
This content originally appeared on HackerNoon and was authored by Computational Technology for All
:::info Authors:
(1) Suzanna Sia, Johns Hopkins University;
(2) David Mueller;
(3) Kevin Duh.
:::
Table of Links
- Abstract and 1. Background
- 2. Data and Settings
- 3. Where does In-context MT happen?
- 4. Characterising Redundancy in Layers
- 5. Inference Efficiency
- 6. Further Analysis
- 7. Conclusion, Acknowledgments, and References
- A. Appendix
2. Data and Settings
Models We use GPTNEO2.7B (Black et al., 2021), BLOOM3B (Scao et al., 2022), LLAMA7B and LLAMA7Bchat (Touvron et al., 2023), the instruction-tuned variant, in all of our experiments. GPTNEO2.7B has 32 layers and 20 heads, BLOOM3B has 30 layers and 32 heads, while LLAMA7B has 32 layers and 32 heads. The checkpoints we use are from the transformers library (Wolf et al., 2019).
\ GPTNEO was trained on The PILE (Gao et al., 2020), an 825GB text dataset which consists of roughly 98% English data. Despite being mostly monolingual, The PILE contains Europarl which GPTNEO was trained on at a document level (rather than a sentence level). Conversely, BLOOM was trained on the ROOTS corpus (Laurençon et al., 2022), a composite collection of 498 datasets that were explicitly selected to be multilingual, representing 46 natural languages and 13 programming languages. LLAMA training data consists primarily of common crawl, C4, wikipedia, stack exchange as major sources. To our knowledge, there has not been any reports of sentence level parallel corpora in the training datasets of these models.
\ Data We test our models using FLORES (Goyal et al., 2021) en ↔ fr which we report in the main paper, and a small study on extending Section 3 to en ↔ pt in the Appendix. Prompt examples are drawn from the development set. We evaluate the generations using BLEU scores, following the implementation from Post (2018).
\ Prompt Format Our prompts may consist of instructions, examples, both, or none. Importantly, we adopt neutral delimiters, "Q:" and "A:" to separate the prompt and the start of machine generated text. This ensures that the models do not have any information from the delimiters on what the task is. [1]
\
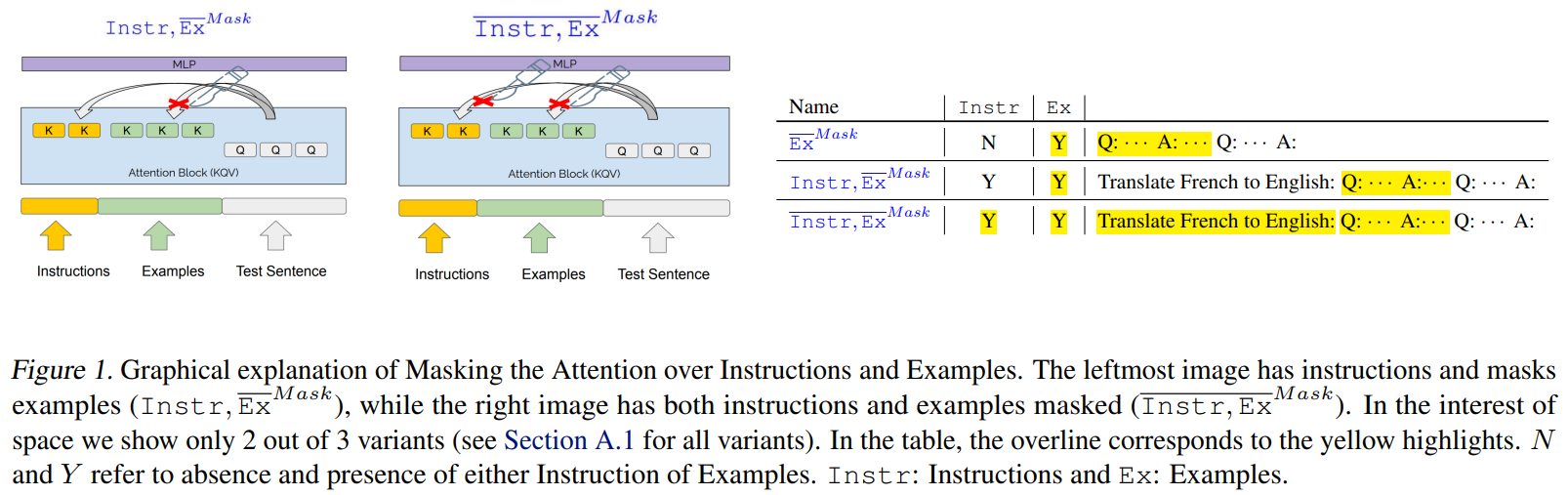
\ When no natural language instructions are used the model input will be Q: {sourcesentence} A: Instructions are given in natural language and take the form: Translate from {L1} to {L2}: Q: {sourcesentence} A:, where L1 = English and L2 = French if the source and target languages are English and French respectively. Examples are given after instructions, and similarly delimited by Q: and A:. See Appendix: Table 1 for an example.
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
[1] In an earlier exploration, we found that supplying the model with language indicators only, e.g., "English:", "French:" was sufficient for strong models (llama7b, llama7b-chat) to perform the task without seeing any instructions or examples in the context.
This content originally appeared on HackerNoon and was authored by Computational Technology for All
Computational Technology for All | Sciencx (2024-08-30T17:00:19+00:00) Where does In-context Translation Happen in Large Language Models: Data and Settings. Retrieved from https://www.scien.cx/2024/08/30/where-does-in-context-translation-happen-in-large-language-models-data-and-settings/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.