
This content originally appeared on HackerNoon and was authored by Knapsack
:::info Authors:
(1) Keivan Alizadeh;
(2) Iman Mirzadeh, Major Contribution;
(3) Dmitry Belenko, Major Contribution;
(4) S. Karen Khatamifard;
(5) Minsik Cho;
(6) Carlo C Del Mundo;
(7) Mohammad Rastegari;
(8) Mehrdad Farajtabar.
:::
Table of Links
2. Flash Memory & LLM Inference and 2.1 Bandwidth and Energy Constraints
3.2 Improving Transfer Throughput with Increased Chunk Sizes
3.3 Optimized Data Management in DRAM
4.1 Results for OPT 6.7B Model
4.2 Results for Falcon 7B Model
6 Conclusion and Discussion, Acknowledgements and References
3.3 Optimized Data Management in DRAM
Although data transfer within DRAM is more efficient compared to accessing flash memory, it still incurs a non-negligible cost. When introducing data for new neurons, reallocating the matrix and appending new matrices can lead to significant overhead due to the need for rewriting existing neurons data in DRAM. This is particularly costly when a substantial portion (approximately 25%) of the Feed-Forward Networks (FFNs) in DRAM needs to be rewritten. To address this issue, we adopt an alternative memory management strategy. This involves the preallocation of all necessary memory and the establishment of a corresponding data structure for efficient management. The data structure comprises elements such as pointers, matrix, bias, numused, and lastk_active shown in Figure 7.
\ Each row in the matrix represents the concatenated row of the ’up project’ and the column of the ’down project’ of a neuron. The pointer vector indicates the original neuron index corresponding to each row in the matrix. The bias for the ’up project’ in the original model is represented in the corresponding bias element. The numused parameter tracks the number of rows currently utilized in the matrix, initially set to zero. The matrix for the ith layer is pre-allocated with a size of Reqi × 2dmodel, where Reqi denotes the maximum number of neurons required for the specified window size in a subset of C4 validation set. By allocating a sufficient amount of memory for each layer in advance, we minimize the need for frequent reallocation. Finally, the lastk_active component identifies the neurons from the original model that were most recently activated using the last k tokens.
\ The following operations are done during inference as depicted in Figure 7.
\

\ 2. Bringing in New Neurons: Necessary neuron data is retrieved from flash memory. The corresponding pointers and scalars are read from DRAM, and these rows are then inserted into the matrix, extending from numrow to numrow + num_new. This approach eliminates the need for reallocating memory in DRAM and copying existing data, reducing inference latency.
\ 3. Inference Process: For the inference operation, the first half of the matrix[:numrows,:dmodel] is used as the ’up project’, and the transposed second half, matrix[:numrows,dmodel:].transpose(), serves as the ’down project’. This configuration is possible because the order of neurons in the intermediate output of the feed-forward layer does not alter the final output, allowing for a streamlined inference process.
\
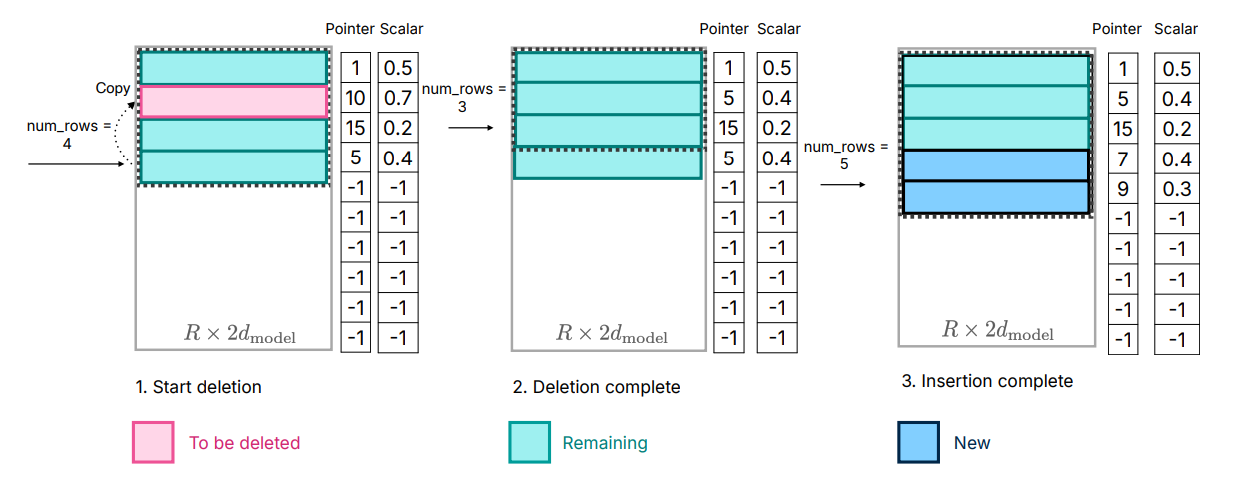
\ These steps collectively ensure efficient memory management during inference, optimizing the neural network’s performance and resource utilization.
\
:::info This paper is available on arxiv under CC BY-SA 4.0 DEED license.
:::
\
This content originally appeared on HackerNoon and was authored by Knapsack
Knapsack | Sciencx (2024-07-31T18:00:16+00:00) Large Language Models on Memory-Constrained Devices Using Flash Memory: Optimized Data in DRAM. Retrieved from https://www.scien.cx/2024/07/31/large-language-models-on-memory-constrained-devices-using-flash-memory-optimized-data-in-dram/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.