
This content originally appeared on Level Up Coding - Medium and was authored by Itsuki
**********
Disclaimer: We are using BETA!!! Because I love (and only love) new things!!!
Feel free to grab the demo app/code from GitHub and play around with it as you read along.
Also, If you are interested in detecting from live capture, check out one of my other articles, SwiftUI + Vision: Object detection in Live Capture!
**********
Vision is a framework combines machine learning technologies and Swift’s concurrency features to perform computer vision tasks in app.
Here is the reason I decided to check it out.
I was originally looking at using YOLO for object detection and recognition. However, the library itself is under GNU license…
BUT! Some of features provided by Vision is actually build on top of YOLO which means we should get even better result comparing to using the raw library!
Anyway!
In this article, let’s check out how we can use Vision to perform object detection on still images using the brand new BETA VisionRequest and VisionResult only available for iOS 18+.
Specifically, We will do 3 examples.
- Text Detection & recognition
- Barcode Detection
- Combination of Multiple types of Detections
Technically speaking, all VisionRequest are performed in the same way. Once you know one, you get them all!
Additionally, I will also be sharing with you some of the errors I bumped myself into and the way I got out of those.
Feel free to grab the demo app/code from GitHub as you read along.
Also, If you are interested in detecting from live capture, check out one of my other articles, SwiftUI + Vision: Object detection in Live Capture!
Download Xcode beta and get iOS 18 running! We are staring!
Side Note
I don’t want to write @available(iOS 18, *) on all my structs, classes, enums, so I have set the Minimum Deployments to 18.0 instead.

Text
Let’s start with the simple where we will retrieve the string recognized and display it.
To do so, we will be using RecognizeTextRequest, an image-analysis request that recognizes text in an image.
To specify or limit the languages to find in the request, we can set recognitionLanguages to an array that contains the names of the languages of text we want to recognize.
import SwiftUI
import Vision
class VisionManager: ObservableObject {
@Published var resultStrings: [String] = []
func recognizeText(data: Data) async {
self.resultStrings = []
var request = RecognizeTextRequest()
request.recognitionLanguages = [Locale.Language.init(identifier: "en-US")]
do {
let results = try await request.perform(on: data)
let recognizedStrings = results.compactMap { observation in
observation.topCandidates(1).first?.string
}
print(recognizedStrings)
self.resultStrings = recognizedStrings
} catch(let error) {
print("error recognizing text: \(error.localizedDescription)")
}
}
}
I have limited the language here to en-US here, but you can also allow all system languages by setting request.recognitionLanguages = Locale.Language.systemLanguages.
I am performing the request on data, but you also get the choice of using
Before we test it out, let’s add the following image to our Asset and name it enjoyText.

And let’s use our VisionManager to detect the text from the image above!
struct StillImageDetection: View {
@StateObject private var visionManager = VisionManager()
var body: some View {
VStack(spacing: 16) {
Image("enjoyText")
.resizable()
.scaledToFit()
.frame(width: 150)
Button(action: {
Task {
guard let imageData = UIImage(named: "enjoyText")?.pngData() else {
return
}
await visionManager.recognizeText(data: imageData)
}
}, label: {
Text("Detect Text")
.foregroundStyle(.black)
.padding(.all)
.background(
RoundedRectangle(cornerRadius: 8)
.stroke(.black, lineWidth: 2.0))
})
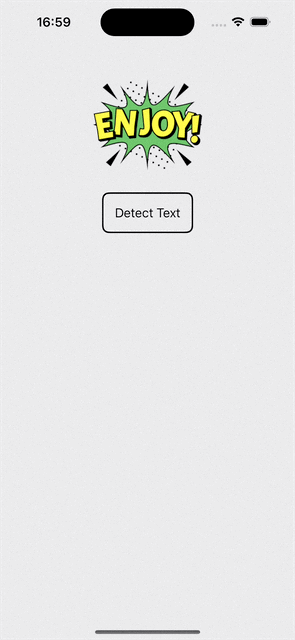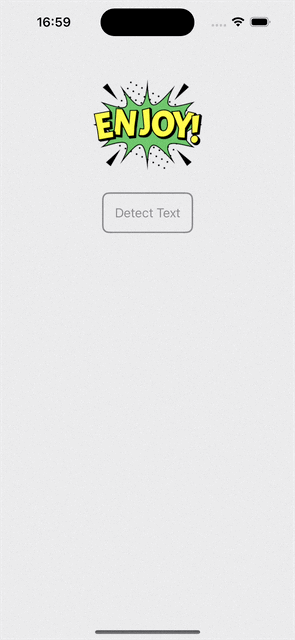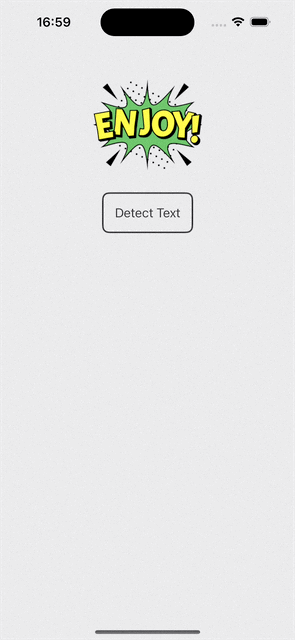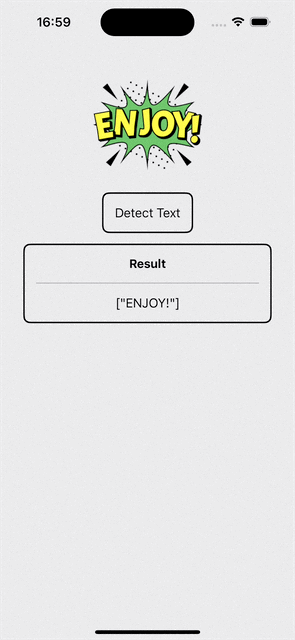
if !visionManager.resultStrings.isEmpty {
VStack(spacing: 16) {
Text("Result")
.font(.system(size: 16, weight: .bold))
Divider()
.background(.black)
Text("\(visionManager.resultStrings)")
}
.foregroundStyle(.black)
.padding()
.frame(maxWidth: .infinity)
.background(
RoundedRectangle(cornerRadius: 8)
.stroke(.black, lineWidth: 2.0))
}
}
.frame(maxWidth: .infinity, maxHeight: .infinity, alignment: .top)
.padding(.all, 32)
}
}
Add Overlay Result Rectangles
We get the result, but definitely not a good way to visualize it!
Don’t we want those surrounding rectangles indicating which part of the image the text recognized is from with the text being the label together with how confidence we are about the prediction?
I do!
And we can retrieve the information from RecognizedTextObservation and process it like following.
import SwiftUI
import Vision
class VisionManager: ObservableObject {
@Published var textObservations: [RecognizedTextObservation] = []
func processTextObservation(_ observation: RecognizedTextObservation, for imageSize: CGSize) -> (text: String, confidence: Float, size: CGSize, position: CGPoint) {
let recognizedText = observation.topCandidates(1).first?.string ?? ""
let confidence = observation.topCandidates(1).first?.confidence ?? 0.0
let boundingBox = observation.boundingBox
let converted = boundingBox.toImageCoordinates(imageSize, origin: .upperLeft)
let position = CGPoint(x: converted.midX, y: converted.midY)
return (recognizedText, confidence, converted.size, position)
}
func recognizeText(_ data: Data) async {
var request = RecognizeTextRequest()
request.recognitionLanguages = Locale.Language.systemLanguages
do {
let results = try await request.perform(on: data)
DispatchQueue.main.async {
self.textObservations = results
}
} catch(let error) {
print("error recognizing text: \(error.localizedDescription)")
}
}
}
Note that in order to convert boundingBox which is a NormalizedRect to a Rectangle in the image Coordinate, we will need to provide the image Size.
By that means, we need a GeometryReader!
struct StillImageDetection: View {
@StateObject private var visionManager = VisionManager()
@State private var imageSize: CGSize = .zero
var body: some View {
VStack(spacing: 16) {
Image("enjoyText")
.resizable()
.scaledToFit()
.frame(maxWidth: .infinity)
.overlay(content: {
GeometryReader { geometry in
DispatchQueue.main.async {
self.imageSize = geometry.size
}
return Color.clear
}
})
.overlay(content: {
ForEach( 0..<visionManager.textObservations.count, id: \.self) { index in
let observation = visionManager.textObservations[index]
let (text, confidence, boxSize, boxPosition) = visionManager.processTextObservation(observation, for: imageSize)
RoundedRectangle(cornerRadius: 8)
.stroke(.black, style: .init(lineWidth: 4.0))
.overlay(alignment: .topLeading, content: {
Text("\(text): \(confidence)")
.background(.white)
.offset(y: -28)
})
.frame(width: boxSize.width, height: boxSize.height)
.position(boxPosition)
}
})
Button(action: {
guard let imageData = UIImage(named: "enjoyText")?.pngData() else { return }
Task {
await visionManager.recognizeText(imageData)
}
}, label: {
Text("Detect Text")
.foregroundStyle(.black)
.padding(.all)
.background(
RoundedRectangle(cornerRadius: 8)
.stroke(.black, lineWidth: 2.0))
})
}
.frame(maxWidth: .infinity, maxHeight: .infinity, alignment: .top)
.padding(.all, 32)
}
}
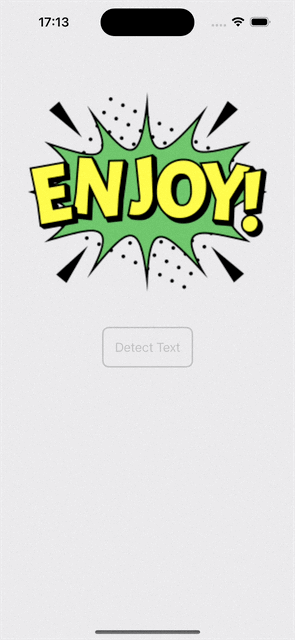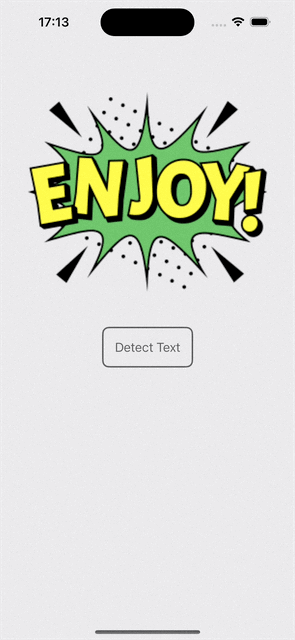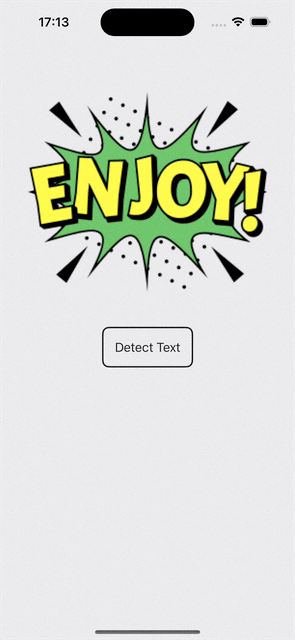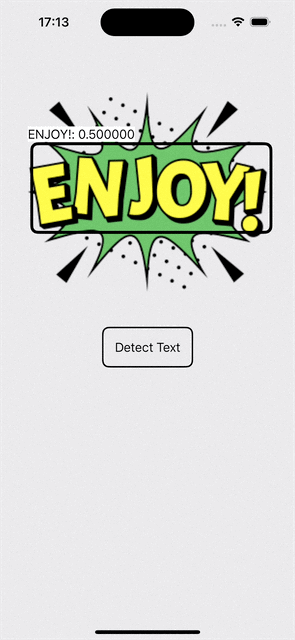
Honestly speaking, I am pretty surprised by the low confidence…
Detect Text Region
If you are only interested in the rectangle surrounding the text, you can also use DetectTextRectanglesRequest instead. This request generates a collection of TextObservation objects that describe each text region the request detects.
Barcodes
Before we move onto performing a combination of multiple requests, let’s take a look at another example.
I have chose barcode here because I ran into this Vision.VisionError.operationFailed(“Failed to create barcode detector”) while trying to ran the code in the simulator.
I spend a fair amount of time trying to find the reason and it seems like being that the barcode request only work on real device (at least for me)!
Anyway, let’s take a look at how we can use DetectBarcodesRequest to detects barcodes in an image. It’s performed and handled in almost the same as above.
class VisionManager: ObservableObject {
//...
@Published var barcodeObservations: [BarcodeObservation] = []
func detectBarcode(_ data: Data) async {
var request = DetectBarcodesRequest()
request.symbologies = [.qr]
do {
let results = try await request.perform(on: data)
DispatchQueue.main.async {
self.barcodeObservations = results
}
} catch(let error) {
print(error)
print("error recognizing barcode: \(error.localizedDescription)")
}
}
func processBarcodeObservation(_ observation: BarcodeObservation, for imageSize: CGSize) -> (text: String, confidence: Float, size: CGSize, position: CGPoint) {
let recognizedText = observation.payloadString ?? "Payload String not available"
let confidence = observation.confidence
let boundingBox = observation.boundingBox
let converted = boundingBox.toImageCoordinates(imageSize, origin: .upperLeft)
let position = CGPoint(x: converted.midX, y: converted.midY)
return (recognizedText, confidence, converted.size, position)
}
}
I have specified the symbologies I wanted to supported here being qr only. You check out the entire list of barcode symbologies that the framework detects here.
Below is the QR Code I am using.

You can also create your own using https://qrfy.com/app/my-qr-codes.
Add it to Asset with a name enjoyQR.
struct StillImageDetection: View {
@StateObject private var visionManager = VisionManager()
var body: some View {
VStack(spacing: 16) {
Image("enjoyQR")
.resizable()
.scaledToFit()
.frame(maxWidth: .infinity)
.overlay(content: {
GeometryReader { geometry in
DispatchQueue.main.async {
self.imageSize = geometry.size
}
return Color.clear
}
})
.overlay(content: {
ForEach( 0..<visionManager.barcodeObservations.count, id: \.self) { index in
let observation = visionManager.barcodeObservations[index]
let (text, confidence, boxSize, boxOrigin) = visionManager.processBarcodeObservation(observation, for: imageSize)
RoundedRectangle(cornerRadius: 8)
.stroke(.black, style: .init(lineWidth: 4.0))
.overlay(alignment: .topLeading, content: {
Text("\(text): \(confidence)")
.background(.white)
.offset(y: -28)
})
.frame(width: boxSize.width, height: boxSize.height)
.position(boxPosition)
}
})
Button(action: {
Task {
guard let imageData = UIImage(named: "enjoyQR")?.pngData() else {
return
}
await visionManager.detectBarcode(data: imageData)
}
}, label: {
Text("Detect Barcode")
.foregroundStyle(.black)
.padding(.all)
.background(
RoundedRectangle(cornerRadius: 8)
.stroke(.black, lineWidth: 2.0))
})
}
.frame(maxWidth: .infinity, maxHeight: .infinity, alignment: .top)
.padding(.all, 32)
}
}
Yes! Let’s enjoy life! I am glad that we are 100% sure about that this time!
Combination of Multiple Requests
Time to check out how we can perform multiple requests on the same image!
Of course, you can just call the functions above sequentially but let’s use ImageRequestHandler here so that we get an idea of how we can handle the generic VisionResult and VisionObservation.
class VisionManager: ObservableObject {
@Published var observations: [any VisionObservation] = []
func detectBarcodeAndText(_ data: Data) async {
var textRequest = RecognizeTextRequest()
textRequest.recognitionLanguages = [Locale.Language.init(identifier: "en-US")]
var barcodeRequest = DetectBarcodesRequest()
barcodeRequest.symbologies = [.qr]
let requests: [any VisionRequest] = [textRequest, barcodeRequest]
let imageRequestHandler = ImageRequestHandler(data)
let results = imageRequestHandler.performAll(requests)
await handleVisionResults(results: results)
}
@MainActor
private func handleVisionResults(results: some AsyncSequence<VisionResult, Never>) async {
self.observations = []
for await result in results {
switch result {
case .recognizeText(_, let observations):
print("text")
self.observations.append(contentsOf: observations)
case .detectBarcodes(_, let observations):
print("barcode")
self.observations.append(contentsOf: observations)
default:
return
}
}
}
@MainActor
func processObservation(_ observation: any VisionObservation, for imageSize: CGSize) -> (text: String, confidence: Float, size: CGSize, position: CGPoint) {
switch observation {
case is RecognizedTextObservation:
return processTextObservations(observation as! RecognizedTextObservation, for: imageSize)
case is BarcodeObservation:
return processBarcodeObservations(observation as! BarcodeObservation, for: imageSize)
default:
return ("", .zero, .zero, .zero)
}
}
}Let’s add another image enjoyMerge to our Asset and here is how we will use it!

struct StillImageDetection: View {
@StateObject private var visionManager = VisionManager()
@State private var imageSize: CGSize = .zero
var body: some View {
VStack(spacing: 16) {
Image("enjoyMerge")
.resizable()
.scaledToFit()
.frame(maxWidth: .infinity)
.overlay(content: {
GeometryReader { geometry in
DispatchQueue.main.async {
self.imageSize = geometry.size
}
return Color.clear
}
})
.overlay(content: {
ForEach( 0..<visionManager.observations.count, id: \.self) { index in
let observation = visionManager.observations[index]
let (text, confidence, boxSize, boxPosition) = visionManager.processObservation(observation, for: imageSize)
RoundedRectangle(cornerRadius: 8)
.stroke(.black, style: .init(lineWidth: 4.0))
.overlay(alignment: .topLeading, content: {
Text("\(text): \(confidence)")
.background(.white)
.offset(y: -28)
})
.frame(width: boxSize.width, height: boxSize.height)
.position(boxPosition)
.zIndex(1)
}
})
Button(action: {
guard let imageData = UIImage(named: "enjoyMerge")?.pngData() else { return }
Task {
await visionManager.detectBarcodeAndText(imageData)
}
}, label: {
Text("Detect Text & Barcode")
.foregroundStyle(.black)
.padding(.all)
.background(
RoundedRectangle(cornerRadius: 8)
.stroke(.black, lineWidth: 2.0))
})
}
.frame(maxWidth: .infinity, maxHeight: .infinity, alignment: .top)
.padding(.all, 32)
}
}

As you can see, the barcode works fine, however the text is not as accurate as performing a single text request by itself.
I have tried to asked the handler to only perform textRequest like following and I got the exact same result as calling RecognizeTextRequest().perform, that is Enjoy with a confidence of 0.5.
let requests: [any VisionRequest] = [textRequest]
let imageRequestHandler = ImageRequestHandler(data)
I wonder if we are just not suppose to perform requests of multiple types at the same time? If you know the reason, leave me a comment, would be HAPPY to know!
Wrap Up
Just putting our VisionManager together to wrap everything up!
import SwiftUI
import Vision
class VisionManager: ObservableObject {
@Published var observations: [any VisionObservation] = []
@MainActor
func processObservation(_ observation: any VisionObservation, for imageSize: CGSize) -> (text: String, confidence: Float, size: CGSize, position: CGPoint) {
switch observation {
case is RecognizedTextObservation:
return processTextObservations(observation as! RecognizedTextObservation, for: imageSize)
case is BarcodeObservation:
return processBarcodeObservations(observation as! BarcodeObservation, for: imageSize)
default:
return ("", .zero, .zero, .zero)
}
}
private func processTextObservations(_ observation: RecognizedTextObservation, for imageSize: CGSize) -> (text: String, confidence: Float, size: CGSize, position: CGPoint) {
let recognizedText = observation.topCandidates(1).first?.string ?? ""
let confidence = observation.topCandidates(1).first?.confidence ?? 0.0
let boundingBox = observation.boundingBox
let converted = boundingBox.toImageCoordinates(imageSize, origin: .upperLeft)
let position = CGPoint(x: converted.midX, y: converted.midY)
return (recognizedText, confidence, converted.size, position)
}
private func processBarcodeObservations(_ observation: BarcodeObservation, for imageSize: CGSize) -> (text: String, confidence: Float, size: CGSize, position: CGPoint) {
let recognizedText = observation.payloadString ?? "Payload String not available"
let confidence = observation.confidence
let boundingBox = observation.boundingBox
let converted = boundingBox.toImageCoordinates(imageSize, origin: .upperLeft)
let position = CGPoint(x: converted.midX, y: converted.midY)
return (recognizedText, confidence, converted.size, position)
}
func recognizeText(_ data: Data) async {
var request = RecognizeTextRequest()
request.recognitionLanguages = Locale.Language.systemLanguages
do {
let results = try await request.perform(on: data)
DispatchQueue.main.async {
self.observations = results
}
} catch(let error) {
print("error recognizing text: \(error.localizedDescription)")
}
}
func detectBarcode(_ data: Data) async {
var request = DetectBarcodesRequest()
request.symbologies = [.qr]
do {
let results = try await request.perform(on: data)
DispatchQueue.main.async {
self.observations = results
}
} catch(let error) {
print(error)
print("error recognizing barcode: \(error.localizedDescription)")
}
}
func detectBarcodeAndText(_ data: Data) async {
var textRequest = RecognizeTextRequest()
textRequest.recognitionLanguages = [Locale.Language.init(identifier: "en-US")]
var barcodeRequest = DetectBarcodesRequest()
barcodeRequest.symbologies = [.qr]
let requests: [any VisionRequest] = [textRequest, barcodeRequest]
let imageRequestHandler = ImageRequestHandler(data)
let results = imageRequestHandler.performAll(requests)
await handleVisionResults(results: results)
}
@MainActor
private func handleVisionResults(results: some AsyncSequence<VisionResult, Never>) async {
self.observations = []
for await result in results {
switch result {
case .recognizeText(_, let observations):
print("text")
self.observations.append(contentsOf: observations)
case .detectBarcodes(_, let observations):
print("barcode")
self.observations.append(contentsOf: observations)
default:
return
}
}
}
}
There are also a lot of other cool requests for you to check out such as
- ClassifyImageRequest to classify an image.
- CalculateImageAestheticsScoresRequest to analyze an image for aesthetically pleasing attributes.
- DetectFaceLandmarksRequest to find facial features like eyes and mouth in an image.
- DetectHumanBodyPoseRequest to detect a human body pose.
- DetectHumanHandPoseRequest to detect a human hand pose.
- DetectTrajectoriesRequest to detect the trajectories of shapes moving along a parabolic path.
- DetectContoursRequestto detect the contours of the edges of an image.
- DetectHorizonRequest: An image-analysis request that determines the horizon angle in an image.
- DetectRectanglesRequest: An image-analysis request that finds projected rectangular regions in an image.
AND MANY MORE!
I love BETA!
Thank you for reading!
That’s all I have for today!
Again, you can grab the demo app here.
If you are interested in detecting from live capture, check out one of my other articles, SwiftUI + Vision: Object detection in Live Capture!
Happy detecting!
SwiftUI+Vision: Object Detection in Still Image was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Itsuki
Itsuki | Sciencx (2024-07-28T16:38:49+00:00) SwiftUI+Vision: Object Detection in Still Image. Retrieved from https://www.scien.cx/2024/07/28/swiftuivision-object-detection-in-still-image/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.