
This content originally appeared on HackerNoon and was authored by Manish Sinha
In this age, we generate an enormous amount of data, which can be mind-boggling. According to IDC, humanity is projected to grow from “33 zettabytes in 2018 to 175 zettabytes by 2025.” The existence of the amount of data is both an opportunity and a big challenge for businesses. If we analyze this data, it can lead to valuable insights and competitive advantages across industries.
\ As we increasingly rely on big data, it introduced new security risks with rapidly evolving cybersecurity threats, including but not limited to independent hackers and state actors. Recent high-profile data breaches, such as the Kaseya ransomware attack in 2021 and the Optus data breach in 2022, show us the gaping hole in the claimed secure software systems. We can see that the consequences of data breaches are not just limited to financial losses but reputational damage, as well as compromised national security. All of us have a job to ensure that we maintain the security and integrity of data.
Problem
When we handle petabytes of data, our customers still expect real-time insights and aggregations on their dashboards. To achieve this, the data analysis has to be performed efficiently. No one wants to wait multiple seconds on a page for the statistics to show up, and no one wants to wait long periods of time on a page to get personalized recommendations. When we streamline the customer experience and make it efficient, it improves satisfaction and retention.
\ A study by Accenture found that “83% of consumers are willing to share their data to enable a personalized experience”. A lot of us are used to our personal data being used against our well, but we are still not comfortable with our personal data being mishandled.
\ Cost- and time-effective data analysis is critical for big companies; it can improve user experience and provide real-time insights. Balancing efficiency with security is important when handling sensitive data to avoid serious disaster situations. According to IBM, the average data breach cost in 2021 was $4.24 million, which showcases the financial consequences of not taking security seriously.
Expectations
In my mind, the ideal data analysis using dask and AWS architecture must meet several criteria. It should provide:
\
- robust encryption for data at rest and in transit
- and incorporate strong access controls and authentication mechanisms
- to offer scalability without compromising performance or security.
\ For better observability, it should provide comprehensive logging and auditing capabilities to ensure compliance with regulations. We will use Python libraries like Dask for distributed computing and AWS best practices for cloud security; this architecture will lead to a solution that makes data analysis secure and fast.
Speed up with Dask
Dask is a Python library for parallel and distributed computing. It is pretty useful when we have to run huge amounts of data across multiple cores. It uses pandas and numpy under the hood. It can run parallel on your machine using all the cores; the computation can be spread across multiple machines using Dask Clusters. It supports running the computation on AWS Fargate clusters.
\ While we are focusing on customer data, which can contain personally identifying data, for the purpose of this exercise, we will randomly generate a dataset to showcase Dask's capabilities.
\ We will compare the performance of dask with that of pandas. As we can see in the code below, we have multiple chunks of data, which will be simulated as having part files or files split up into smaller files and stored in a single S3 bucket. We can also consider partitioned data, as keeping everything in one single file can be quite inefficient when the row count crosses certain limits.
\
import dask.dataframe as dd
import pandas as pd
import numpy as np
import time
import os
from dask.distributed import Client, LocalCluster
CHUNKS = 100
ROWS_PER_CHUNK = 1_000_000
N_CATEGORIES = 1000
def generate_large_csv(filename, chunks=CHUNKS, rows_per_chunk=ROWS_PER_CHUNK):
print(f"Generating large CSV file: {filename}")
for i in range(chunks):
df = pd.DataFrame({
'id': range(i*rows_per_chunk, (i+1)*rows_per_chunk),
'value1': np.random.randn(rows_per_chunk),
'value2': np.random.randn(rows_per_chunk),
'value3': np.random.randn(rows_per_chunk),
'category': np.random.randint(0, N_CATEGORIES, rows_per_chunk)
})
if i == 0:
df.to_csv(filename, index=False)
else:
df.to_csv(filename, mode='a', header=False, index=False)
print(f"Chunk {i+1}/{chunks} written")
def complex_operation(df):
result = (
df.groupby('category')
.agg({
'value1': ['mean', 'std', 'min', 'max'],
'value2': ['mean', 'std', 'min', 'max'],
'value3': ['mean', 'std', 'min', 'max']
})
)
result['combined'] = (
result[('value1', 'mean')] * result[('value2', 'std')] +
result[('value3', 'max')] - result[('value1', 'min')]
)
return result
def run_dask_analysis(filename):
with LocalCluster(n_workers=8, threads_per_worker=2) as cluster, Client(cluster) as client:
print("Running Dask analysis...")
start_time = time.time()
df = dd.read_csv(filename)
result = complex_operation(df).compute()
end_time = time.time()
execution_time = end_time - start_time
return execution_time, result
def run_pandas_analysis(filename):
print("Running Pandas analysis...")
start_time = time.time()
df = pd.read_csv(filename)
result = complex_operation(df)
end_time = time.time()
execution_time = end_time - start_time
return execution_time, result
def main():
filename = "very_large_dataset.csv"
total_rows = CHUNKS * ROWS_PER_CHUNK
if not os.path.exists(filename):
generate_large_csv(filename)
print(f"\nProcessing dataset with {total_rows:,} rows and {N_CATEGORIES:,} categories...")
dask_time, dask_result = run_dask_analysis(filename)
try:
pandas_time, pandas_result = run_pandas_analysis(filename)
except MemoryError:
print("Pandas ran out of memory. This demonstrates a key advantage of Dask for large datasets.")
pandas_time = float('inf')
pandas_result = None
print("Results (first few rows):")
print("Dask Result:")
print(dask_result.head())
if pandas_result is not None:
print("Pandas Result:")
print(pandas_result.head())
print("Execution times:")
print(f"Dask: {dask_time:.2f} seconds")
if pandas_time != float('inf'):
print(f"Pandas: {pandas_time:.2f} seconds")
speedup = pandas_time / dask_time
print(f"Dask speedup: {speedup:.2f}x")
else:
print("Pandas: Out of Memory")
if __name__ == '__main__':
main()
\ When we run the code multiple times we usually get output something like this
Processing dataset with 100,000,000 rows and 1,000 categories...
Running Dask analysis...
2024-08-16 15:32:06,161 - distributed.shuffle._scheduler_plugin - WARNING - Shuffle 7b7666c9c8ced5f2521eb8c13b1cb16b initialized by task ('shuffle-transfer-7b7666c9c8ced5f2521eb8c13b1cb16b', 97) executed on worker tcp://127.0.0.1:63688
2024-08-16 15:32:13,888 - distributed.shuffle._scheduler_plugin - WARNING - Shuffle 7b7666c9c8ced5f2521eb8c13b1cb16b deactivated due to stimulus 'task-finished-1723847533.887299'
Running Pandas analysis...
Results (first few rows):
Dask Result:
value1 value2 value3 combined
mean std min max mean std min max mean std min max
category
397 -0.002135 0.999627 -4.344266 4.289468 -0.003172 1.000118 -4.558085 4.439482 0.000241 0.995912 -4.486216 4.585379 8.927510
988 -0.001370 1.000915 -4.059722 4.069215 -0.001550 1.000301 -4.300040 4.091358 -0.000087 0.998721 -4.438947 4.445720 8.504071
945 0.000691 1.000980 -5.674771 4.668603 -0.000936 1.000296 -4.442228 4.295256 -0.000951 1.001830 -4.191695 4.634225 10.309686
99 0.001063 1.005469 -4.749642 4.059719 0.000543 1.000926 -4.279197 4.282448 -0.000162 1.003164 -4.132993 4.541916 9.292623
396 0.001174 1.000782 -4.318082 4.371785 0.003896 0.997300 -4.683839 4.239039 0.003142 0.997511 -4.125262 4.525860 8.845112
Pandas Result:
value1 value2 value3 combined
mean std min max mean std min max mean std min max
category
0 -0.001918 0.999454 -4.696701 4.212904 -0.002754 1.001868 -4.507300 3.984878 0.004145 0.998178 -4.014290 4.091141 8.785920
1 0.000446 1.001031 -4.460898 4.427304 0.001287 1.002637 -4.711565 4.152570 0.000393 1.003005 -4.855133 4.510505 8.971851
2 -0.004153 0.999196 -4.059107 4.154900 0.001008 1.000062 -4.185225 4.473653 -0.002570 0.999586 -4.155561 4.788469 8.843423
3 -0.005269 1.003784 -4.131928 4.735281 0.004382 0.999795 -3.979235 4.504564 0.003346 0.997064 -3.965638 4.438514 8.565174
4 -0.005069 0.999669 -4.493981 4.474479 -0.002145 0.994543 -4.174338 4.169072 -0.005240 1.000150 -3.998451 4.194488 8.683427
Execution times:
Dask: 9.79 seconds
Pandas: 30.99 seconds
Dask speedup: 3.17x
For this dataset size, the speedup is usually between 3.1X and 3.35X times. Given that companies like AirBnB, Amazon, etc., have millions and billions of records, it is quite possible to get speedup gains over 10.
\ We used min, max, and other standard aggregation metrics, for which pandas are extremely efficient. In situations where we are executing some complex aggregations, which itself takes time, running those aggregations in parallel will save us significant time.
Run it securely on AWS
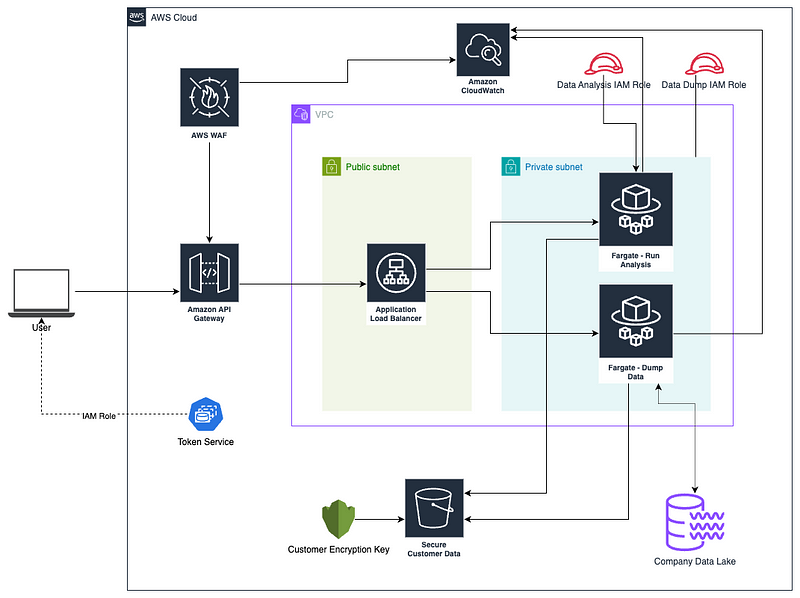
Let’s build a method to securely manage all the data and computation in AWS. We would be using some fundamental concepts:
\
- API Gateway — to programmatically access the service. We would preferably be using RESTful design
- IAM Roles and SSO—We want single sign-on so that your users don’t have to manage a separate set of credentials. We would use an IAM Role so that we can use AWS STS to get credential rotations built in.
- AWS WAF on API Gateway — add some basic rate limiting and add some rules to prevent basic injection attacks, which helps prevent the entry point from being abused by malicious actors
- Customer Encryption Key: Instead of relying on the AWS default encryption key, take control of the encryption key and rotate it much more frequently, say 90 days, compared to 365 days for the default.
- Scoped IAM Role for both Fargate tasks — We have two Fargate tasks. One is for taking the data from your company’s data lake and dropping it in S3, partitioning it efficiently.
- VPC and Private Subnets—The computation using Dask happens inside Fargate instances. Since this instance deals with highly critical data, it is important that this component be secured inside a Private Subnet within a Virtual Private Cloud.
- Access to Private Subnet through Application Load Balancer—The API Gateway handles authentication, authorization, and quota management, but we need an Application Load Balancer inside the Public Subnet to route our requests to the respective Fargate instances.
- CloudWatch Logs — We are concerned with data breaches, so we will log the access to API Gateway and the computations that happen inside Fargate instances. Using the logs on CloudWatch, we can run anomaly analysis to identify unusual patterns or use business needs-specific access analysis to get a deeper insight.
\ If I go ahead and put all the components in the design diagram, it would be overwhelming and make the diagram illegible. I will try to keep it as simple as possible.
\
Conclusion
In this day and age, one should not have to choose between security and performance or focus on just one at a time. It’s important to consider both at the same time. Performance is also known as high availability, and we need scalable architecture to achieve our goals.
\ With scalable architecture, which contains microservices, there is a higher number of moving parts, which can introduce weaknesses in the system. Keeping an eye on and having a thoughtful analysis exercise is very helpful in ironing out most of the common security pitfalls.
This content originally appeared on HackerNoon and was authored by Manish Sinha
Manish Sinha | Sciencx (2024-08-27T09:07:04+00:00) Highly Efficient and Secure Data Analysis Using Dask and AWS Best Practices. Retrieved from https://www.scien.cx/2024/08/27/highly-efficient-and-secure-data-analysis-using-dask-and-aws-best-practices/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.