
This content originally appeared on HackerNoon and was authored by Tech Media Bias [Research Publication]
Table of Links
3 End-to-End Adaptive Local Learning
3.1 Loss-Driven Mixture-of-Experts
3.2 Synchronized Learning via Adaptive Weight
4 Debiasing Experiments and 4.1 Experimental Setup
4.3 Ablation Study
4.4 Effect of the Adaptive Weight Module and 4.5 Hyper-parameter Study
6 Conclusion, Acknowledgements, and References
4.3 Ablation Study
Next, we aim to investigate the effectiveness of different components in the proposed framework, including the proposed adaptive loss-driven gate module, the adaptive weight module, the gap mechanism in the adaptive weight module, and the loss change mechanism in the adaptive weight module.
\ Adaptive Loss-Driven Gate. To verify the effectiveness of the proposed adaptive loss-driven gate module in the proposed TALL, we compare the MoE component with the adaptive loss-driven gate (denoted as LMoE, which is the TALL model without the adaptive weight module) to a conventional MoE (denoted as MoE) with the standard multilayer perceptron (MLP) as the gate learning from
\

\
\ the dataset. By comparing LMoE and MoE, we can justify the effect of the proposed adaptive loss-driven gate. The results are present in Table 3, where we also include the result of MultVAE as a baseline. From the table, we can observe that MoE produces better performance for niche users compared to MultVAE but worse results for other users. This is caused by the MLP-based gate model in MoE, which cannot precisely allocate gate values to expert models to ensemble a strong customized model for different users. Conversely, we can see that even without the adaptive weight module, the LMoE can deliver greatly higher utilities for all types of users compared to MultVAE and MoE, showing the strong capability of the proposed adaptive loss-driven gate module in distributing gate values across expert models. And this result also demonstrates the efficacy of the proposed LMoE module in TALL in terms of addressing the discrepancy modeling problem.
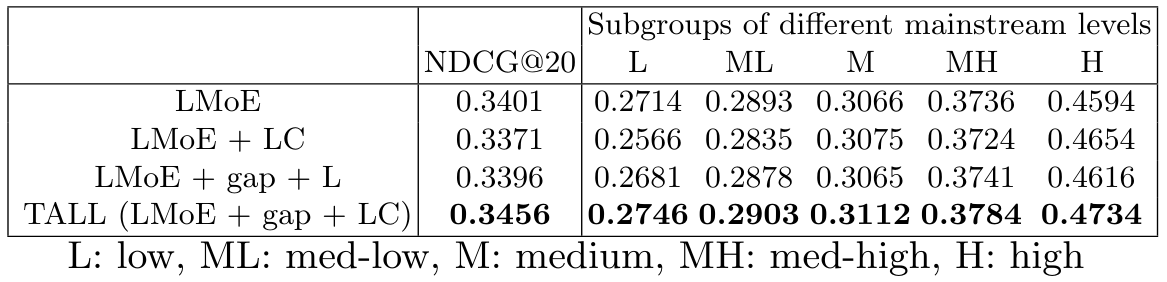
\ Adaptive Weight. To address the unsynchronized learning problem, we develop the adaptive weight module to dynamically adjust the learning paces of different users. To verify the effectiveness of the proposed adaptive weight, we compare the complete TALL algorithm (with both the loss-driven MoE module and the adaptive weight module) to the loss-driven MoE module (LMoE). The results on ML1M are shown in Table 4, from which we can see that TALL outperforms LMoE for all types of users, manifesting the effectiveness of the proposed adaptive weight method. Furthermore, we explore the effectiveness of two special mechanisms, the gap mechanism and the loss change mechanism within the adaptive weight module, in the subsequent sections.
\ Gap Mechanism. To avoid the unstable loss problem at the initial training stage, we propose to have a gap for the adaptive weight method, i.e., we wait for a certain number of epochs at the initial training stage until the loss is stable and then apply the adaptive weight method. To verify the effectiveness of such a gap strategy, we compare the complete TALL (with a full version of the adaptive weight module including both the gap mechanism and the loss change mechanism) to a variation of TALL with the adaptive weight module without the gap mechanism. The comparison is presented in Table 4 as LMoE+LC vs. TALL. We can observe that the gap mechanism does have a significant influence on the model performance that the model with the gap mechanism (TALL) delivers better utilities for all types of users than the model without the gap mechanism (LMoE+LC).
\ Loss Change Mechanism. Last, we aim to verify the effectiveness of the proposed loss change mechanism in the adaptive weight module. The goal of loss change is to counter the scale diversity problem when applying the adaptive weight module. Here, we compare the complete TALL (with a full version of the adaptive weight module including both the gap mechanism and the loss change mechanism) to a variation of TALL (LMoE+gap+L) with the adaptive weight module that uses original loss as introduced in Section 3.2. From the comparison result shown in Table 4, we see that the model using loss change (TALL) performs better than the model using original loss for calculating weights (LMoE+gap+L). TALL outperforms LMoE+gap+L for all types of users.
\ In sum, by a series of comparative analyses, we show that the proposed adaptive loss-driven gate module, adaptive weight module, the gap mechanism in adaptive weight, and the loss change mechanism in adaptive weight are effective and play imperative roles in the proposed TALL framework.
\
:::info Authors:
(1) Jinhao Pan [0009 −0006 −1574 −6376], Texas A&M University, College Station, TX, USA;
(2) Ziwei Zhu [0000 −0002 −3990 −4774], George Mason University, Fairfax, VA, USA;
(3) Jianling Wang [0000 −0001 −9916 −0976], Texas A&M University, College Station, TX, USA;
(4) Allen Lin [0000 −0003 −0980 −4323], Texas A&M University, College Station, TX, USA;
(5) James Caverlee [0000 −0001 −8350 −8528]. Texas A&M University, College Station, TX, USA.
:::
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\
This content originally appeared on HackerNoon and was authored by Tech Media Bias [Research Publication]
Tech Media Bias [Research Publication] | Sciencx (2024-08-21T18:00:26+00:00) Countering Mainstream Bias via End-to-End Adaptive Local Learning: Ablation Study. Retrieved from https://www.scien.cx/2024/08/21/countering-mainstream-bias-via-end-to-end-adaptive-local-learning-ablation-study/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.