
This content originally appeared on DEV Community and was authored by Daniel Griffin
In this guide, we will show how to use Firecrawl and Trieve to build search and RAG for SigNoz's documentation in both Python and JS.
Firecrawl's REST API can be queried to convert every page available at a URL into vector search and RAG-ready markdown.
Trieve's API can then receive chunks of the markdown docs, embed and place them into a search index, and finally be called to perform AI Search and RAG on all of the site's content.
All the code used (both node.js and Python) is also in this GitHub repo (MIT license): firecrawl-to-trieve.
Requirements - free API keys:
- Firecrawl API key: Signup at firecrawl.dev
- Trieve API key and dataset id: Register and setup at dashboard.trieve.ai
Setup a .env file with:
FIRECRAWL_API_KEY=
TRIEVE_DATASET_ID=
TRIEVE_API_KEY=
1. Converting Signoz docs to Markdown Chunks with Firecrawl
Firecrawl Docs & Github (see also their js-sdk and python-sdk)
We use Firecrawl to convert the pages on https://signoz.io/docs/ into markdown then save them to a json file (with a timestamp). You can adjust the crawler limit (there are only 303 pages so it falls within the free credits plan).
import FirecrawlApp from '@mendable/firecrawl-js';
import dotenv from 'dotenv';
import { fileURLToPath } from 'url';
import path from 'path';
import fs from 'fs';
const __filename = fileURLToPath(import.meta.url);
const __dirname = path.dirname(__filename);
dotenv.config({ path: path.resolve(__dirname, '../.env') });
// Initialize the FirecrawlApp with your API key
const app = new FirecrawlApp({ apiKey: process.env.FIRECRAWL_API_KEY });
// Define crawl parameters
const crawlUrl = 'https://signoz.io/docs/';
const params = {
crawlerOptions: {
limit: 500,
maxDepth: 10,
includes: ['docs/*'],
},
pageOptions: {
onlyMainContent: true
}
};
// Crawl the website
const crawlResult = await app.crawlUrl(
crawlUrl,
params,
true, // wait_until_done
2 // poll_interval
);
// Save the crawl result to a file (with a timestamp)
const timestamp = new Date().toISOString().replace(/:/g, '-').slice(0, -5);
fs.writeFileSync(`crawl_results_${timestamp}.json`,
JSON.stringify(crawlResult, null, 2));
Cleaning the Markdown
Each crawl result item has a markdown field that contains the full markdown text of the page. We did some initial data cleaning as we took our first look at the data and worked out the chunking. You can always add more cleaning later. We cut boilerplate from the end and transformed how links were presented in the metadata. This was done through tested functions that we can easily add to as we start searching.
Initial cleaning functions are in cleaners.py / cleaners.js, imported into the transform scripts.
Chunking the Markdown
For a baseline chunking approach we just want to find ways to split pages into smaller chunks, while maintaining some semantic cohesion within the chunks. Just as with cleaning, we can always refine our chunking strategy as we gain more familarity with the data and our use cases.
Learn more about chunking techniques in Greg Kamradt's "5 Levels Of Text Splitting" Notebook and Maria Khalusova's "Chunking for RAG: best practices"
Our transform script first makes chunks of any page that is less than 500 words (though this could easily be switched for a token-based limit based on the LLM of your RAG system). Then it splits longer content into chunks by top-level anchor links (e.g. [](#overview)\nOverview ) and then splitting by h3, h4, etc (e.g. ### [](#step-1-setup-otel-collector)\n). (Explicit h1-h2 (i.e. # this-is-h1 and ## this-is-h2) headings for this dataset are not indicated in the markdown. The html itself has h2 headings for both the page title and for what is rendered here as the top-level anchor link headings but it is not represented with # here.)
This transform script uses regex to recursively split longer markdown content whenever the output was greater than max_words (we used 500, determined via a crude split on whitespace) or until the split is at the max_depth (we used h4). So some chunks are longer than 500 words (25 of 972). We can later investigate lower heading-level splits, alternative split points, or manual edits for those chunks.
function processContent(pageMarkdown, pageTitle, pageLink, pageTagsSet,
pageDescription, maxWords = CONFIGS.maxWords, maxDepth = CONFIGS.maxDepth) {
// Splits content into sections based on headings
function splitContent(content, pattern) {
const matches = content.match(new RegExp(pattern, 'g')) || [];
return matches.map((match, i) => {
const [, headingLink, headingText] = match.match(pattern);
const start = content.indexOf(match);
const end = i === matches.length - 1 ? content.length : content.indexOf(matches[i + 1]);
return [headingLink, headingText, content.slice(start, end)];
});
}
// Creates chunks from sections
function createChunks(sections, currentTitle = '', depth = 0) {
const localChunks = [];
let lastChunkHeadingOnly = false;
sections.forEach(([headingLink, headingText, sectionContent]) => {
if (lastChunkHeadingOnly) {
headingText = `${lastChunkHeadingOnly} - ${headingText}`;
lastChunkHeadingOnly = false;
}
const chunkHtml = getChunkHtml(sectionContent, pageTitle, headingText, 0, null);
if (chunkHtml === "HEADING_ONLY") {
lastChunkHeadingOnly = headingText;
return;
}
const fullTitle = `${currentTitle}: ${headingText}`.replace(/^:\s+/, '');
const chunkWordCount = chunkHtml.split(/\s+/).length;
const isWithinChunkingConstrains = chunkWordCount <= maxWords || depth >= maxDepth;
// true if the chunk is within the word limit or we've reached max depth.
// we don't split further at max depth, even if over word limit
if (isWithinChunkingConstrains) {
localChunks.push(createChunkObject(chunkHtml, pageLink, headingLink, headingText,
pageTagsSet, pageTitle, pageDescription, fullTitle));
} else {
const subsections = splitContent(sectionContent,
/(\\n###+ \\[\\]\\((#.*?)\\))\\n(.*?)\\n/);
// regex to find subsections of the current section
if (subsections.length > 0) {
localChunks.push(...createChunks(subsections, fullTitle, depth + 1));
} else {
// if no subsections, create a chunk for the current section
localChunks.push(createChunkObject(chunkHtml, pageLink, headingLink, headingText,
pageTagsSet, pageTitle, pageDescription, fullTitle));
}
}
});
return localChunks;
}
const topSections = splitContent(pageMarkdown, /(\\n\\[\\]\\((#.*?)\\))\\n(.*?)\\n/);
return createChunks(topSections);
}
We also take the heading itself and add it at the top of the chunk along with the original page title.
- Example: The chunk for the "Enable a Prometheus Receiver" heading on the "Send Metrics to SigNoz Cloud" page is titled: "Send Metrics to SigNoz Cloud: Enable a Prometheus Receiver"
If the split results in a chunk consists of only a heading (HEADING_ONLY), that chunk is skipped and the heading is added to the top of the subsequent chunk.
Preparing the Chunks for Trieve
The chunk will include various other fields, metadata and labels specific for Trieve:
-
tracking_id: parsed from the URL + the id of the heading for splits -
group_tracking_ids: parsed from the URL (this will let us link the page chunks together) -
tag_set: parsed from the URL segments (ex.https://signoz.io/docs/install/kubernetes/->['install', 'kubernetes']; optimized for filtering) -
image_urls: parsed from the markdown (the docs have bothpngandwebpimages; this will show within the Trieve search playground) -
metadata: parsed from the crawl result metadata (we save the page title and description (if it exists), in case useful later; can be filtered)
function createChunk(chunkHtml, pageLink, headingLink, headingText, pageTagsSet,
pageTitle, pageDescription) {
const chunk = {
chunk_html: chunkHtml,
link: pageLink + headingLink,
tags_set: pageTagsSet,
image_urls: getImages(chunkHtml),
tracking_id: getTrackingId(pageLink + headingLink),
group_tracking_ids: [getTrackingId(pageLink)],
timestamp: TIMESTAMP,
metadata: {
title: pageTitle + ': ' + headingText,
page_title: pageTitle,
page_description: pageDescription,
}
};
return chunk;
The groups are automatically created in Trieve for each tracking ID in the group_tracking_ids array if a group with that tracking ID does not yet exist. Groups can be created (and edited) in the chunk_group route. This lets you provide a name, description, tag_set and metadata for the group. See the docs: Create or Upsert Group or Groups
2. Storing the Chunks in Trieve for Search and RAG
We use the Trieve api/chunk route to create the chunks in Trieve.
See the docs: Create or Upsert Chunk or Chunks
Chunks here are just parsed JSON in batches of 120.
async function loadChunks(chunks, config, upsert = false) {
const url = `${config.basePath}/api/chunk`;
const headers = {
"TR-Dataset": config.datasetId,
"Authorization": `Bearer ${config.apiKey}`,
"Content-Type": "application/json"
};
chunks.forEach(chunk => chunk.upsert_by_tracking_id = upsert);
try {
const { data } = await axios.post(url, chunks, { headers });
console.log(`Successfully ${upsert ? 'upserted' : 'created'} batch of ` +
`${chunks.length} chunks to ${config.datasetId}`);
return data;
} catch (error) {
console.error(`Failed to ${upsert ? 'upsert' : 'create'} batch. ` +
`Status: ${error.response?.status}, ` +
`Data: ${JSON.stringify(error.response?.data)}, ` +
`Message: ${error.message}`);
throw error;
}
}
Testing Search and RAG quality using Trieve Playgrounds
Trying out some searches and chatting with the chunks is one way to get a look at your data and the quality of your initial cleaning and chunking steps.
After loading the chunks you can head to dashboard.trieve.ai. Here you'll find a datasets table with your ingested dataset, listing the number of chunks along with quicklinks to settings and the search, RAG, and analytics playgrounds. Both the Search and RAG Playgrounds show the chunks with their chunk_html, the links to their source pages, tracking IDs, and metadata.
Search Playground: search.trieve.ai
This is a search interface optimized for fully exploring the search options in Trieve. You'll see configurations for adjusting filters, choosing between search types (ex. hybrid, semantic, fulltext (SPLADE), BM25, etc.), sorting and reranking. You can also do multi-query searches and group search (returning the corresponding group for the retrieved chunks). There are additional options to set the score threshold for retrieved results, page size, stop word removal, and various settings for managing Trieve's sub-sentence highlighting. Once a search has been conducted you will also see a button to "Rate This Search" which opens a modal with a 0-10 slider and notes field.
Example searches to showcase the search types:
Query: visualizations (Semantic)
This is a dense vector search using cosine distance vectors on Jina english embeddings),

Query: visualizations (Fulltext)
Notice how the retrieval model for our fulltext search type, SPLADE, is returning chunks containing words closer to the query rather than the broader semantics.

Query: visualizations (Hybrid)
This takes in results from both fulltext and semantic and re-ranks with a cross-encoder model (here the BAAI/bge-reranker-large).
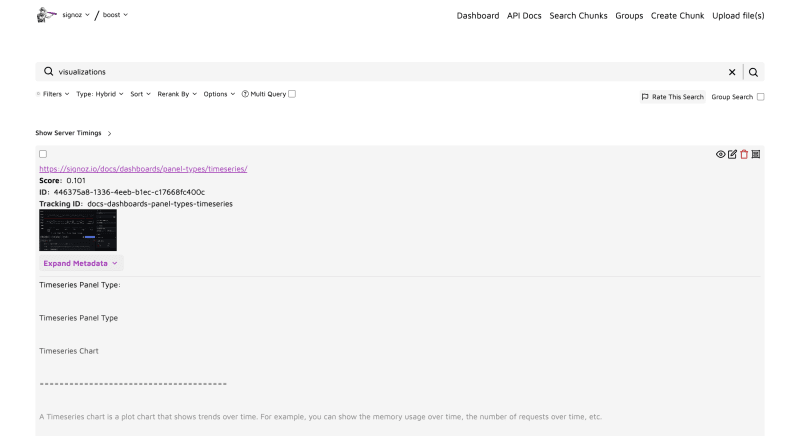
Group Search:
Internally this uses the chunk_group/group_oriented_search route.
Query: OpenTelemetry FastAPI example (Hybrid)

RAG Playground: chat.trieve.ai
This is a question-and-answer chat interface to showcase and explore RAG in your dataset with Trieve. It has everything you are looking for: input at bottom, streaming response from the LLM, and documents (the retrieved chunks) used by the LLM in its response on the right-hand side. You can regenerate a response, ask follow-on questions, start new conversations, and open any of the retrieved chunks. The various RAG-relevant parameters can be adjusted in the dataset settings in the dashboard: LLM, HyDE prompt (optional), System Prompt, RAG prompt, and more. We support models available on OpenRouter: openrouter.ai/docs/models
What is HyDE?
Hypothetical Document Embeddings (HyDE) is a retrieval method where an LLM first generates a hypothetical document that might address a user's query, and then that document is used in a semantic search (instead of the original query) to retrieve documents from the dataset. Read more in Luyu Gao et al.'s "Precise Zero-Shot Dense Retrieval without Relevance Labels".
Example interactions on the RAG interface:
Question: What is SigNoz?

Question: What are the benefits of OpenTelemetry?

Conclusion
Firecrawl and Trieve are a powerful combination for quickly building search and RAG systems. Get started today!
- Firecrawl: firecrawl.dev
- Trieve: trieve.ai
- Github repo: firecrawl-to-trieve
This content originally appeared on DEV Community and was authored by Daniel Griffin
Daniel Griffin | Sciencx (2024-08-22T19:12:03+00:00) Build Search and RAG for Any Website with Firecrawl and Trieve. Retrieved from https://www.scien.cx/2024/08/22/build-search-and-rag-for-any-website-with-firecrawl-and-trieve/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.