
This content originally appeared on HackerNoon and was authored by Can Kisi
\
Introduction
2024 has been marked by an upsurge of fake news that has not only played a disproportionate role in global events and elections in the UK and the US but has fueled public views with misinformation that affects election procedures for both these countries and beyond, where people can be seen at times unable to make out what is true or fake. Artificial Intelligence and Machine Learning are playing the most pivotal role amidst such a chaotic scenario. Advanced algorithms are at work to scan for and trace fake news in a quest to restore faith in information sources and media. This chapter will be a very exciting journey as we understand how a bit of code, based on an RNN's power, can play a big part in detecting and counterbalancing the effects of fake news. Let’s move on to the real work and go step by step into the process of creating an RNN model and utilising it against misinformation.
Setting the Stage
The first step will be, as always, setting up our environment. These are the libraries and tools we'll use:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import nltk
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense, Dropout
from tensorflow.keras.optimizers import Adam
import re
This part includes all the essential libraries like numpy and pandas for data handling, tensorflow for neural network building and training, and sklearn for model estimate.
Data Loading and Preprocessing
Our awesome Kaggle dataset is what made everything possible. It contains news articles labeled as real or fake. Let’s load it:
data = pd.read_csv('/kaggle/input/fake-news-classification/WELFake_Dataset.csv')
data = data.fillna('')
The dataset is a CSV file with columns three columns: 'title', 'text', and 'label'. We clean the text, tokenize it, and convert it into sequences suitable for our RNN.
# Combine title and text
data['content'] = data['title'] + ' ' + data['text']
# Define the target and features
X = data['content']
y = data['label']
# Text preprocessing function
def preprocess_text(text):
text = text.lower()
text = re.sub(r'\W', ' ', text)
text = re.sub(r'\s+', ' ', text)
return text
X = X.apply(preprocess_text)
Here, we combine the title and text of each article into a single feature and clean the text to remove non-alphanumeric characters and extra spaces.

\ \
Tokenizing and Padding Sequences
Next, let’s tokenize the text and convert it into sequences:
tokenizer = Tokenizer()
tokenizer.fit_on_texts(X)
sequences = tokenizer.texts_to_sequences(X)
maxlen = 100 # Max length of sequences
X = pad_sequences(sequences, maxlen=maxlen)
Here, Tokenizer converts words to integers, and pad_sequences ensures all sequences are of the same length, maxlen.
Building the Neural Network
Now, the fun part begins—constructing the RNN model. The architecture includes an Embedding layer, LSTM layer, and Dense layers.
from keras.callbacks import EarlyStopping
model = Sequential()
model.add(Embedding(input_dim=len(tokenizer.word_index) + 1, output_dim=16, input_length=500))
model.add(LSTM(units=100, return_sequences=True))
model.add(Dropout(0.6))
model.add(LSTM(units=100))
model.add(Dropout(0.6))
model.add(Dense(units=1, activation='sigmoid'))
early_stop = EarlyStopping(monitor='val_loss', patience=10)
Embedding Layer: Provides a mapping function from input sequences to a higher-dimensional space, often used for representing words or categorical variables.
LSTM Layer: A type of RNNs that can detain long-term dependencies in sequential data. LSTMs are able to process and analyze sequential data, such as time series, text, and speech.
Dropout Layer: is a regularization technique used to prevent overfitting in neural networks
Dense Layer: is a classic fully connected neural network layer: each input node is connected to each output node.
\ Finally, the early stop will stop the training process before it reaches the maximum number of epochs based on validation loss.
\
Compiling and Training the Model
With the architecture in place, we compile the model with the appropriate loss function, optimizer, and evaluation metric:
model.compile(loss='binary_crossentropy', optimizer=Adam(learning_rate=0.001), metrics=['accuracy'])
Time to train the model:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
history = model.fit(X_train, y_train, epochs=100, batch_size=200, validation_data=(X_test, y_test), callbacks=[early_stop])
Here, epochs define how many times the learning algorithm will work through the entire training dataset, and batch_size is the number of samples processed before updating the model.

\
Evaluating the Model
After training, we evaluate the model’s performance on the test set:
loss, accuracy = model.evaluate(X_test, y_test)
print(f'Test Accuracy: {accuracy:.4f}')
Visualizing the Results
To make our findings more tangible, we plot the accuracy and loss over epochs:
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label='val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
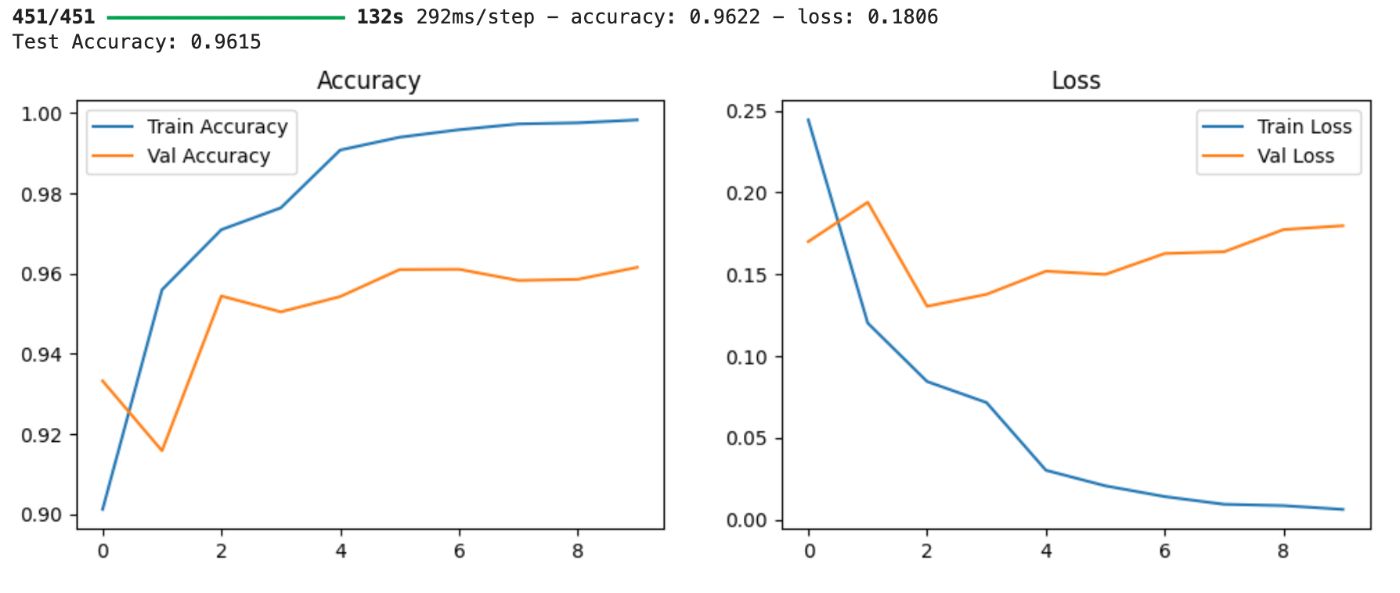
\ This visualization helps us understand how well the model has learned over time and whether it’s overfitting or underfitting.
\
def preprocess_input_text(text, tokenizer, maxlen=500):
text = text.lower()
text = re.sub(r'\W', ' ', text)
text = re.sub(r'\s+', ' ', text)
sequences = tokenizer.texts_to_sequences([text])
padded_sequences = pad_sequences(sequences, maxlen=maxlen)
return padded_sequences
fake_news_paragraph = """
Schumer calls on Trump to appoint official to oversee Puerto Rico relief
"""
# Preprocess the input text
input_data = preprocess_input_text(fake_news_paragraph, tokenizer)
# Make a prediction
prediction = model.predict(input_data)
# Print the prediction
if prediction < 0.5:
print("The news is predicted to be Fake.")
else:
print("The news is predicted to be Real.")
print(prediction)
Now time to give it a test from the real world of fake news, In the code above, The preprocessinputtext function cleans, tokenizes, and pads the input text in adherence to what the model wants. Using this function, the following code snippet preprocesses a sample news paragraph, makes a prediction of its authenticity, and prints the result.

\
Explanation of Parameter Choices and Recommendations
We used the binary_crossentropy loss function, which is ideal for the binary classification task, such as the distinction between fake and real news. We implemented the Adam optimizer due to its dynamic nature and efficient choice of step size with a learning rate of 0.001 for fast order and better results. For the sake of training, we have split our data using the train_test_split that provides for a test size of 20%. This ensures that we have a resilient assessment and a commanding supply of training data. We set the number of epochs to 100 since the early stop will stop it before and a batch size of 200 so that we could trade some memory use for faster training.
\ Other optimizers that can be used are RMSprop or SGD. A test size between 10% to 30% can change how your model is evaluated. Numbers like 50 and 150 also can influence how much train_epoch can change the dynamics of training and, consequently, the performance outcome.
Behind the Scenes
Embedding Layer
The embedding layer works like a dictionary or a lookup table that maps each word in the vocabulary onto a high-dimensional vector. These vectors capture semantics—similar words are mapped to similar vectors, enabling the model to capture context.
LSTM Layer
LSTM is a long short-term memory layer, a special type of RNN that can learn long-term dependencies. LSTMs excel at sequence prediction tasks where they hold on to the memory of previous inputs and hence do a good job of understanding context.
Binary Classification
The sigmoid activation in the Dense layer gives us probabilities, which we then convert into 0/1 class labels by choosing an appropriate threshold value of 0.5.
Challenges and Considerations
Data Quality: The model's accuracy is greatly linked to the quality of the dataset. This could be affected by biased data in the dataset, if you check the dataset, you might detect some focus on US election related fake news.
Overfitting: Probably the most common pitfall in machine learning, where your model does really great on training data and poorly on unseen data. For example, when I tested it manually on actual fake data, it did well, but when I tried to come up with some fake news (something like: A tourist farted with such force that a small section of London Bridge was damaged.) it marked it as real :)

\
Conclusion
Though challenging, it is equally rewarding to be in a position to build a fake news detection system using RNNs. This code will walk you through the stage of data preprocessing to model evaluation. The power of RNNs, especially LSTMs, is utilized while decoding sequential data to make a distinction between real and fake news. If we could fine-tune these models and get hold of global news datasets, AI could then be at the core of battling misinformation.
\ Knowing the code and, more importantly, the concepts that lie behind helps you appreciate the elegance of such models and their immense potential to shape a more aware world.
This content originally appeared on HackerNoon and was authored by Can Kisi
Can Kisi | Sciencx (2024-07-25T18:15:31+00:00) DIY Fake News Detector: Unmask misinformation with Recurrent Neural Networks. Retrieved from https://www.scien.cx/2024/07/25/diy-fake-news-detector-unmask-misinformation-with-recurrent-neural-networks/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.