quantitatively and qualitatively. As shown in Table 4, without repositioning propagation, the CD value will be sharply worsened by 12.50 (112%), while the lacking of visibility mask will also make a drop of 1.69 (15%). An example is shown in Figure 10, where “w/o. repos. prop.” appears within many messy lines due to undefined positions for those unmatched vertices, while “w/o. vis. mask” shows some redundant segments (red box) after repositioning; the complete AnimeInbet can resolve these issues and produce a clean yet complete result.
\
\
\ Geometrizor. As shown in Table 2, the quantitative metrics of AnimeInbet-VS are generally worse by around 0.6 compared to AnimeInbet. This is because VirtualSketcher [15] does not vectorize the line arts as precisely as the ground truth labels (average vertex number 587 vs 1,351). As shown in Figure 10, the curves in “AnimeInbet-VS” become sharper and lose some details, which decreases the quality of the inbetweened frame. Using a more accurate geometrizer would lead to higher quality inbetweening results for raster image inputs.
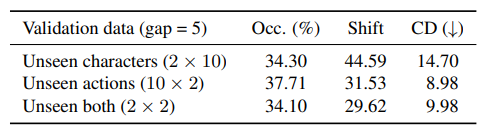
\ Data Influence. As mentioned in Section 3, we created a validation set composed of 20 sequences of unseen characters but seen actions, 20 of unseen actions but seen characters and 4 of unseen both to explore the influence on data. Our experiment finds that whether the characters or the actions are seen does not fundamentally influence the inbetweening quality, while the motion magnitude is the key factor. As shown in Table 5, the CD value of unseen characters is 14.70, which is over 47% worse than that of unseen both due to larger vertex shifts (44.59 vs 29.62), while the difference between the CD values of unseen actions and unseen both is around 10% under similar occlusion rates and shifts.
\
:::info This paper is available on arxiv under CC BY-NC-SA 4.0 DEED license.
:::
\
This content originally appeared on HackerNoon and was authored by Idempotent Tech
Idempotent Tech | Sciencx (2024-07-24T19:00:18+00:00) Deep Geometrized Cartoon Line Inbetweening: Experiment. Retrieved from https://www.scien.cx/2024/07/24/deep-geometrized-cartoon-line-inbetweening-experiment/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.