
This content originally appeared on HackerNoon and was authored by Writings, Papers and Blogs on Text Models
:::info Authors:
(1) Rafael Rafailo, Stanford University and Equal contribution; more junior authors listed earlier;
(2) Archit Sharma, Stanford University and Equal contribution; more junior authors listed earlier;
(3) Eric Mitchel, Stanford University and Equal contribution; more junior authors listed earlier;
(4) Stefano Ermon, CZ Biohub;
(5) Christopher D. Manning, Stanford University;
(6) Chelsea Finn, Stanford University.
:::
Table of Links
4 Direct Preference Optimization
7 Discussion, Acknowledgements, and References
\ A Mathematical Derivations
A.1 Deriving the Optimum of the KL-Constrained Reward Maximization Objective
A.2 Deriving the DPO Objective Under the Bradley-Terry Model
A.3 Deriving the DPO Objective Under the Plackett-Luce Model
A.4 Deriving the Gradient of the DPO Objective and A.5 Proof of Lemma 1 and 2
\ B DPO Implementation Details and Hyperparameters
\ C Further Details on the Experimental Set-Up and C.1 IMDb Sentiment Experiment and Baseline Details
C.2 GPT-4 prompts for computing summarization and dialogue win rates
\ D Additional Empirical Results
D.1 Performance of Best of N baseline for Various N and D.2 Sample Responses and GPT-4 Judgments
Additional Empirical Results
D.1 Performance of Best of N baseline for Various N
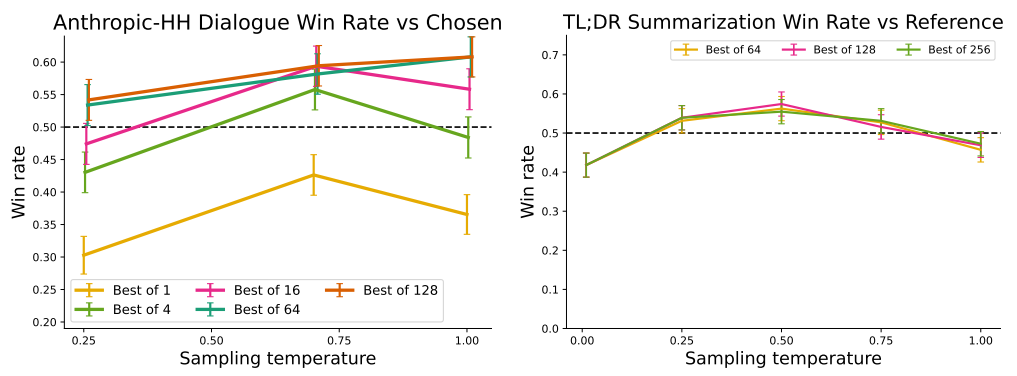
We find that the Best of N baseline is a strong (although computationally expensive, requiring sampling many times) baseline in our experiments. We include an evaluation of the Best of N baseline for various N for the Anthropic-HH dialogue and TL;DR summarization; the results are shown in Figure 4.
D.2 Sample Responses and GPT-4 Judgments
In this section, we present examples of comparisons between DPO and the baseline (PPO temp 0. for summarization, and the ground truth chosen response for dialogue). See Tables 4-6 for summarization examples, and Tables 7-10 for dialogue examples.
\
\
![Table 4: Sample summaries to a post from the TL;DR test set. DPO sample generated with a temperature 0.25; PPO sample generated at a temperature of 0. The order in which summaries are presented in randomized when evaluating with GPT-4, so the order in the Judgment may not correspond to the order in the table. For clarity, post-hoc annotations are included in bold, formatted as [annotation]. These annotations are not part of the model generations.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-qe93z94.png)
\
![Table 5: Sample summaries to a post from the TL;DR test set. DPO sample generated with a temperature 0.25; PPO sample generated at a temperature of 0. The order in which summaries are presented in randomized when evaluating with GPT-4, so the order in the Judgment may not correspond to the order in the table. For clarity, post-hoc annotations are included in bold, formatted as [annotation]. These annotations are not part of the model generations.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-fga3zy2.png)
\
![Table 6: Sample summaries to a post from the TL;DR test set. DPO sample generated with a temperature 0.25; PPO sample generated at a temperature of 0. The order in which summaries are presented in randomized when evaluating with GPT-4, so the order in the Judgment may not correspond to the order in the table. For clarity, post-hoc annotations are included in bold, formatted as [annotation]. These annotations are not part of the model generations.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-yib3zos.png)
\
![Table 7: GPT-4 chooses DPO over GT. Sample responses to a prompt from the Anthropic-HH test set. DPO sample generated with temperature 0.7; GT is the chosen completion in the dataset of preferences. For clarity, post-hoc annotations are included in bold, formatted as [annotation]. These annotations are not part of the model generations.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-g4c3zzz.png)
\
![Table 8: GPT-4 chooses DPO over GT. Sample responses to a prompt from the Anthropic-HH test set. DPO sample generated with temperature 1.0; GT is the chosen completion in the dataset of preferences. For clarity, post-hoc annotations are included in bold, formatted as [annotation]. These annotations are not part of the model generations.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-hdd3zjq.png)
\

\

\
:::info This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.
:::
\
This content originally appeared on HackerNoon and was authored by Writings, Papers and Blogs on Text Models
Writings, Papers and Blogs on Text Models | Sciencx (2024-08-26T21:30:12+00:00) Performance of Best of N Baseline for Various N and Sample Responses and GPT-4 Judgments. Retrieved from https://www.scien.cx/2024/08/26/performance-of-best-of-n-baseline-for-various-n-and-sample-responses-and-gpt-4-judgments/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.