
This content originally appeared on HackerNoon and was authored by Idempotent
:::info Authors:
(1) Li Siyao, S-Lab, Nanyang Technological University;
(2) Tianpei Gu, Lexica and Work completed at UCLA;
(3) Weiye Xiao, Southeast University;
(4) Henghui Ding, S-Lab, Nanyang Technological University;
(5) Ziwei Liu, S-Lab, Nanyang Technological University;
(6) Chen Change Loy, S-Lab, Nanyang Technological University and a Corresponding Author.
:::
Table of Links
3. Mixamo Line Art Dataset
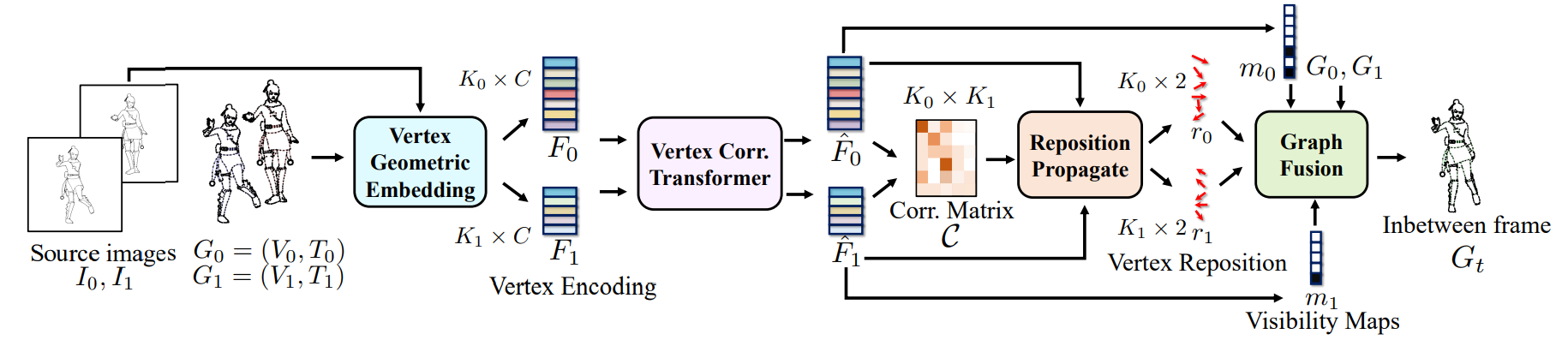
To facilitate training and evaluation of geometrized line inbetweening, we develop a large-scale dataset, named MixamoLine240, which consists of 240 sequences of consecutive line drawing frames, with 100 sequences for training and 140 for validation and testing. To obtain this vast amount of cartoon line data, we utilize a “Cel-shading” technique, i.e., to use computer graphics software (Blender in this work) to render 3D resources into an anime-style appearance that mimics the hand-drawn artistry. Unlike previous works [25, 29] that only provide raster images, MixamoLine240 also provides ground-truth geometrization labels for each frame, which include the coordinates of a group of vertices (V ) and the connection topology (T). Additionally, we assign an index number (R[i]) to each 2D endpoint (V [i]) that refers to a unique vertex in the 3D mesh of the character, as illustrated in Figure 3, which can be further used to deduce the vertex level correspondence. Specifically, given two frames I0 and
\
\ I1 in a sequence, the 3D reference IDs reveal the vertex correspondence {(i, j)} for those vertices i in I0 and j in I1 having R0[i] = R1[j], while the rest unmatched vertices are marked as occluded. This strategy allows us to produce correspondence pairs with arbitrary frame gaps to flexibly adjust the input frame rate during training. Next, we discuss the construction and challenges inherent in the data.
\ Data Construction. In Blender, the mesh structure of a 3D character remains stable, i.e., the number of 3D vertex and the edge topology keep constant, when moving without additional subdivision modifier. We employ this property to achieve consistent line art rendering and accurate annotations for geometrization and vertex matching. As shown in Figure 3, the original 3D mesh contains all the necessary line segments required to represent the character in line art. During rendering, the visible outline from the camera’s perspective is selected based on the material boundary and the object’s edge. This process ensures that every line segment in the resulting raster image corresponds to an edge in the original mesh. The 2D endpoints of each line segment are simply the relevant 3D vertices projected onto the camera plane, referenced by the unique and consistent index of the corresponding 3D vertex. Meanwhile, since the 3D mesh naturally defines the vertex connections, the topology of the 2D lines can be transferred from the selective edges used for rendering. To prevent any topological ambiguity that may be caused by overlapped vertices in 3D space, we merge the endpoints that are within a Euclidean distance of 0.1 in the projected 2D space. This enables us to obtain both the raster line drawings and the accurate labels of each frame.
\ To create a diverse dataset, we used the open-source 3D material library Mixamo [1] and selected 20 characters and 20 actions, as shown in Figure 4. Each action has an average of 191 frames. We combined 10 characters and 10 actions to render 100 sequences, with a total of 19,930 frames as the training set. We then used the remaining 10 characters and 10 actions to render an 18,230-frame test set, ensuring that the training and testing partitions are exclusive. We also created a 44-sequence validation set, consisting of 20 unseen characters, 20 unseen actions, and 4 with both unseen character and action. To create this set, we combined the test characters “Swat”and “Warrok” and actions “sword slash” and “hip hop” with the training characters and actions. The
\
\ validation set contains 11,102 frames and was also rendered at 1080p resolution with a frame rate of 60 fps. To ensure consistency across all frames, we cropped and resized each frame to a unified 720 × 720 character-centered image.
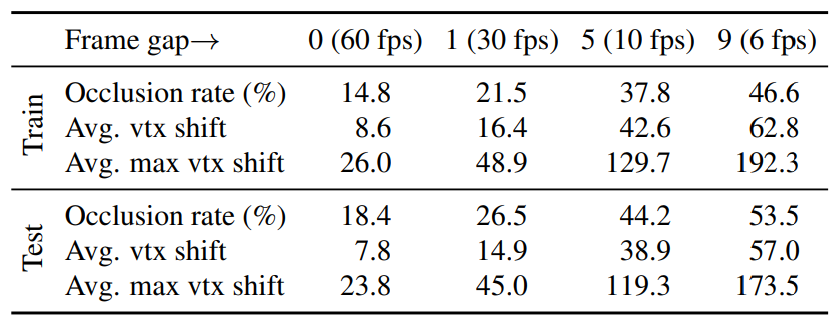
\ Challenges. Table 1 summarizes the statistics that reflect the difficulty of the line inbetweening task under various input frame rates. With an increase in frame gaps, the inbetweening task becomes more challenging with larger motion magnitudes and higher occlusion percentages. For instance, when the frame gap is 9, the input frame rate becomes 6 fps, and the average vertex shift is 62.8 pixels. The mean value of the maximum vertex shift in a frame (“Avg. max vtx shift”) reaches 192.3 pixels, which is 27% of the image width. Additionally, nearly half of the vertices are unmatched in such cases, making line inbetweening a tough problem. Furthermore, the image composition of the test set is more complex than that of the training set. A training frame has an average of 1,256 vertices and 1,753 edges, while a test frame has an average of 1,512 vertices and 2,099 edges since the test set has more complex characters such as “Maw”.
\
:::info This paper is available on arxiv under CC BY-NC-SA 4.0 DEED license.
:::
\
This content originally appeared on HackerNoon and was authored by Idempotent
Idempotent | Sciencx (2024-07-24T15:00:18+00:00) Deep Geometrized Cartoon Line Inbetweening: Mixamo Line Art Dataset. Retrieved from https://www.scien.cx/2024/07/24/deep-geometrized-cartoon-line-inbetweening-mixamo-line-art-dataset/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.