
This content originally appeared on HackerNoon and was authored by William Guo
\ Hey guys, I’m Cai Shunfeng, a senior data engineer at WhaleOps, and a committer and PMC member of the Apache DolphinScheduler community. Today, I will explain how the Worker task of Apache DolphinScheduler works.
This explanation will be divided into three sections:
\
- Introduction to Apache DolphinScheduler
- Overview of Apache DolphinScheduler’s overall design
- Detailed execution process of Worker tasks
Project Introduction
Apache DolphinScheduler is a distributed, easily extensible, visual workflow scheduling open-source system, suitable for enterprise-level scenarios.
\
\ It provides the following key functionalities, offering a full lifecycle data processing solution for workflows and tasks through visual operations.
Key Features
Easy to use
Visual DAG Operations: Users can drag and drop components on the page to arrange them into a DAG (Directed Acyclic Graph).
Plugin System: Includes task plugins, data source plugins, alert plugins, storage plugins, registry center plugins, and cron job plugins, etc. Users can easily extend plugins as needed to meet their business requirements.
\
Rich Usage Scenarios
Static Configuration: Includes workflow scheduling, online and offline operations, version management, and backfill functions.
Runtime Operations: Provides functionalities like pause, stop, resume, and parameter substitution.
Dependency Types: Supports a rich set of dependency options and strategies, adapting to more scenarios.
Parameter Passing: Supports startup parameters at the workflow level, global parameters, local parameters at the task level, and dynamic parameter passing.
\
High Reliability
Decentralized Design: All services are stateless and can be horizontally scaled to increase system throughput.
Overload Protection and Instance Fault Tolerance:
Overload Protection: During operation, the master and worker monitor their own CPU and memory usage, as well as the task volume. If overloaded, they pause the current workflow/task processing and resume after recovery.
Instance Fault Tolerance: When master/worker nodes fail, the registry center detects the service node offline and performs fault tolerance for workflow or task instances, ensuring the system’s self-recovery capability as much as possible.
Overall Design
Project Architecture
Next, let’s introduce the overall design background. Below is the design architecture diagram provided on the official website.
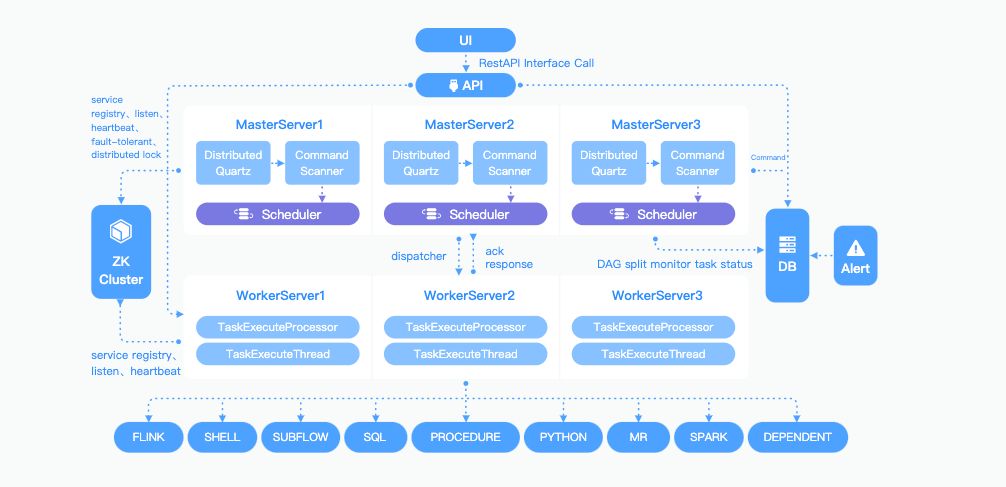
\ From the architecture diagram, we can see that Apache DolphinScheduler is composed of several main components:
API Component: The API service primarily manages metadata, interacts with the UI via the API service, or calls API interfaces to create workflow tasks and various resources needed by the workflow.
\
Master Component: The master is the controller of workflow instances, responsible for consuming commands, converting them into workflow instances, performing DAG splitting, submitting tasks in order, and distributing tasks to workers.
\
Worker Component: The worker is the executor of specific tasks. After receiving tasks, it processes them according to different task types, interacts with the master, and reports task status. Notably, the worker service does not interact with the database; only the API, master, and alert services interact with the database.
\
Alert Service: The alert service sends alerts through different alert plugins. These services register with the registry center, and the master and worker periodically report heartbeats and current status to ensure they can receive tasks normally.
Master and Worker Interaction Process
The interaction process between the master and worker is as follows:
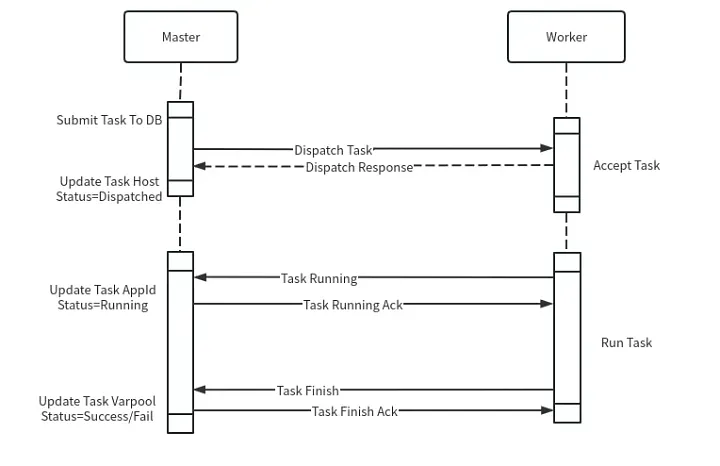
Task Submission: After the master completes DAG splitting, it submits tasks to the database and selects an appropriate worker group to distribute tasks based on different distribution strategies.
\
Task Reception: After the worker receives a task, it determines whether to accept the task based on its condition. Feedback is provided whether the acceptance is successful or not.
\
Task Execution: The worker processes the task, updates the status to running, and feeds back to the master. The master updates the task status and start time information in the database.
\
Task Completion: After the task is completed, the worker sends a finish event notification to the master, and the master returns an ACK confirmation. If no ACK is received, the worker will keep retrying to ensure the task event is not lost.
Worker Task Reception
When the worker receives a task, the following operations are performed:
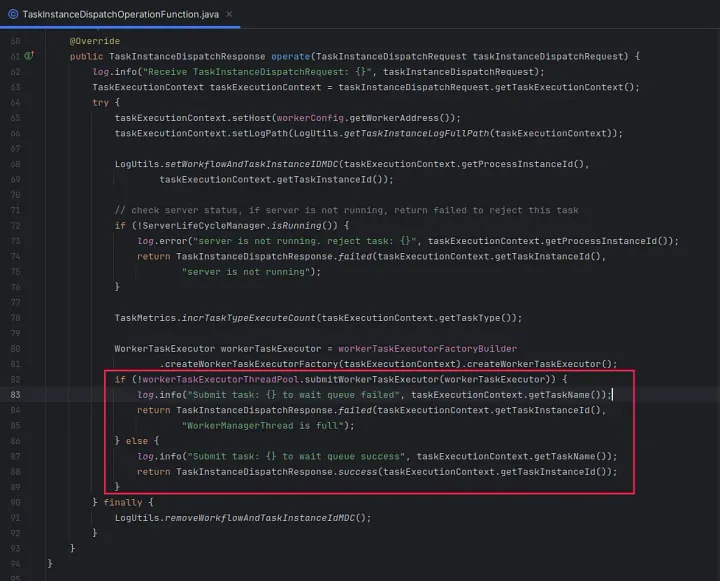
- Fills in its host information.
- Generates the log path on the worker machine.
- Generates a Worker Task Executor, which is submitted to the thread pool for execution.
\ The worker checks whether it is overloaded; if so, it rejects the task. After receiving the task distribution failure feedback, the master continues to choose another worker for task distribution based on the distribution strategy.
Worker Execution Process
The specific execution process of worker tasks includes the following steps:
- Task Initialization: Initializes the environment and dependencies required for the task.
- Task Execution: Executes the specific task logic.
- Task Completion: After the task execution is completed, reports the task execution results to the master node.
\ Next, we will detail the specific task execution process.
\ Before the task execution begins, a context is first initialized. At this point, the start time of the task is set. To ensure the accuracy of the task, it is necessary to synchronize time between the master and worker to avoid time drift.
\ Subsequently, the task status is set to running and fed back to the master to notify that the task has started running.
\ Since most tasks run on the Linux operating system, tenant and file processing are required:
- Tenant Processing: First, it checks whether the tenant exists. If not, it decides whether to automatically create the tenant based on the configuration. This requires the deployment user to have sudo permissions to switch to the specified tenant during task execution.
- Specific Users: For some scenarios, it is not necessary to switch tenants, but simply execute the task using a specific user. This is also supported by the system.
- \
After processing the tenant, the worker creates the specific execution directory. The root directory of the execution directory is configurable and requires appropriate authorization. By default, the directory permissions are set to 755.
\ During task execution, various resource files may be needed, such as fetching files from AWS S3 or HDFS clusters. The system downloads these files to the worker’s temporary directory for subsequent task use.
\ In Apache DolphinScheduler, parameter variables can be replaced. The main categories include:
- Built-in Parameters: Primarily involves the replacement of time and date-related parameters.
- User-defined Parameters: Parameter variables set by the user in the workflow or task will also be replaced accordingly.
Through the above steps, the task’s execution environment and required resources are ready, and the task can officially start execution.
Different Types of Tasks
In Apache DolphinScheduler, various types of tasks are supported, each applicable to different scenarios and requirements. Below, we introduce several major task types and their specific components.
\
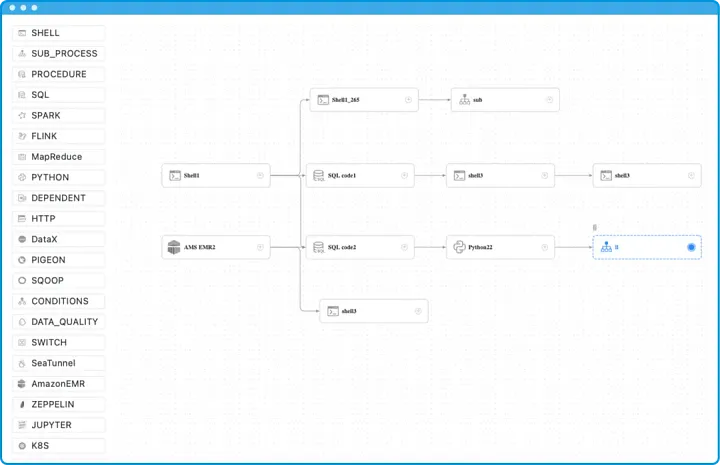
These components are commonly used to execute script files, suitable for various scripting languages and protocols:
- Shell: Executes shell scripts.
- Python: Executes Python scripts.
- SQL: Executes SQL statements.
- Stored Procedure: Executes database stored procedures.
- HTTP: Performs HTTP requests.
The commercial version(WhaleScheduler) also supports running Java applications by executing JAR packages.
Logic Task Components
These components are used to implement logical control and workflow management:
- Switch: Conditional control task.
- Dependent: Dependency task.
- SubProcess: Sub-task.
- NextLoop (Commercial Version): Loop control task suitable for financial scenarios.
- Trigger Component: Monitors whether files or data exist.
Big Data Components
These components are mainly used for big data processing and analysis:
- SeaTunnel: Corresponds to the commercial version of WhaleTunnel, used for big data integration and processing.
- AWS EMR: Amazon EMR integration.
- HiveCli: Hive command-line task.
- Spark: Spark task.
- Flink: Flink task.
- DataX: Data synchronization task.
Container Components
These components are used to run tasks in a container environment:
- K8S: Kubernetes task.
Data Quality Components
Used to ensure data quality:
- DataQuality: Data quality check task.
Interactive Components
These components are used to interact with data science and machine learning environments:
- Jupyter: Jupyter Notebook task.
- Zeppelin: Zeppelin Notebook task.
Machine Learning Components
These components are used for the management and execution of machine learning tasks:
- Kubeflow: Kubeflow task.
- MlFlow: MlFlow task.
- Dvc: Data Version Control task.
Overall, Apache DolphinScheduler supports three to four dozen components, covering areas from script execution, big data processing, to machine learning. For more information, please visit the official website to view detailed documentation.
Task Type Abstraction
In Apache DolphinScheduler, task types are abstracted into multiple processing modes to suit various runtime environments and needs.
Below we introduce the abstraction and execution process of task types in detail.
\
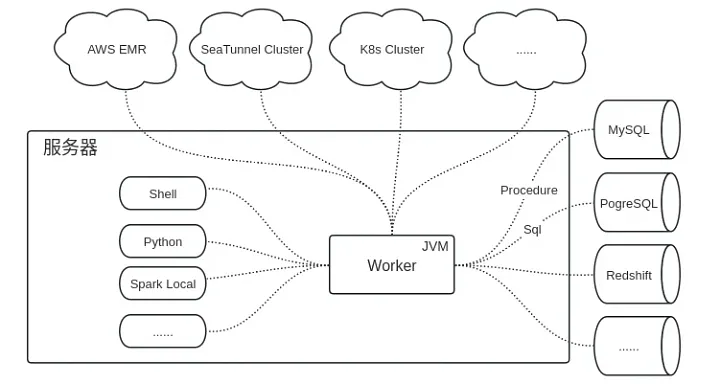
The worker is a JVM service deployed on a server. For some script components (such as Shell, and Python) and locally run tasks (such as Spark Local), they will start a separate process to run.
\ At this point, the worker interacts with these tasks through the process ID (PID).
\ Different data sources may require different adaptations. For SQL and stored procedure tasks, we have abstracted handling for different data sources, such as MySQL, PostgreSQL, AWS Redshift, etc. This abstraction allows for flexible adaptation and expansion of different database types.
\ Remote tasks refer to tasks that are executed on remote clusters, such as AWS EMR, SeaTunnel clusters, Kubernetes clusters, etc. The Worker does not execute these tasks locally; instead, it submits them to the remote clusters and monitors their status and messages. This mode is particularly suited for cloud environments where scalability is required.
Task Execution
Log Collection
Different plugins use different processing modes, and therefore, log collection varies accordingly:
Local Processes: Logs are recorded by monitoring the process output.
Remote Tasks: Logs are collected by periodically checking the task status and output from the remote cluster (e.g., AWS EMR) and recording them in the local task logs.
\
Parameter Variable Substitution
The system scans the task logs to identify any parameter variables that need to be dynamically replaced. For example, Task A in the DAG may generate some output parameters that need to be passed to downstream Task B.
During this process, the system reads the logs and substitutes the parameter variables as required.
\ Retrieving Task ID
- Local Processes: The process ID (PID) is retrieved.
- Remote Tasks: The ID of the remote task (e.g., AWS EMR Task ID) is retrieved.
Holding these task IDs allows for further data queries and remote task operations. For instance, when a workflow is stopped, the corresponding cancel API can be called using the task ID to terminate the running task.
\ Fault Tolerance Handling
- Local Processes: If a Worker node fails, the local process will not be aware of it, requiring the task to be resubmitted.
- Remote Tasks: If the task is running on a remote cluster (e.g., AWS), the task’s status can be checked using the task ID, and an attempt can be made to take over the task. If successful, there is no need to resubmit the task, saving time.
Task Execution completion
After a task has been executed, several completion actions are required:
Task Completion Check: The system will check if an alert needs to be sent. For example, for an SQL task, if the query results trigger an alert, the system will interact with the alert service via RPC to send the alert message.
Event Feedback: The Worker will send the task completion event (finish event) back to the Master. The Master updates the task status in the database and proceeds with the DAG status transition.
Context Cleanup: The Worker will remove the task context that was created at the start of the task from memory. It will also clean up the file paths generated during task execution. If in debug mode (development mode), these files will not be cleaned, allowing for troubleshooting of failed tasks.
\
Through these steps, the entire execution process of a task instance is completed.
Community Contribution
If you are interested in Apache DolphinScheduler and want to contribute to the open-source community, you are welcome to refer to our contribution guidelines.
\ The community encourages active contributions, including but not limited to:
- Reporting issues encountered during usage.
- Submitting documentation and code PRs.
- Adding unit tests (UT).
- Adding code comments.
- Fixing bugs or adding new features.
- Writing technical articles or participating in Meetups.
Guide for New Contributors
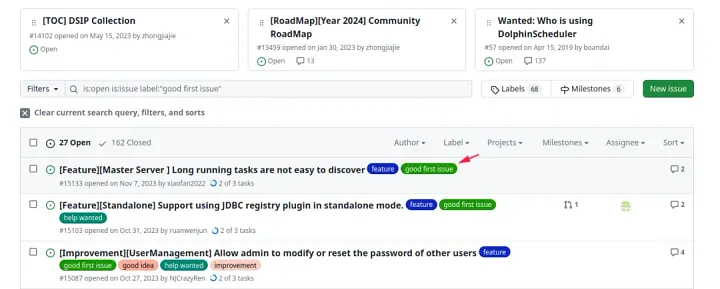
For new contributors, you can search for issues labeled as good first issue in the community's GitHub issues. These issues are generally simpler and suitable for users making their first contribution.
\ In summary, we have learned about the overall design of Apache DolphinScheduler and the detailed execution process of Worker tasks.
I hope this content helps you better understand and use Apache DolphinScheduler. If you have any questions, feel free to reach out to me in the comment section.
\
This content originally appeared on HackerNoon and was authored by William Guo
William Guo | Sciencx (2024-08-23T22:00:17+00:00) Breaking Down the Worker Task Execution in Apache DolphinScheduler. Retrieved from https://www.scien.cx/2024/08/23/breaking-down-the-worker-task-execution-in-apache-dolphinscheduler/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.