
This content originally appeared on Level Up Coding - Medium and was authored by Saarthak Gupta
In the past, we discussed different unsupervised clustering methods like K-Means, DBSCAN, GMM, and data visualization techniques such as t-SNE in the Unsupervised Learning List. We are now moving on to exploring unsupervised deep-learning techniques.
In this article you will get an in-depth understanding of :
- What are AutoEncoders?
- Use Cases of AutoEncoder.
- Different Types of AutoEncoders
- Implementation of AutoEncoders using Tensorflow and Keras.
What are Auto Encoders?
Auto Encoders are unsupervised neural networks. An autoencoder is a type of neural network architecture designed to compress (encode) efficiently input data down to its essential features, and then reconstruct (decode) the original input from this compressed representation.
During training, AEs aim to minimize a reconstruction loss, which quantifies how well the decoder can recreate the original input from the latent space representation. This loss encourages the AE to learn meaningful features from the data.
So, an autoencoder is a type of neural network architecture that attempts to reconstruct its input data as well as possible(minimize reconstruction error i.e. the loss between the input and the output ).
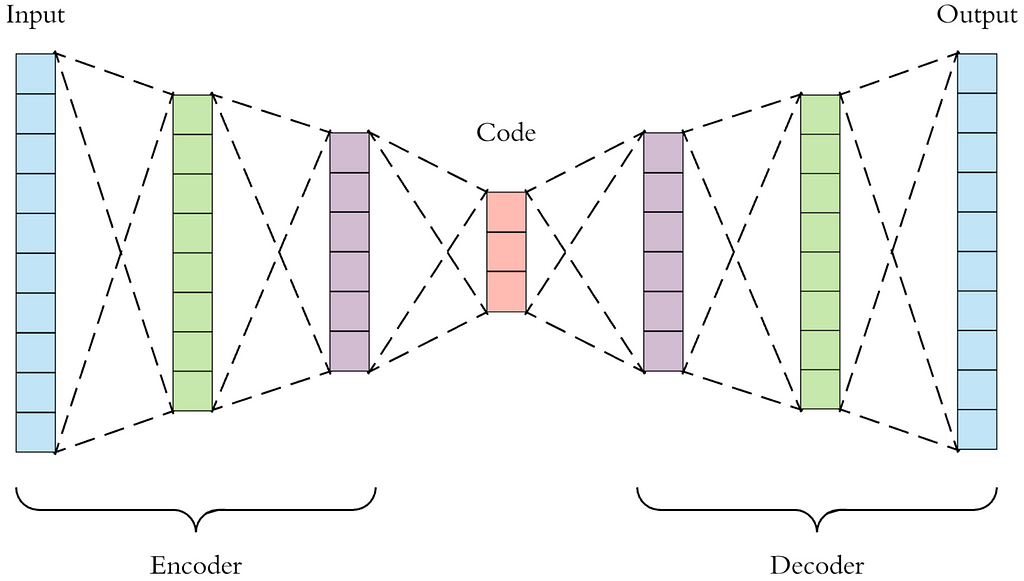
In AutoEncoders, each layer of the neural network learns a representation of the original features(input), and the subsequent layer builds on the representation learned by the preceding layer. Layer by layer the autoencoders learn increasingly complicated representations from simpler ones.
Autoencoders refer to a specific subset of encoder-decoder architectures that are trained via unsupervised learning to reconstruct their input data.
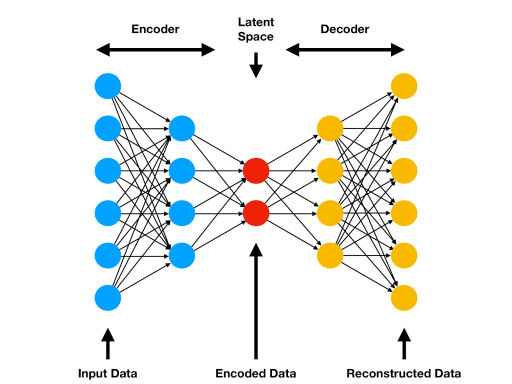
Latent Space: Represents the compressed form of the input data, typically with the lowest dimensionality.
An AutoEncoder consists of two parts :
1. Encoder: converts the input set of features into a simple representation(Latent Space).
2. Decoder: converts this newly learned representation(Latent Space) to the original format.
AutoEncoders learn the most Salient properties of the original data capturing the underlying structure of the data. (similar to dimensionality reduction.)
Like supervised learning models and unlike most examples of unsupervised learning — autoencoders have a ground truth to measure their output against the original input itself (or some modified version of it). For that reason, they are considered “self-supervised learning”–hence, autoencoder.
What are AutoEncoders used for?
Autoencoders come in different types and are commonly used in artificial intelligence for tasks such as feature extraction, data compression, image denoising, anomaly detection, and facial recognition. Variational autoencoders (VAEs) and adversarial autoencoders (AAEs) are specific types of autoencoders that are designed for generative tasks, such as creating images or generating time series data.

- Dimensionality Reduction: Similar to PCA, autoencoders can reduce data dimensions while preserving important features.
- Anomaly Detection: By learning to reconstruct normal data, autoencoders can identify anomalies as poorly reconstructed inputs.
- Denoising: Denoising autoencoders can clean noisy data by learning to map corrupted inputs to clean outputs.
- Image Compression: Autoencoders can compress images into lower-dimensional representations.
- Generative Models: VAEs can generate new data samples by sampling from the learned data distribution.
What are the different types of AutoEncoders?
1. Under Complete AutoEncoders
We can limit the output of the encoder function to have fewer dimensions than x, which is known as undercomplete autoencoders or bottleneck autoencoders. The purpose of this bottleneck is to prevent the autoencoder from overfitting its training data. If the bottleneck’s capacity is not limited enough, the network may learn to simply copy the input instead of extracting useful features. When the data is significantly compressed, the neural network is forced to keep only the most important features for reconstruction.
We can improve under complete autoencoders by using regularization techniques. These techniques constrain or modify the way the model calculates reconstruction error. Regularization terms not only prevent overfitting but also help the autoencoder learn beneficial features or functions.
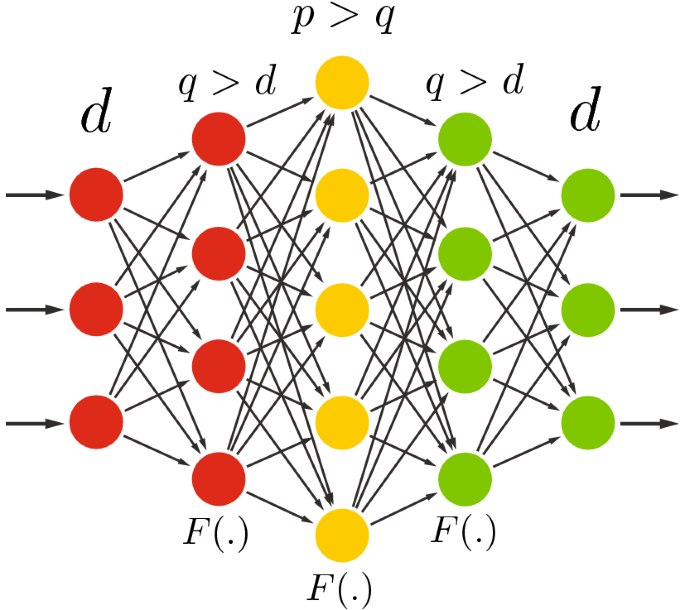
2. Over Complete AutoEncoders
If the encoder learns representations in a greater number of dimensions than the original input dimensions, the autoencoder is considered an overcomplete autoencoder or sparse autoencoder. They have more nodes in the hidden layer than either the input or the output layer and because the capacity of this neural network is so high the autoencoder simply memorizes the observations it is trained on.
One way to reduce overfitting in sparse autoencoders is to use regularization techniques like dropout. With dropout, we force autoencoders to drop some defined percentage of nodes from the layers in the neural network.
Another regularization technique that can be used is sparsity. It ensures that only a small number of neurons are active (i.e., have non-zero values) for any given input by adding penalties (e.g., L1 regularization or KL divergence) to the loss function. This forces the network to learn more efficient and meaningful representations by focusing on the most important features.
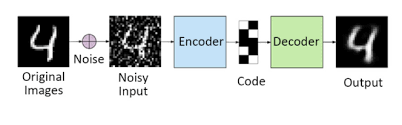
3. Denoising AutoEncoders (DAE)
Denoising autoencoders are a type of neural network specifically designed to take partially corrupted input data and learn to reconstruct the original, uncorrupted input. They achieve this by reducing the dimensionality of the input data and removing irrelevant information. What sets denoising autoencoders apart from most other autoencoders is that they do not receive the original, uncorrupted data as input during training. Instead, they are trained on data that has been intentionally corrupted by adding Gaussian noise.
To better understand this, consider adding random static to an image. The denoising autoencoder (DAE) is trained to recognize and filter out this noise, ultimately learning to reconstruct a clean version of the original image.
It’s important to note that during the training process, the denoising autoencoder evaluates the accuracy of its reconstructions by comparing them to the original, uncorrupted input data rather than the intentionally corrupted input.
4. Contractive AutoEncoders (CAE)
contractive autoencoders are designed to be insensitive to minor variations (or “noise”) in input data to reduce overfitting and more effectively capture essential information.
This is achieved by adding a regularization term in training, penalizing the network for changing the output in response to insufficiently large changes in the input.
5. Variational Autoencoders (VAE)
Variational autoencoders (VAEs) are generative models that compress their training data into probability distributions. These distributions can then generate new sample data by creating variations of the learned representations.
The key difference between VAEs and other types of autoencoders is that while most autoencoders learn discrete latent space models, VAEs learn continuous latent variable models. Instead of a single encoding vector for latent space, VAEs model two different vectors: a vector of means, “μ,” and a vector of standard deviations, “σ.” By capturing latent attributes as a probability distribution, VAEs learn a stochastic encoding rather than a deterministic encoding. This allows for interpolation and random sampling, expanding their capabilities and use cases significantly. In essence, VAEs are generative AI models.
Although I’ve attempted to capture the essence of VAEs, it’s a complex topic in its own right and can be further explored.
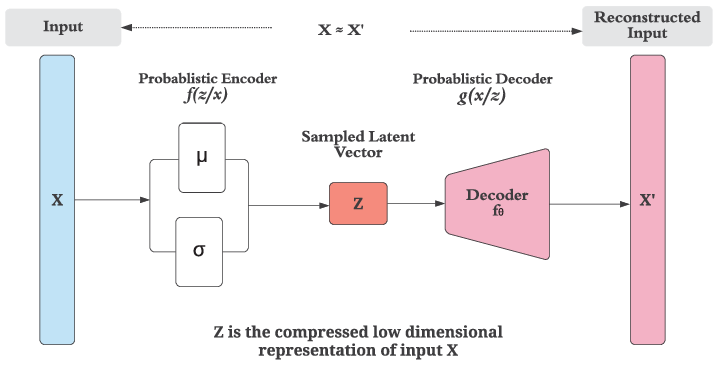
Implementation in Python using Tensorflow and Keras
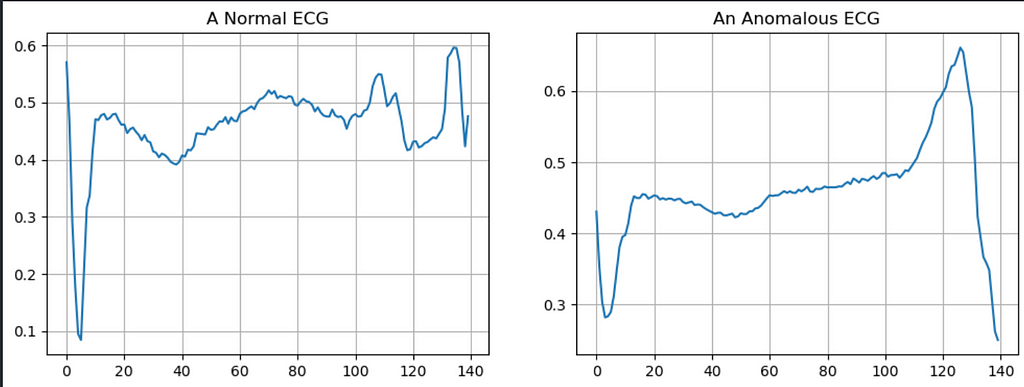
In this example, you will train an autoencoder to detect anomalies on the ECG5000 dataset. This dataset contains 5,000 Electrocardiograms, each with 140 data points. You will use a simplified version of the dataset, where each example has been labeled either 0 (corresponding to an abnormal rhythm) or 1 (corresponding to a normal rhythm). You are interested in identifying the abnormal rhythms.
an autoencoder is trained to minimize reconstruction error. You will train an autoencoder on the normal rhythms only, and then use it to reconstruct all the data. we hypothesize that the abnormal rhythms will have higher reconstruction errors. You will then classify a rhythm as an anomaly if the reconstruction error surpasses a fixed threshold.
# Download the dataset
dataframe = pd.read_csv('http://storage.googleapis.com/download.tensorflow.org/data/ecg.csv', header=None)
raw_data = dataframe.values
dataframe.head()

# The last element contains the labels
labels = raw_data[:, -1]
# The other data points are the electrocadriogram data
data = raw_data[:, 0:-1]
train_data, test_data, train_labels, test_labels = train_test_split(
data, labels, test_size=0.2, random_state=21
)
## Normalizing the data
min_val = tf.reduce_min(train_data)
max_val = tf.reduce_max(train_data)
train_data = (train_data - min_val) / (max_val - min_val)
test_data = (test_data - min_val) / (max_val - min_val)
train_data = tf.cast(train_data, tf.float32)
test_data = tf.cast(test_data, tf.float32)
'''You will train the autoencoder using only the normal rhythms, which are labeled in this dataset as 1.
Separate the normal rhythms from the abnormal rhythms.'''
train_labels = train_labels.astype(bool)
test_labels = test_labels.astype(bool)
normal_train_data = train_data[train_labels]
normal_test_data = test_data[test_labels]
anomalous_train_data = train_data[~train_labels]
anomalous_test_data = test_data[~test_labels]
# Create a figure with two subplots in a single row
fig, axs = plt.subplots(1, 2, figsize=(12, 4))
# Plot the normal ECG
axs[0].plot(np.arange(140), normal_train_data[0])
axs[0].set_title("A Normal ECG")
axs[0].grid()
# Plot the anomalous ECG
axs[1].plot(np.arange(140), anomalous_train_data[0])
axs[1].set_title("An Anomalous ECG")
axs[1].grid()
# Display the plots
plt.show()
class AnomalyDetector(Model):
def __init__(self):
super(AnomalyDetector, self).__init__()
self.encoder = tf.keras.Sequential([
layers.Dense(32, activation="relu"),
layers.Dense(16, activation="relu"),
layers.Dense(8, activation="relu")])
self.decoder = tf.keras.Sequential([
layers.Dense(16, activation="relu"),
layers.Dense(32, activation="relu"),
layers.Dense(140, activation="sigmoid")])
def call(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
autoencoder = AnomalyDetector()
autoencoder.compile(optimizer='adam', loss='mae')
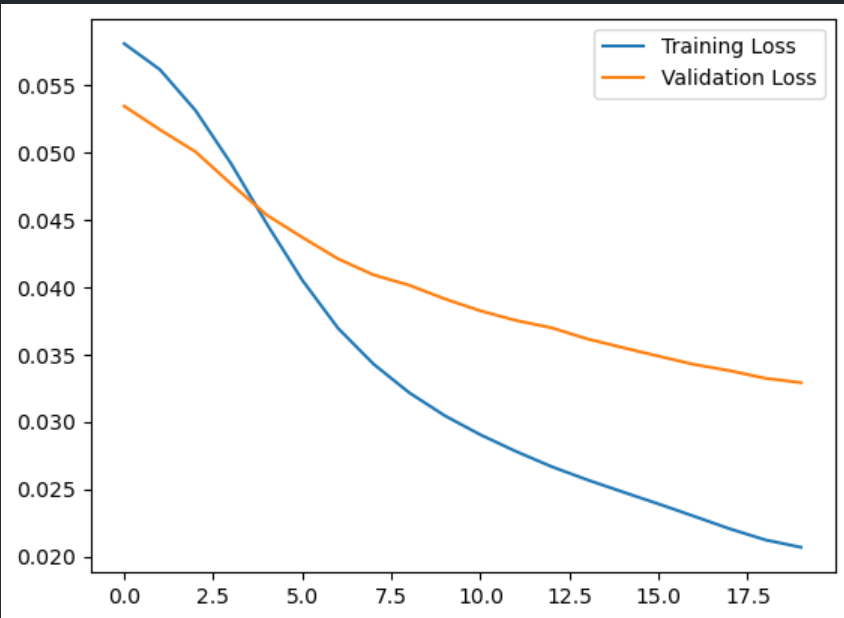
history = autoencoder.fit(normal_train_data, normal_train_data,
epochs=20,
batch_size=512,
validation_data=(test_data, test_data),
shuffle=True)
plt.plot(history.history["loss"], label="Training Loss")
plt.plot(history.history["val_loss"], label="Validation Loss")
plt.legend()
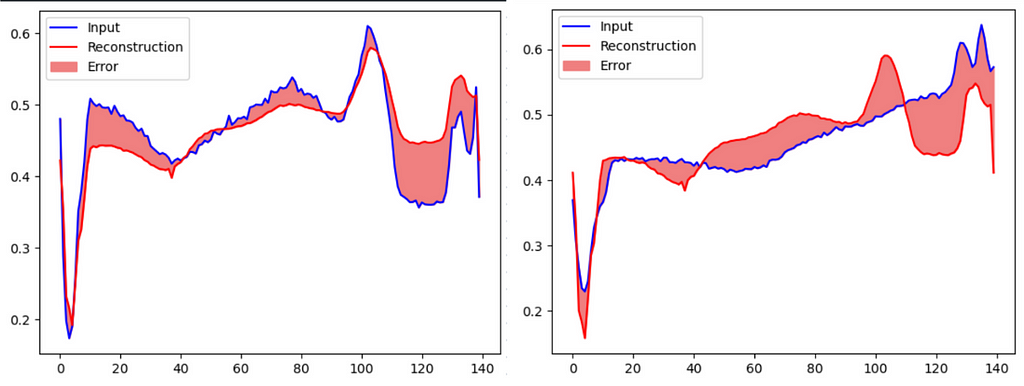
encoded_data = autoencoder.encoder(normal_test_data).numpy()
decoded_data = autoencoder.decoder(encoded_data).numpy()
plt.plot(normal_test_data[0], 'b')
plt.plot(decoded_data[0], 'r')
plt.fill_between(np.arange(140), decoded_data[0], normal_test_data[0], color='lightcoral')
plt.legend(labels=["Input", "Reconstruction", "Error"])
plt.show()
encoded_data = autoencoder.encoder(anomalous_test_data).numpy()
decoded_data = autoencoder.decoder(encoded_data).numpy()
plt.plot(anomalous_test_data[0], 'b')
plt.plot(decoded_data[0], 'r')
plt.fill_between(np.arange(140), decoded_data[0], anomalous_test_data[0], color='lightcoral')
plt.legend(labels=["Input", "Reconstruction", "Error"])
plt.show()
'''Detect anomalies by calculating whether the reconstruction loss is greater than a fixed threshold.
In this tutorial, you will calculate the mean average error for normal examples from the training set, then classify future examples as anomalous if
the reconstruction error is higher than one standard deviation from the training set.'''
reconstructions = autoencoder.predict(normal_train_data)
train_loss = tf.keras.losses.mae(reconstructions, normal_train_data)
plt.hist(train_loss[None,:], bins=50)
plt.xlabel("Train loss")
plt.ylabel("No of examples")
plt.show()
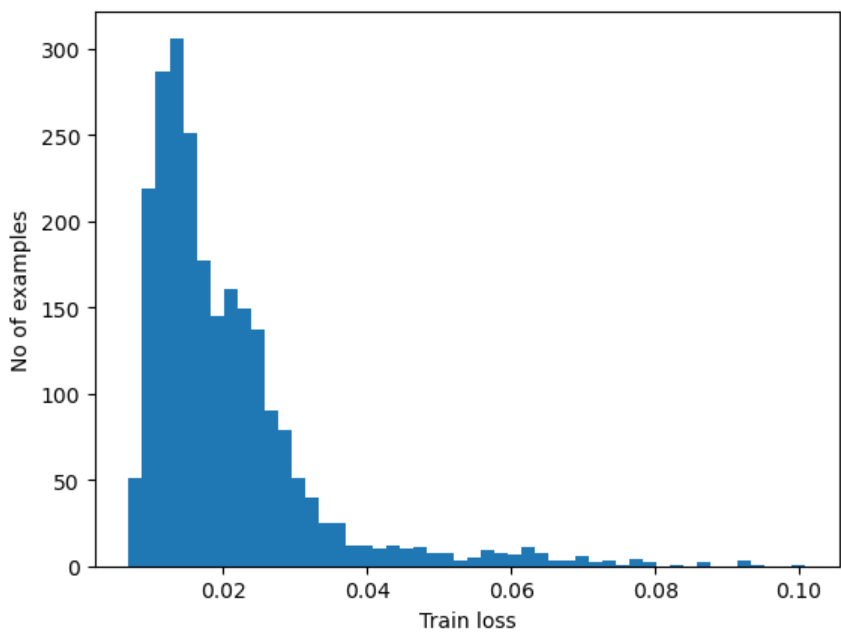
#Choose a threshold value that is one standard deviations above the mean.
threshold = np.mean(train_loss) + np.std(train_loss)
print("Threshold: ", threshold)
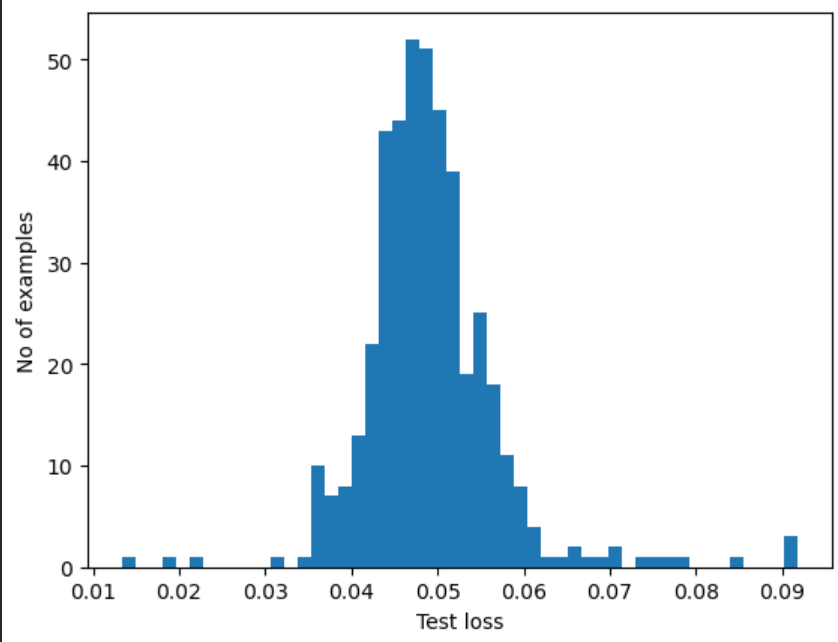
reconstructions = autoencoder.predict(anomalous_test_data)
test_loss = tf.keras.losses.mae(reconstructions, anomalous_test_data)
plt.hist(test_loss[None, :], bins=50)
plt.xlabel("Test loss")
plt.ylabel("No of examples")
plt.show()
def predict(model, data, threshold):
reconstructions = model(data)
loss = tf.keras.losses.mae(reconstructions, data)
return tf.math.less(loss, threshold)
def print_stats(predictions, labels):
print("Accuracy = {}".format(accuracy_score(labels, predictions)))
print("Precision = {}".format(precision_score(labels, predictions)))
print("Recall = {}".format(recall_score(labels, predictions)))
preds = predict(autoencoder, test_data, threshold)
print_stats(preds, test_labels)
'''
Accuracy = 0.944
Precision = 0.9921875
Recall = 0.9071428571428571
'''
Unsupervised Deep Learning using Auto Encoders was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Saarthak Gupta
Saarthak Gupta | Sciencx (2024-08-14T11:20:12+00:00) Unsupervised Deep Learning using Auto Encoders. Retrieved from https://www.scien.cx/2024/08/14/unsupervised-deep-learning-using-auto-encoders/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.