
This content originally appeared on DEV Community and was authored by Zied Ben Tahar
 on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://res.cloudinary.com/practicaldev/image/fetch/s--mVtYxz8J--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_800/https://cdn-images-1.medium.com/max/12000/0%2AIN9Eb43nUR64B1Q9)
In a previous article, I wrote about building an application capable of generating summaries from YouTube videos. It was fun to build. However, the solution was limited as it was only handling Youtube videos and relied on YouTube’s generated transcripts. I wanted to improve this solution and make it more versatile as well as supporting other media formats.
In this article, I take a different approach: Transcribing media files with Amazon Transcribe and using the generated transcripts as a knowledge base, allowing for retrieval-augmented generation with Amazon Bedrock.

RAG with Amazon Bedrock Knowledge Bases
Retrieval-Augmented Generation (RAG) improve model responses by combining information retrieval with prompt construction: When processing a query, the system first retrieves relevant data from custom knowledge bases. It then uses this data in the prompt, enabling the model to generate more accurate and contextually relevant answers.
RAG significantly improves the model’s ability to provide informed, up-to-date answers, bridging the gap between the model’s training data and custom up-to-date information.

How Bedrock can help ?
Amazon Bedrock’s Knowledge Bases simplify the RAG process by handling much of the heavy lifting. This includes synchronizing content from Amazon S3, chunking, converting it into embeddings, and storing them in vector databases. It also provides endpoints that allow applications to query the knowledge base while generating responses based on the retrieved data. By handling these tasks, Bedrock allows to focus on building AI-powered applications rather than managing infrastructure.
In this article, I will use RAG for media transcripts to generate responses based on audio or video content. These contents can be meeting recordings, podcasts, conference talks, and more.
Solution overview
The architecture of a typical RAG system consists of two components:
Knowledge base indexing and synchronisation
Retrieval and generation
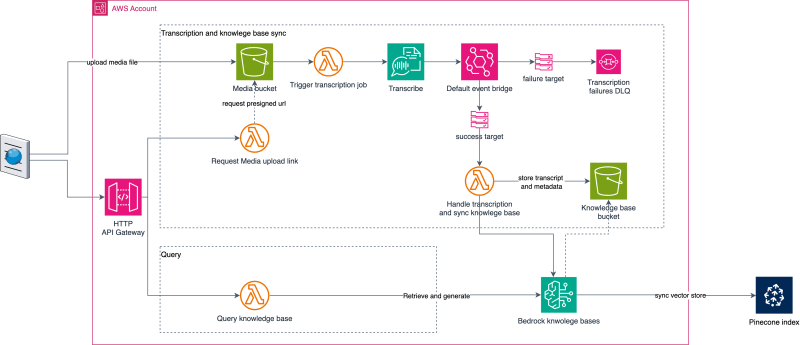
Users first request an upload link by invoking the Request Media upload link function, which generates an S3 presigned URL. The user’s request includes the media metadata such as the topic, the link to the media and date. This metadata will be stored and used downstream by Bedrock to apply filtering during the retrieval phase. When the upload process completes in the media bucket, the Start transcription job function is triggered by media bucket event notification.
When a transcription job state changes, EventBridge will publish job completion status events (Success or Failure). The Handle transcription and sync knowledge base function handles only successful events, extracts the transcription content, stores the extracted text transcript in the knowledge base bucket, and triggers a knowledge base sync.
The vector database is an important part of a RAG system. It stores and retrieves text representations as vectors (also known as embeddings). allowing for similarity searches when given a query. Bedrock supports various vector databases, including Amazon OpenSearch, PostgreSQL with the pgvector extension, and Pinecone. Each option has its advantages. In this solution, I chose Pinecone as it is a serverless service that allows for quick and easy setup.
When using Knowledge Bases, the Model used for generating embeddings can differ from the one used for response generation. For example, in this sample, I use “Amazon Titan Text embedding v2” for embedding and “Claude 3 Sonnet” for response generation.
☝️Note: In this article, I did not include the parts that handle transcription job monitoring and asynchronous job progress notifications to the requester. For insights on building an asynchronous REST APIs, you can refer to this previous article.
Alright, let’s deep dive into the implementation
Solution Details
This time, I am taking a different approach compared to my previous articles: I will be using Rust for lambda code and terraform for IaC.
1- Creating the Pinecone vector database
I try to do IaC whenever possible. The good news is that Pinecone offers a Terraform provider, which simplifies managing Pinecone indexes and collections as code. First we’ll need an API Key:

Here, I am using the serverless version of Pinecone. We need to set the PINECONE_API_KEY environment variable to the API key we just created so that it can be used by the provider.
2- Creating the knowledge base
Creating the knowledge base involves defining two key components: the vector store configuration, which points to Pinecone, and the data source.
The data source dictates how the content will be ingested, including the storage configuration and the content chunking strategy.
For the data source, I am setting the chunking strategy to
FIXED_SIZE
After deployment, you will be able to view in the console the data source configuration:

3- Requesting Media upload link
This function is invoked by the API Gateway to generate a presigned URL for media file uploads. A unique identifier is assigned to the object, which will also serve as the transcription job name and as the reference for the knowledge base document.
The request is validated to ensure that the media metadata properties are properly defined. I am using the
serde_valid crate to validate the request payload. This crate is very convenient for defining schema validations using attributes.And here is are details of the generate_presigned_request_uri
4- Handling media upload and starting transcription job
This function is triggered by an S3 event whenever a new file is successfully uploaded. As a convention, I am using the media object key as the transcription job name which is the unique identifier of the task.
This function needs
transcribe:startTranscriptionJob permission in order to be able to start a transcription task.
Once the task is started, we can monitor the transcription job process in the console:

5- Subscribing to transcription success events and syncing knowledge base
Let’s first have a look into the event bridge rule definition in terraform:
Which translates to the following configuration in the AWS console:

Here, the Handle successful transcription function is invoked each time a transcription is successfully completed. I am only interested in having the transcription job name, as I will use it as the data source object key:
This function first retrieves the transcription result content available at the
transcript_file_uri, extracts the important part and stores it in the knowledge base bucket as well as its metadata and then triggers a start_ingestion_job. If the operation fails, it will be retried by EventBridge and eventually put into a dead letter queue.
☝️**Note: **I opted against using a step function for this part since the transcribe output could exceed 256 KB.
6- Chatting with the knowledge base in the console
Before building the function that queries the knowledge base, we can already test it from the console. I used this awesome first believe in serverless podcast episode as a data source:
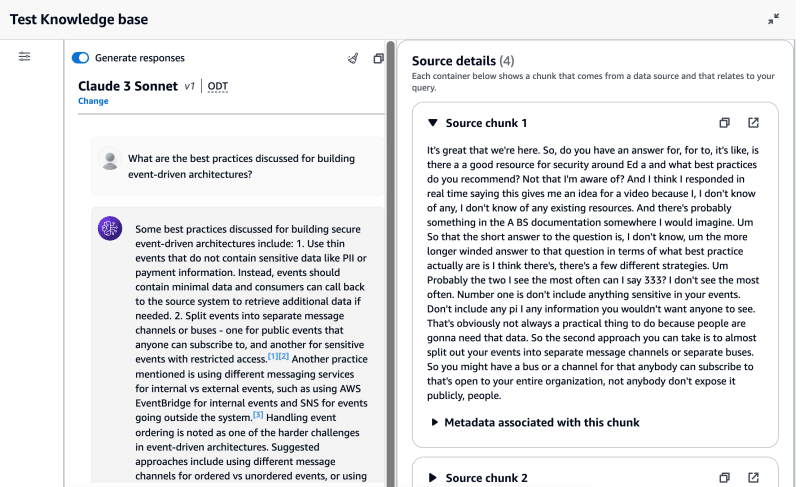
The console also provides a way to test and adjust the generation configuration, including choosing the model, using a custom prompt, and adjusting parameters like temperature, top-p. This allows you to tailor the configuration to your specific use case requirements.
Alright, let’s now create the endpoint to see how we can query this knowledge base
7- Querying the knowledge base
This function requires the bedrock:RetrieveAndGenerate permission for accessing the knowledge base and the bedrock:InvokeModel permission for the Claude 3 sonnet model arn used during the generation phase. It returns an output result along with the source URL associated with the retrieved chunks that contributed to the output:
The
build_retrieve_and_generate_configuration function prepares the necessary parameters for calling the retrieveAndGenerate endpoint.
As an example, I am applying a retrieval filter to the topic attribute.
Et voilà ! Let’s call our api straight from postman

Wrapping up
I’ve only scratched the surface when it comes to building RAG systems. Bedrock simplifies the process considerably. There’s still plenty of room for improvement, such as optimising retrieval methods and refining prompts. I had also fun building this in Rust — using Cargo Lambda makes creating Lambdas in Rust a breeze, check it-out!
As always, you can find the full code source, ready to be adapted and deployed here:
ziedbentahar/rag-on-media-content-with-bedrock-and-transcribe
Thanks for reading ! Hope you enjoy it
Resources
Amazon Web Services (AWS) - Pinecone Docs
Rust functions on AWS Lambda made simple
Create a knowledge base
This content originally appeared on DEV Community and was authored by Zied Ben Tahar
Zied Ben Tahar | Sciencx (2024-08-01T15:45:55+00:00) Using RAG on media content with Bedrock Knowledge Bases and Amazon Transcribe. Retrieved from https://www.scien.cx/2024/08/01/using-rag-on-media-content-with-bedrock-knowledge-bases-and-amazon-transcribe/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.