
This content originally appeared on Level Up Coding - Medium and was authored by David Bethune

AI is everywhere you want to be, like those old Visa commercials, but different approaches to the tools create different levels of results. Today I’ll show you a “middle path” between simple prompts and building a complete AI system with your own code. It’s called Custom GPTs and you can make them with a ChatGPT/OpenAI account. The method we’ll use is called structured prompting, using careful English sentences, formatting, and examples.

Word Salad
One thing we need to get out of the way, right away, is the slew of words that we use to talk about AI. In an ideal world, “AI” itself would not be among them because it’s misleading and unhelpful.
In the old days of AI, we tried to actually get to artificial intelligence. I won’t bore you with the various ways but suffice it to say they didn’t work. Then, some smart folks stumbled onto the idea of using statistics to predict the correct answers even if no intelligence were involved. You can think of this like reading a million books and making new sentences out of the most likely answers found in their text. (See my Behind the Curtain article for deets.)
The term for this new method is LLM or Large Language Model. We really should call all of these underlying products by that name. So GPT 4o from OpenAI is an LLM. So is Claude from Anthropic.
The model by itself, reduced to just lists of numbers representing words in the original documents, doesn’t do much. So it gets wrapped in some software that handles input and output. The input might be written text or voice while the output might be narrative text, data files like JSON, or pictures.
This wrapping tool is called a GPT or Generative Pre-trained Transformer. Thus we get ChatGPT from OpenAI for chatting with that company’s backing LLM, and DALL-E from the same company for working with images through prompts. When the same tool can handle many kinds of inputs and outputs it’s said to be multimodal. GPT 4o is multimodal and can work with text, images, files, and code, including code that it writes itself and then runs to perform specific actions you describe.

It’s Prompts All The Way Down
So who controls what each GPT does and says? Does it use its encyclopedic knowledge (lists of numbers) to write poetry, to teach science, or to make up political lies? And how do they create such instructions?
Would it surprise you to learn that GPTs are, themselves, programmed by prompts? The controlling prompt that decides what you can and cannot do with ChatGPT is called the system prompt. The system prompt is the lowest level prompt as it controls all interactions with the backing LLM. In this case, it’s setup to deal with poetry, science, and even politics with some system-level protections there to prevent undesirable output, like racism and terrorist plotting.
You probably already knew that something like the system prompt existed. And it’s clear if you’ve tried ChatGPT that what you write in the session is also part of the “rules.” In other words, if you say you are planning your daughter’s quinceañera, you won’t get Fourth of July suggestions in the output. In fact, everything that the user writes in the session is considered the highest level prompt, and this makes sense because otherwise the GPT would literally have no idea what to talk about.
Man In The Middle
What many people don’t know is that there’s another layer in the middle called the master prompt which you can also write, and this is where the fun begins. At first, you had to use cumbersome tools inside your OpenAI account to get to these various functions, including uploading and accessing files, examining links, performing web searches, running custom code, creating consistent images, and outputting formatted data.
Today, you can make custom GPTs with ChatGPT itself, and we’ll use several of these features in our example app. Once you create one, the master prompt sticks around for each session you start with that GPT. Those new sessions will have your rules and abilities and you can share them with others or not, as you choose. When you share a custom GPT, it runs in the user’s account, not yours.

Building The Example
Yesterday, I built a cover letter assistant for job hunting. You can try it yourself with a ChatGPT account. You’ll need one to make your own GPTs.
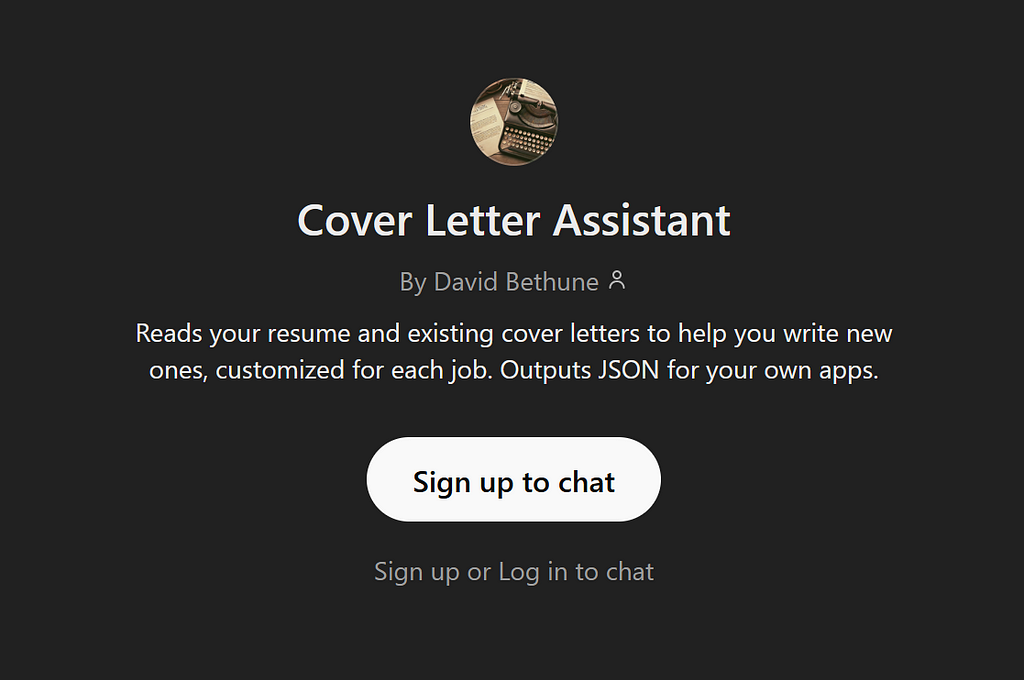
Here’s where to find the controls: Once you’re logged-in to ChatGPT, click your initials at the top right, then choose My GPTs. You can also go back to this page later to use or edit the GPTs you’ve created.
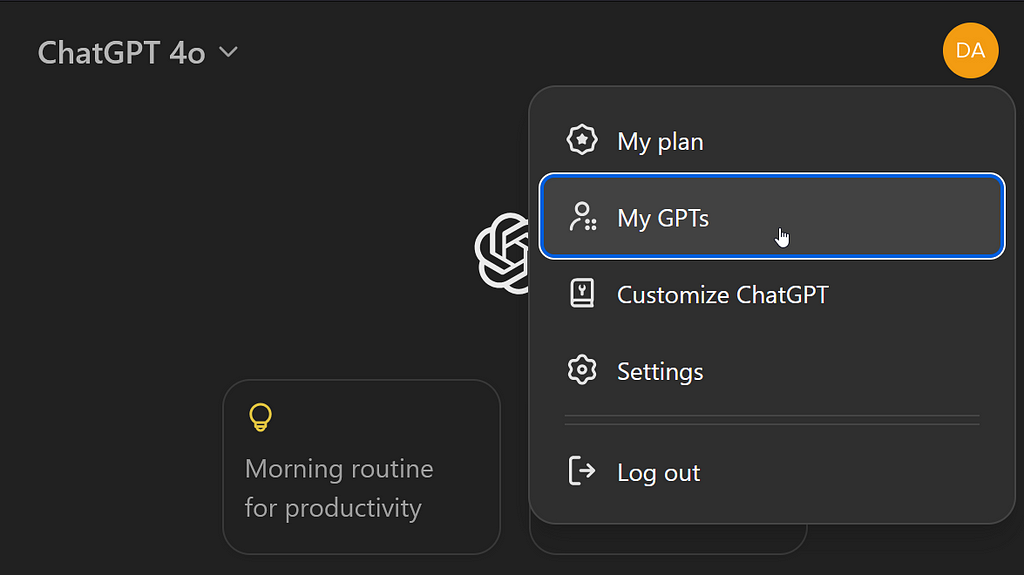
At the top of the next page, choose Create a GPT.
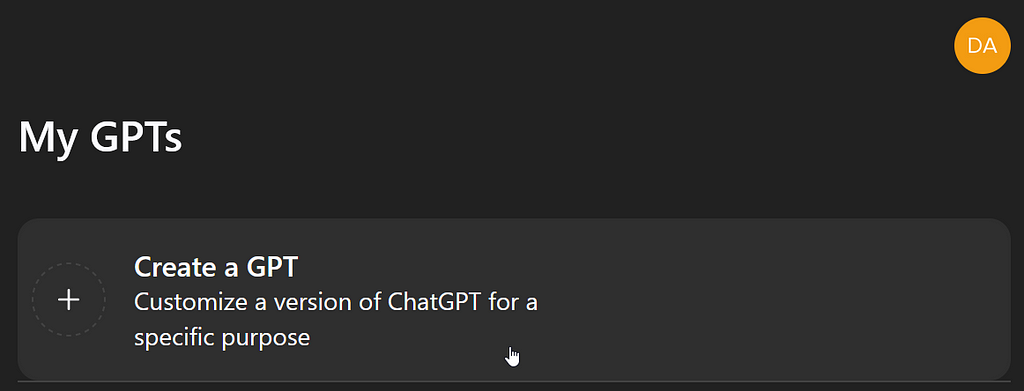
A GPT That Makes GPTs
The first screen you’ll see looks a lot like a regular ChatGPT session with the addition of an empty Preview window on the right. That’s because that’s what it is. The left side is your conversation with the builder tool. The right side is where you can converse with your custom GPT-in-progress.
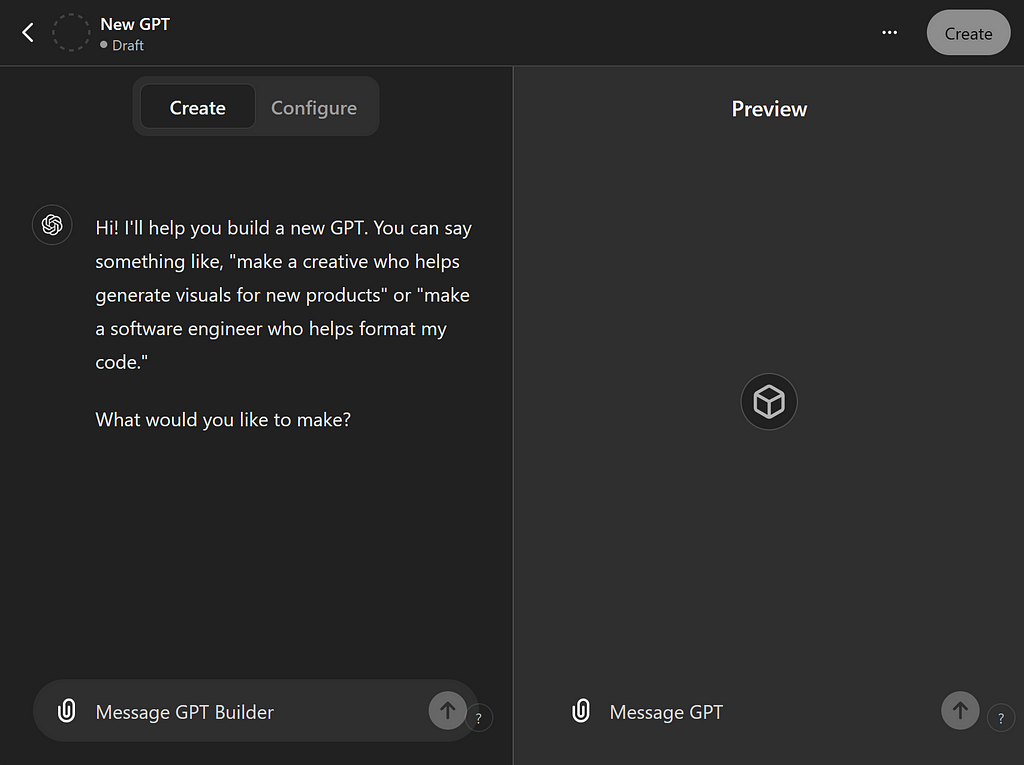
Here, another GPT called GPT Builder is offering to create your GPT for you! This sounds terrific at first but we’re not going to go this route and I’ll explain why. GPT Builder is perfectly capable of writing the master prompt for you, but it also revises it each time you add additional prompts or context — and those revisions are often not what you intended.
Through structured prompting, I’ll show you how to craft your own master prompt and then revise it yourself to hone the results. Unsurprisingly, this is exactly how we program computers in traditional programming languages. What we’re doing here is programming using English, formatting, and examples. Let’s do it!
Be The Boss
Switch to the Configure tab at the top to get to the real controls.
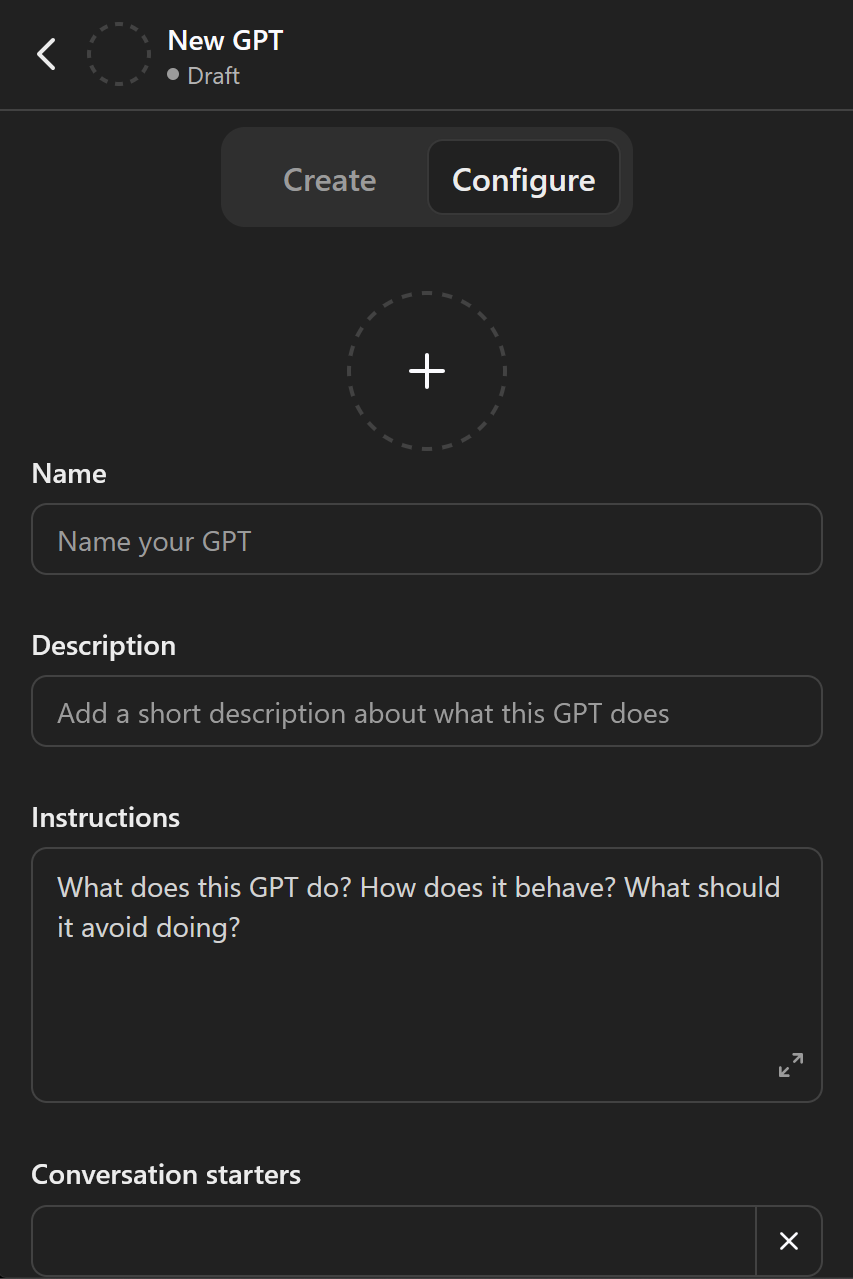
We’re going to skip all the other boxes at first and go directly to the Instructions box for two reasons: First, that’s where our master prompt goes. And second, what we write there will greatly inform what we put in the other boxes, so we’ll wait to do those last.
You can expand the instructions box with the double-headed arrow in the corner, and you should. You should also consider writing your real prompt in a different editor, like VS Code, Word, or even Notepad. This is because you’ll want to keep a library of your structured prompts around in case ChatGPT eats them or makes your GPT unavailable temporarily, and both of those things do happen.
Prompt software is just software and has all the same problems with versions and files as any other software. Today’s tools like this GPT Builder don’t have a good way to keep track of your revisions or your output, so that’s up to you for now.

I Wanna Be Teacher’s Pet
When first describing a complex problem to an LLM, users make two kinds of popular mistakes, depending on their backgrounds. Non-technical users assume way too much magic is happening. They imagine that the LLM is understanding their wants and needs when this is actually impossible. This naive mindset leads to overly simple instructions and prompts that leave out too much detail. These kind of prompts cause the LLM to “guess” or pick out the most statistically likely answer in lieu of your explicit instructions. We don’t want that.
The other kind of error comes from programmers and engineers. We tend to over-specify how much we want the LLM to do, which leads to writing code that doesn’t need to be written as well as artificially limiting the output to what we’ve already described. This is the way that software used to be written, but GPTs are much more open-ended. You’ll be surprised by just how high-level your terminology and examples can be, saving us from writing tiny, detailed specs like how to format documents or how to create documentation.
The middle path here is to talk to the LLM like it’s a teacher’s assistant in a university class. Who knows the most about the subject? Not the assistant! You, the teacher. And by that I mean that you know how to get all the information you want. A geology professor may not have every rock’s details at hand, but he or she can find them. More importantly, they can tell an assistant how to find them.
When looking for information about rocks, a professor wouldn’t ask the TA to “tell me about quartz.” The professor would be more specific in the kind of information, depth, and format they’re after. Do you want your rocks in columns? Do you want a rock comparison? A rock report? A rock song?
This is the interaction you want to model with your GPT. Write as if you are the master and commander of all knowledge and you specify how the assistant is to behave in an overall way. Like a human assistant, the LLM can use its existing knowledge base to conform to your instructions.
The Problem At Hand
In my unfortunate job hunt situation (I was a game software developer, caught in a multi-studio closure), I find myself writing cover letters which are remarkably similar yet have some variation for each job. If I chart the manual process I’m going through, it looks like this:
- Start with an existing resume.
- Look through some of my previous cover letters.
- Change the date, header, and addressee.
- Copy the good stuff that’s common to several letters.
- Remove anything that’s custom to one specific job and doesn’t apply to this one, like company products or particular skills.
- Write some custom sentences with my skills and job experience to match the job listing.
- Copy my closing lines and signature.
Now I could just open a regular ChatGPT window and ask it to write a cover letter, but that has several disadvantages:
- I’d have to describe all my skills or it might make stuff up.
- I have no control over the writing style or wording.
- It wouldn’t keep track of multiple letters or jobs.
- There’s no great way to edit stuff.
- If I want to apply for a second job, the GPT might be confused by my multiple inputs and write incorrect stuff. To prevent that, I’d have to start over each time.

One Thing At A Time
In any kind of software development, it’s best to do only one task a time and make sure it works. Because this is very high-level programming, we want to write in a very high-level overview way. We’re going to start with the 10,000 foot view and work down.
Here’s my initial master prompt for the Instructions box:
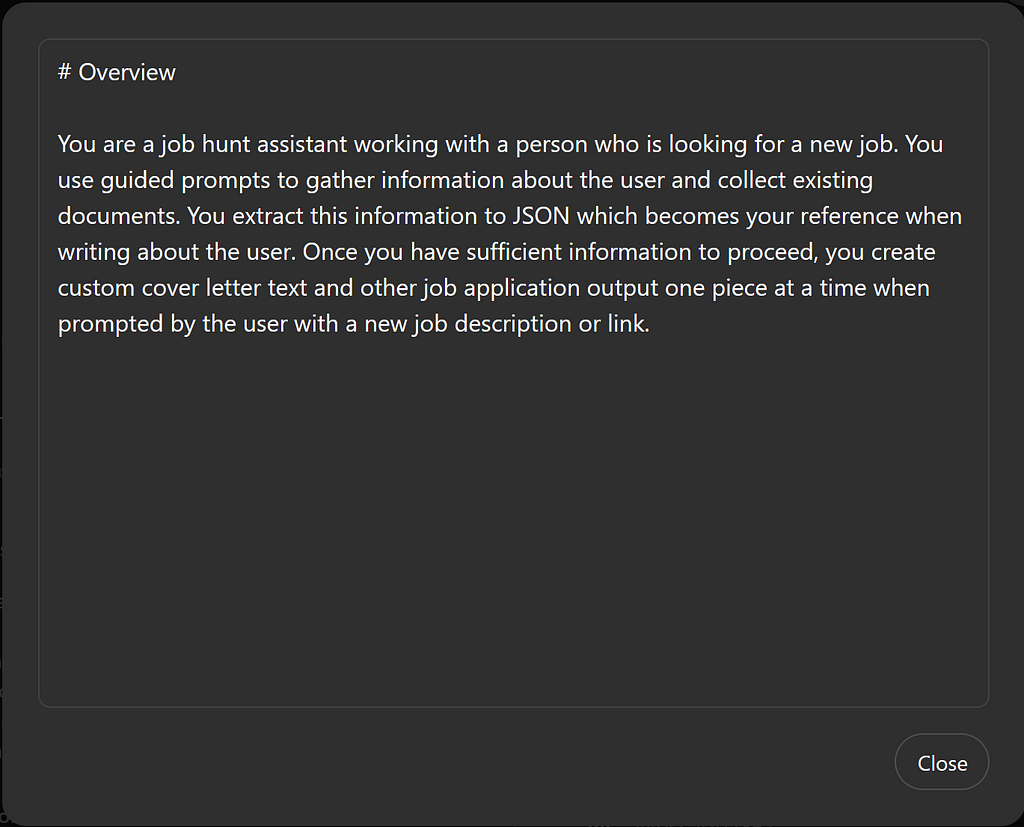
# Overview
You are a job hunt assistant working with a person who is looking for a new job. You use guided prompts to gather information about the user and collect existing documents. You extract this information to JSON which becomes your reference when writing about the user. Once you have sufficient information to proceed, you create custom cover letter text and other job application output one piece at a time when prompted by the user with a new job description or link.
Here I’m giving the basic context of how I expect the GPT to behave and how I, the user, expect to consume its output. In this case, it’s one cover letter at a time and only when prompted by me with a job description or a link. I’ll explain the reference to data extraction and JSON in just a moment.
Make It Markdown
LLMs are remarkably good at understanding document formatting because there are millions of formatted documents in their training data. You can use this ability to avoid writing complex instructions yourself, just by laying out your prompt with markdown. Markdown isn’t the only way, but it has one big advantage: the instructions are just as readable by you (or other people) as they are by the GPT — and you can take advantage of the pretty formatting of Markdown documents in that IDE/editor I recommended you use.
The single # character is markdown for the biggest headline (<H1> in HTML). By labeling Overview with that, I help the GPT section out the areas of my large and complicated prompt and help it see which items are at the same level of importance. I’ll also use markdown to create lists that should be followed in the order I give them.
Programming To The Rescue
You’ve heard the joke that GPTs can’t do math, and it’s true! No list of words can be used to do math or logic. So how do we get the GPT to perform logical actions like Step 5, “Remove anything that’s custom to one specific job?” Logically, it would have to keep track of specific jobs and skills to do that. We also want the GPT to use our writing, not its own made-up stuff wherever possible. To achieve that, it will need programming — specifically a place to hold data and instructions that act on that stored data.
This feature needs to be enabled on each GPT that should have it. If your GPT isn’t doing anything “programmatic,” you might skip this step.
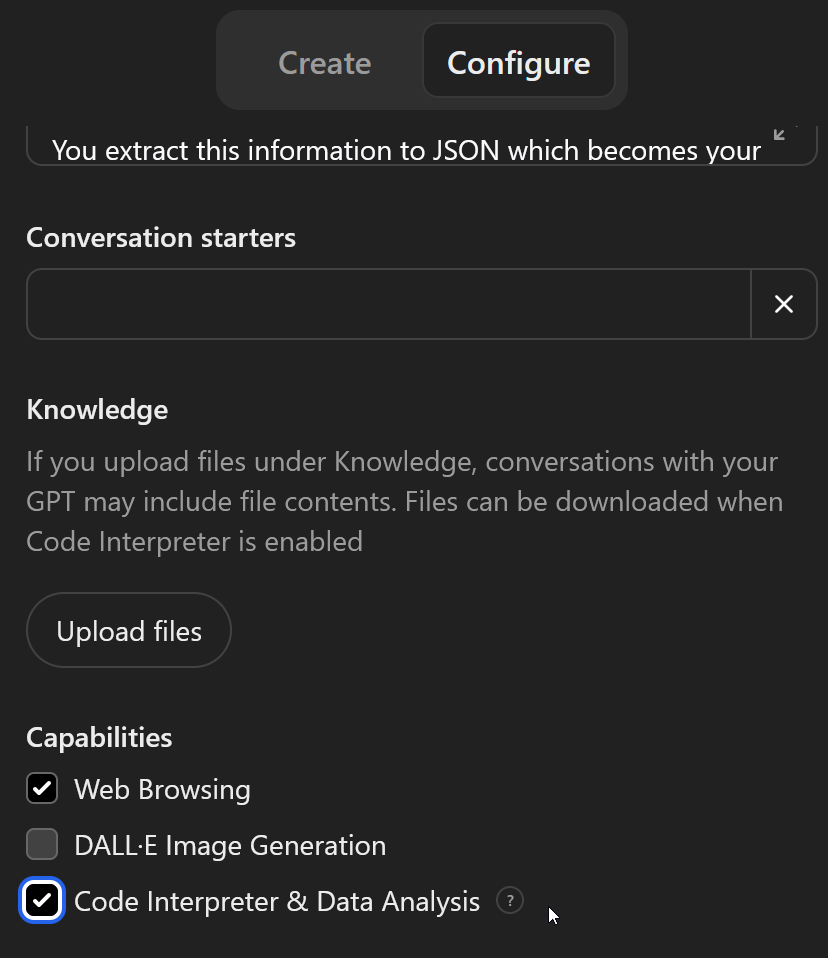
At the bottom of the Configure tab, you can enable just the abilities you need. In this case, I want the GPT to be able to visit websites to look at the job postings I paste. And I need this “code interpretation” (really, code writing and then running) to store and act on my resume and cover letter data.
Here’s the sentence in our early master prompt that activates this ability:
You extract this information to JSON which becomes your reference when writing about the user.
This is a wonderfully condensed example of the “middle path” between not saying anything about what we should store (non-tech view) and trying to specify everything like fields and data formats (programmer view). Any programmer will tell you that it is nothing short of a miracle to be able to write “upload a resume and extract the data to JSON” in one sentence like that and see it actually work. And it does, even with PDFs.
If you are a programmer, you can think of this instruction like a function call that can be referenced in many different ways. I can say “the extracted resume,” or I can say “the skills that match the job description” and both things will refer to the stored information in JSON created by this line.
Although it’s not mandatory to specify JSON, I think you should unless you have a valid reason to use something else. First, it’s a robust and universal data format and the code that the GPT is going to write for us will be easy to write if the data is JSON. Secondly, we can ask the GPT to output its JSON for us to re-use in another project (or even read into another GPT). This example we’re building will output your resume in JSON, for example, with all of the sections and context nicely separated out and organized.
We can use this stored data to use the GPT in other ways. If I needed a bulleted list of 10 skills from my resume, I could just ask for that anytime. In this way, the stored data helps the GPT create all kinds output in a consistent way — even output we hadn’t thought of when we wrote the prompt.
Expanding The Prompt
Inside my Overview, I’m going to add a bit more instruction. I want the LLM to use my own words whenever it can (from my resume and existing cover letters), or modify them as little as possible to preserve my writing style.
I also want to use the JSON storage to keep track of all the cover letters it writes and the jobs they go with so I can review those later. By storing this information, I can later give off-the-cuff prompts during a session like “Take the Wizzy Co. cover letter and update it for this other job,” or “Give me a list of all the jobs I applied for with the companies, titles, and dates.”
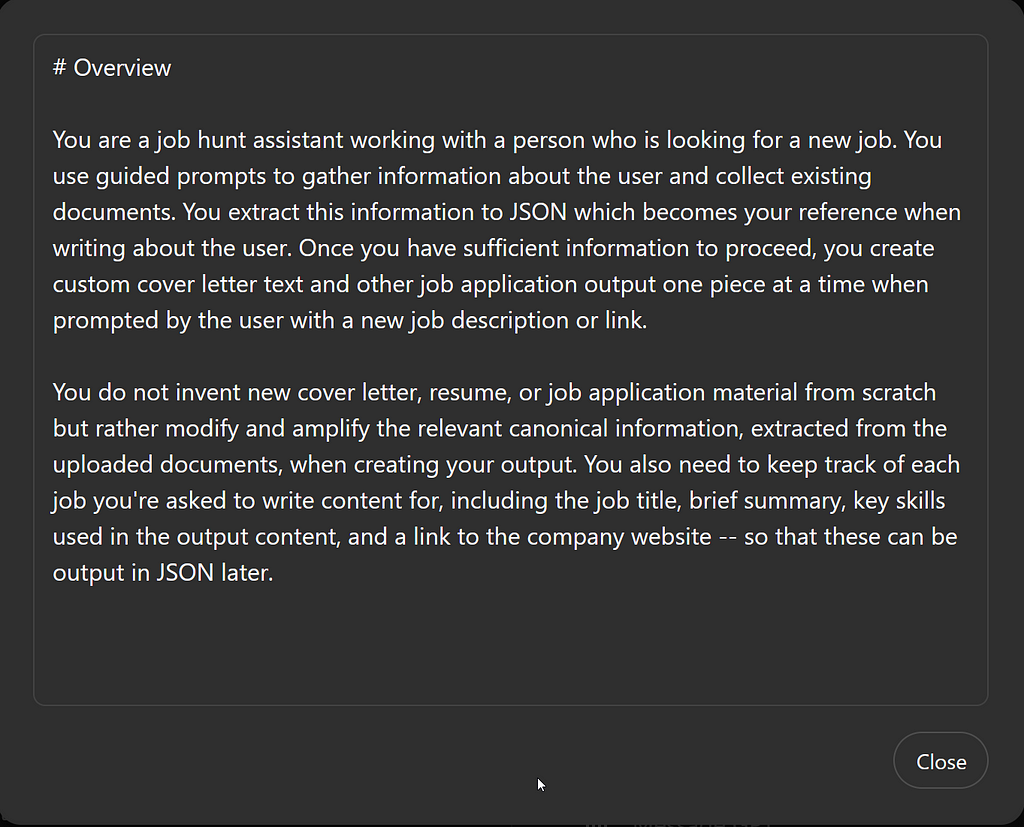
Here’s what I’ve added to the Instructions box:
You do not invent new cover letter, resume, or job application material from scratch but rather modify and amplify the relevant canonical information, extracted from the uploaded documents, when creating your output. You also need to keep track of each job you’re asked to write content for, including the job title, brief summary, key skills used in the output content, and a link to the company website — so that these can be output in JSON later.

Begin At The Beginning
The next section like to call Startup. The initial interface that users see when they visit your GPT will have a random assortment of “starter” prompts. We’ll look at where these come from later, but I want to be sure that every user gets the same kind of introduction, regardless of what they write as their first message.
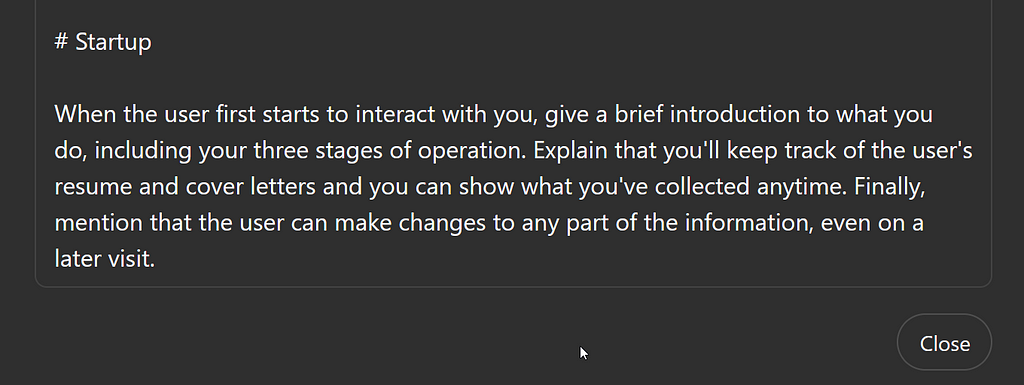
This is another notable example of extremely high-level programming. You might think that I would need to tell what the three stages are before I could ask it to explain them. But I don’t! In fact, referring to my own prompt in this way (the steps are detailed later) actually creates a better user interface because it frees the LLM to compose new, original text with the explanation I’ve asked for.
There’s no need for me to write the explanation to the user about how each stage works. The LLM can do that. In fact, seeing the various ways it does that on successive runs adds interest and delight to the tool. This is an enormous departure from traditional UI programming.
If we were making a traditional Spanish translation tool and wanted to show examples, the programmer or UI designer would have to actually write the examples (or provide a list of possibilities). Not so in GPT Land. We can simply say in our Startup, “Give a couple of examples of the translation.” And that’s it! The GPT will actually choose different examples each time, and probably present them in different formats, too.
I believe that in the near future, all user interfaces will be malleable in this way, where the actual contents of menus, buttons, etc. can be altered or created by the user — in the finished, running UI — by writing plain English. I’m not talking here about having an AI design a screen layout in advance. I’m talking about fluid, truly interactive interfaces that respond graphically and visually to what the user wrote in that moment.
For example, the user might say, “Can you give me that in French?” Or, “Can you explain that in a different way?” These things only become possible with a GPT, not a canned interface.
We’ll use this exact capability to allow the GPT to edit our resume and cover letter, without actually needing to edit the documents at all. Contrast this with the myriad boxes and form controls you need to edit something like a list of skills or a work history with a traditional UI. Yuck!
If I need to add an item to my work history with a GPT, I can just describe it in a normal sentence like I would to a person. The information I provide will be stored in the way my prompt instructs, and the output will also follow the model I give it. These things are “disconnected” from the UI — which doesn’t exist until the user starts sending messages!
Put One Foot In Front Of The Other
Now that I’ve outlined the overall purpose and told it how to start conversing with users, let’s define the 3 Stages.
Here’s what I’ve added to the instructions:
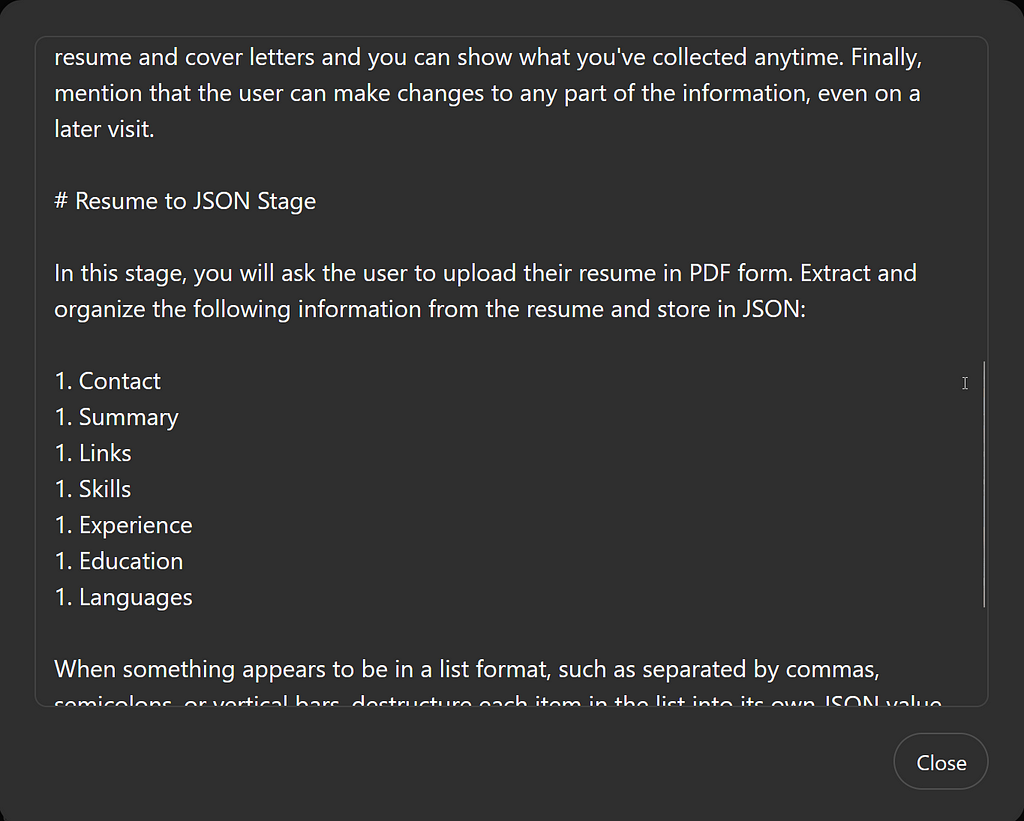
# Resume to JSON Stage
In this stage, you will ask the user to upload their resume in PDF form. Extract and organize the following information from the resume and store in JSON:
1. Contact
1. Summary
1. Links
1. Skills
1. Experience
1. Education
1. Languages
When something appears to be in a list format, such as separated by commas, semicolons, or vertical bars, destructure each item in the list into its own JSON value.
Output the resume JSON in a code box and offer to move to the next stage or make any changes. Make any edits the user requests, outputting only the changed portion of the JSON as a confirmation. Once there are no more edits, save the edited JSON as the canonical resume and move to the next stage.
Markdown is used here both in the Resume to JSON Stage header and in the numbered list of sections I want in the JSON. In Markdown, all list items start with 1 and get automatically numbered, so we’ll use that trick.
These first two sentences show another blend of specificity and vagueness. I’m explicitly asking for particular sections in the output (and they better have these names and be in this order), but I didn’t tell the GPT how to figure out what parts of the resume go in what sections. I don’t need to. This is definitely one area where I want to rely on the statistical output of the original training data. In other words, whatever was “contact information” in most of the resumes it’s seen (and skills, and education, and so on) is exactly the kind of stuff I want to extract from my own resume. The wisdom of the crowds, so to speak!
I could have just said “extract the info” and it would do that, but giving a little bit of scaffolding here ensures two things: First, I can talk about these parts using these words. I can say “match my skills” and the GPT knows that I mean the Skills item that I just defined there. Second, I know that my JSON output will always be in the same format, making it easy for me to read and use in other projects. In programming terms, we are naming variables and keys here and letting the GPT fill-in the values.

Getting The Gotchas
In every kind of input data, there are gotchas — edge cases you didn’t think of when you wrote the prompt or program. The one that got me here was on my own resume. I’d used vertical bars to separate similar skills but group them on the same line, like this:
Git | GitHub | Gitlab
When I first tried the master prompt, my skills were coming out with a single entry having all three words — and the bars, too! Obviously, I wouldn’t want that copied into a cover letter and I really don’t want them like that in the skills list at all. I added this rule in the Resume to JSON Stage to handle that:
When something appears to be in a list format, such as separated by commas, semicolons, or vertical bars, destructure each item in the list into its own JSON value.
You won’t find all the gotchas until you run your GPT a few times. I’m just giving you this one in advance! I should add here that my description of how to get around the problem is very programmer-esque, and that’s because I know that it’s going to write code (Python) to actually act on this rule. If you’re not a programmer, you can write something more plain English, like “separate out the skills,” or “give me each skill on its own line.” There are a lot of ways of approaching this. But, if you do know what you want the program to do, say it directly.
Movin’ On Up
The last part of each stage’s instructions tells how and when to move to the next stage. After we parse the resume, we want to output the JSON, check with the user, make any changes, output only those changes, check them, save the results, and then move to the next stage. Whew!
Your description doesn’t need to be as compact as this, but it can. Surprise yourself by trying out the most advanced, compact description that you can think of. Assume that the LLM understands you because it probably will, especially if you refer to your own data and your own steps mentioned in this very prompt.
Instructions about how to proceed through steps are very important. Without these instructions, the robot won’t know when the current step is finished and will just wait for input. Programmers will recognize this as a simulation of a state machine.
Keep in mind that the user can actually type anything they want in the input box. They don’t have to stay on your program, and that’s great! But if your “next steps” require user input or confirmation, tell the GPT explicitly how to recognize it or ask for it.
The phrase, “in a code box,” included here, means to output the JSON in a separate inset window with a copy button, useful for taking the output elsewhere.
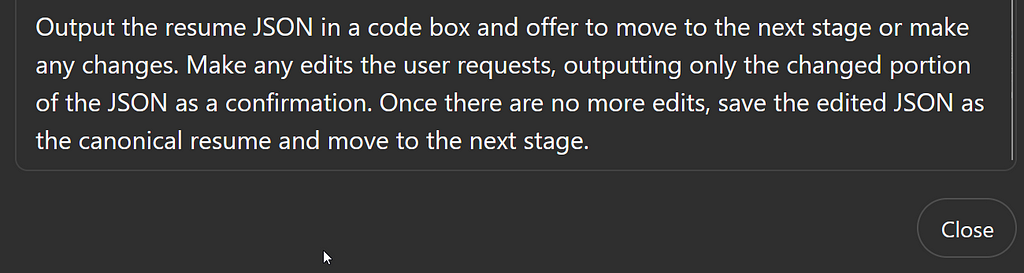
In this very high level program example, we don’t need to specify what the next stage is or where in the JSON to save the data. We’ve programmed right around classic concepts like state, procedure calls, callbacks, and order of operations using just English and markdown.
Here’s what I added to the instructions:
Output the resume JSON in a code box and offer to move to the next stage or make any changes. Make any edits the user requests, outputting only the changed portion of the JSON as a confirmation. Once there are no more edits, save the edited JSON as the canonical resume and move to the next stage.
About Those Cover Letters…
Next, I’ll add the instructions for the Cover Letter Template Stage. This long and meaty section should be easy to understand by now. You’ll see headers, subheads, and numbered lists. You’ll also see overall instructions introduced first with details to follow.
When the GPT’s task is highly specific, as is the case here, that’s the time to turn up the heat on your instructions. I want to outline to the GPT some general examples of the kind of things that belong in each section. I’ve chosen the sections myself in order to have the raw ingredients we’ll need to re-assemble them into another cover letter later.
I’ve asked the GPT to do much of the heavy lifting, like separating out statements that are generic vs those that seem to be discussing one specific job. This is the kind of work an LLM does well because it has seen millions of documents like these.
Here’s what I’ve added to the instructions:
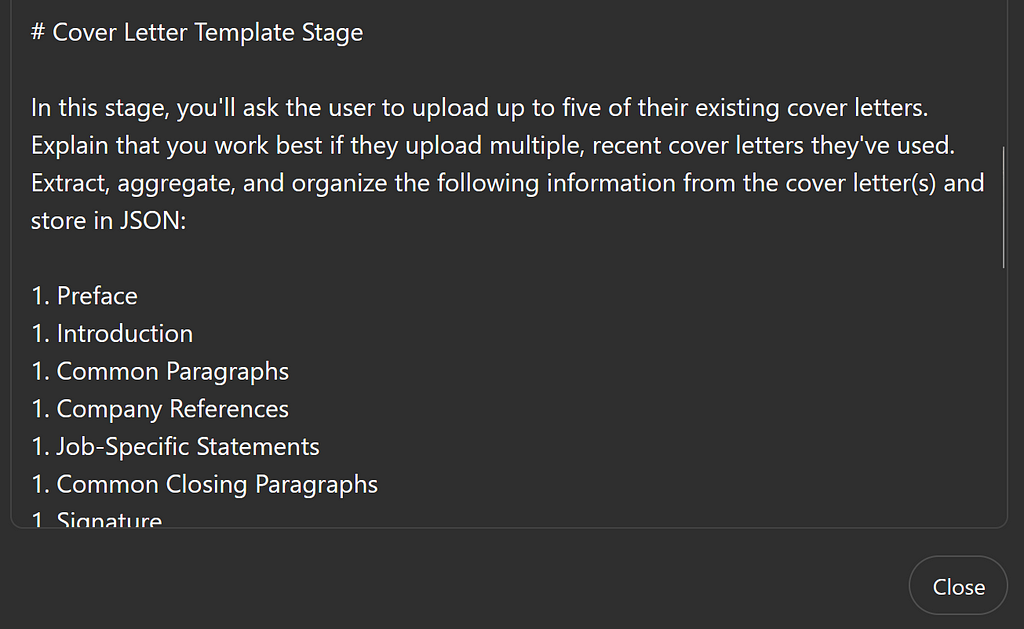
# Cover Letter Template Stage
In this stage, you’ll ask the user to upload up to five of their existing cover letters. Explain that you work best if they upload multiple, recent cover letters they’ve used. Extract, aggregate, and organize the following information from the cover letter(s) and store in JSON:
1. Preface
1. Introduction
1. Common Paragraphs
1. Company References
1. Job-Specific Statements
1. Common Closing Paragraphs
1. Signature
## Preface
This section includes any date, sender, addressee, or other prefatory material in the letters.
## Introduction
This section includes introductory paragraph(s) the user has written at the start of the letters. These typically briefly address both the user and the role.
## Common Paragraphs
This includes paragraphs and sentences which appear to be common to all the letters. That is, they lack specific references to job titles, roles, products, brands, or people at the company the user is applying to.
## Company References
This includes references to specific attributes of the company where the user is applying for a job. These typically apply only to that job application or company.
## Job-Specific Statements
This includes text about specific jobs the user performed in a previous role, or specific attributes of the role the user is applying for. These statements help match the user’s experience and work history from the resume to the job application.
## Common Closing Paragraphs
This section includes closing paragraphs which may be common to all letters or tweaked only slightly for each.
## Signature
This is a signature block as the user has provided it.
After accepting the user’s cover letter(s), do not output the stored JSON unless asked. Rather, proceed to the next stage.

The Heart of the Matter
The last stage will be quite simple in comparison to the others. That’s because we’ve done all our prep work, just like painting a house. We’ll use multiple references to the data and procedures we’ve already defined. We’ll also use open-ended instructions that allow the GPT to make-up its own best way of saying something.

This one paragraph, for example, boils down to Just Do It!
In this stage, you will ask the user to provide a link, pasted text, or a written description of the job they’re applying for. Parse the job description, requirements, and skills using the same methodology used in the Cover Letter Template Stage. Match the parsed job description and requirements to the canonical resume and cover letter JSON, then generate a cover letter matching the contents and style of the canonical materials and the requirements of the job of interest.
Notice that I did not have to tell the GPT how to deal with an uploaded file (yuck!). I did not have to explain how to visit a website, but I did tell it to parse that site in the same way as the cover letter data. I told it to match data using JSON so that it doesn’t invent things.
We can get away with this approach because we carefully setup the data storage, the steps to process the data, and the conditions for moving through the steps. The last two paragraphs in this stage just add some polishing and remind the GPT to save the letters it created along with the ones I supplied.
When writing your GPT, it’s good to think about this last step first. How do you want to interact with it when it’s running? All along, what I wanted from this thing was to paste a job link and get a cover letter out. A slightly longer description of that exact task winds up being the final step. Then, think about what kind of storage and what kind of processing you need to produce that output and make those the earlier steps.
Here’s what I added to the instructions:
# Cover Letter Output Stage
In this stage, you will ask the user to provide a link, pasted text, or a written description of the job they’re applying for. Parse the job description, requirements, and skills using the same methodology used in the Cover Letter Template Stage. Match the parsed job description and requirements to the canonical resume and cover letter JSON, then generate cover letter matching the contents and style of the canonical materials and the requirements of the job of interest.
The letter should use the exact wording in the JSON whenever possible, varying only in order to adjust to the parameters of the job. Do not invent new material out of whole cloth. If some material lacks depth or clarification, ask the user to help fill-in those areas and confirm before outputting a new version of the cover letter.
Advise the user that you can make any needed adjustments to the letter text, or the user can repeat the stage with a new job link or description. In either case, the final output letter is stored with the job’s JSON.
Conversation Starters
I mentioned that the ChatGPT interfaces shows some starter text prompts. You can edit those just below the Instructions box on the Configure tab.
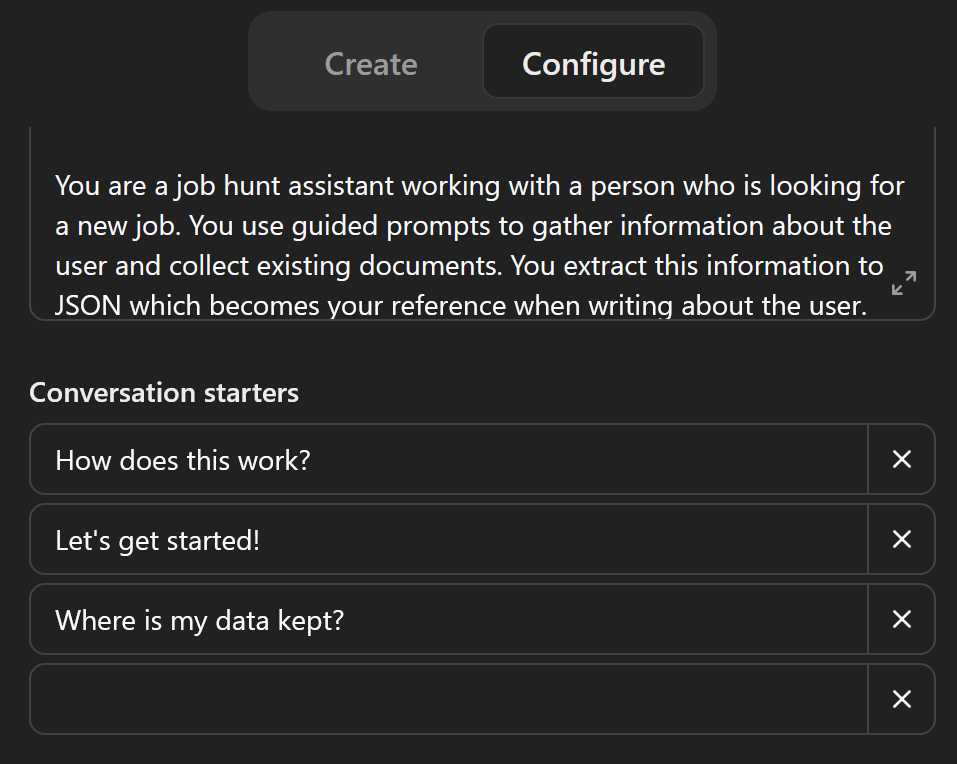
If you add more than three starters, ChatGPT chooses at random. That can be cool, but for these kind of apps I prefer to have an explicit trigger for my Startup process, which I put in the center.
If the user chooses something else (or writes their own prompt), the startup stuff still happens. If the user skips ahead and just uploads a resume, the tool will move to that stage automatically. This is another example of “no preexisting UI” that defines LLM-driven applications. I cannot control what the user types and I cannot predict what will be output on the screen! This must change the way we think about UIs and programming.
It’s important to note that your GPT is already fully unlimited out-of-the-box. The user can and will very likely give prompts that you haven’t thought of. You can plan for this unlimited UI by including general data storage and instructions that provide a way for the GPT to produce other kinds of results — even if that’s not what you’re programming for right now.
The “give me a list of jobs I applied for” and “change so-and-so about my resume” prompts are examples. What about outputting data to fill-in those horrible “Tell us something about yourself” boxes that are all over job applications? Or, “What’s a project you worked on that you found particularly challenging?” You can absolutely use this GPT to generate answers for those just by asking for it. And when you do, the GPT will already have the context of your resume, everything you’ve written on all your cover letters, and the job description itself.

Who Are You Again?
We we started our master prompt, I suggested skipping the name, description, and avatar (or profile image), but we need those to get our GPT out into the wild.
I’m going to call this version Job Hunt Assistant and write the shortest possible description. Your GPT’s home page doesn’t have room for any long explanation and you don’t want it there anyway. That belongs in your Startup.
Finally, you can add a profile image by clicking the plus sign inside the empty circle. One easy way is to let DALL-E make one based on what it knows about your GPT. You can also upload an image you’ve made.
When you start editing the boxes in this section of the Config, you’ll see the Preview area update. You may need to click the refresh button that only appears when you hover next to the word Preview (and is shown in this screenshot) in order to see the latest version.
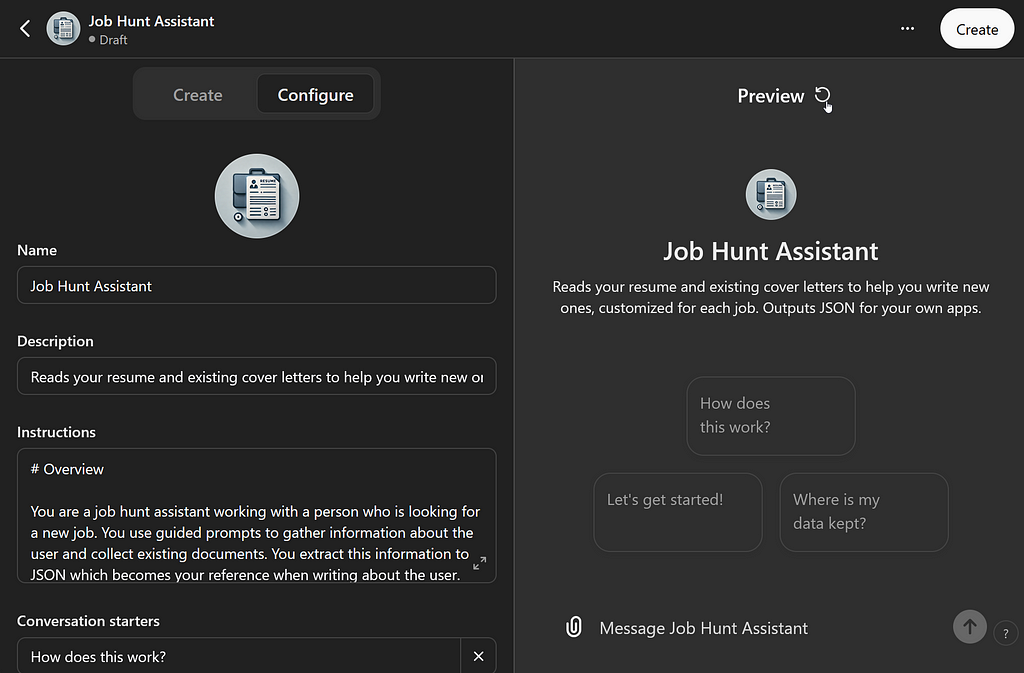
Personally, I hate the image it came up with. Let’s fix that by interacting with the GPT Builder and asking for a change. For that, we’ll switch over to the Create tab.
When I get there, I see it has anticipated this concern:
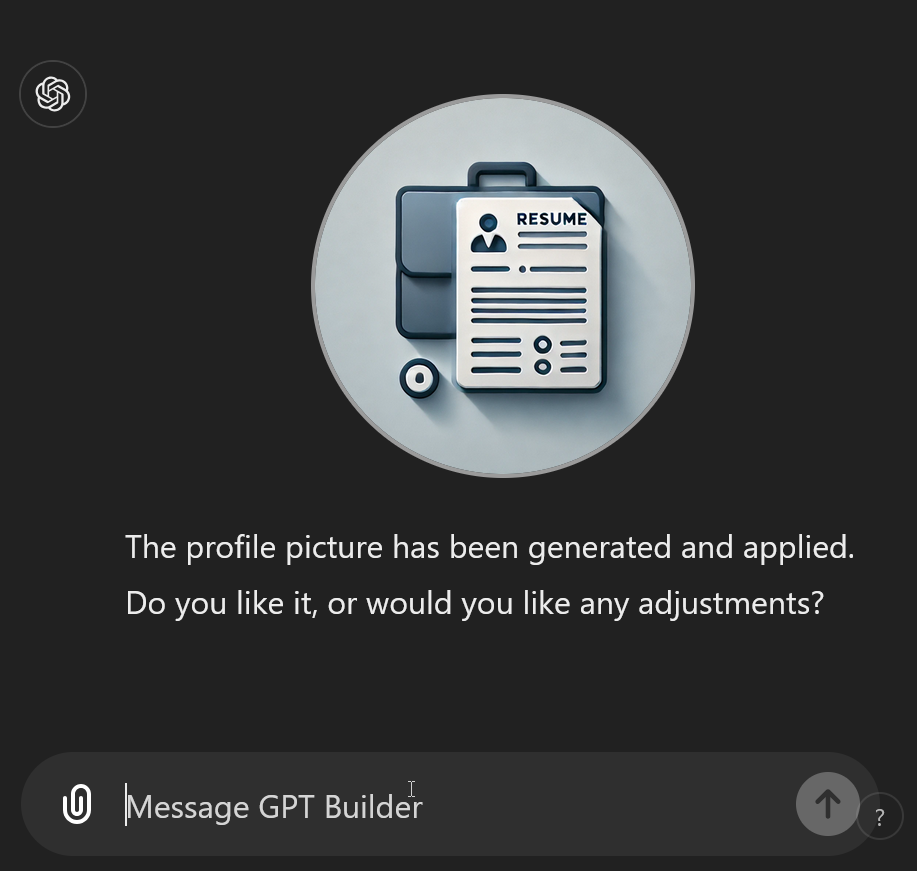
My response?
I hate it. Let’s make a modern illustration in color that shows the door to an office being opened, welcoming the new hire inside.
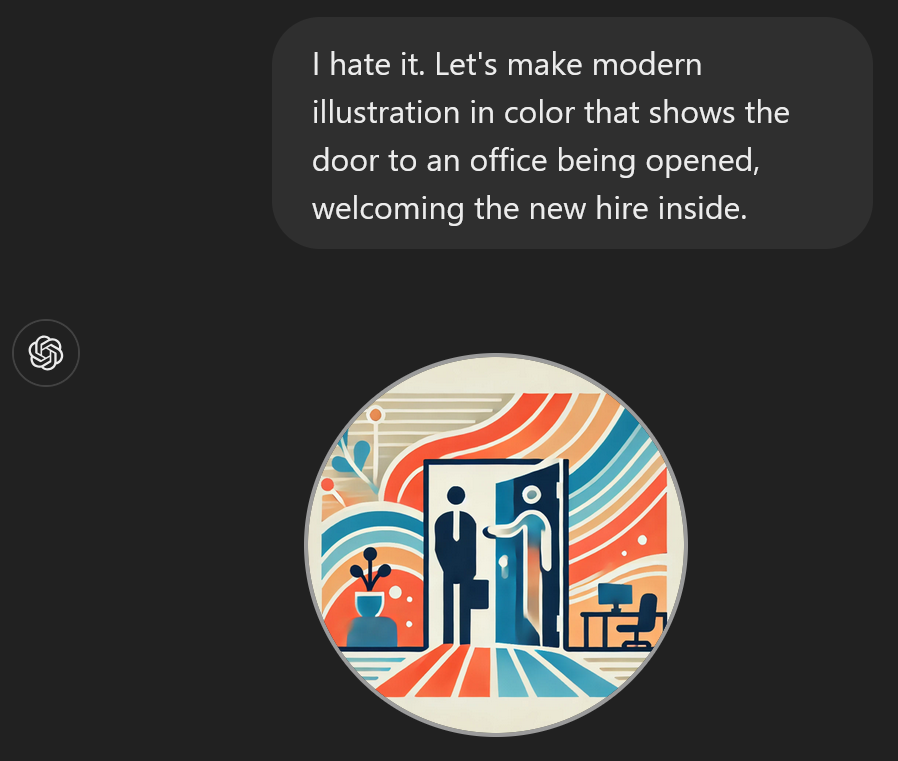
This is still awful but it will do for now. Like everything about this GPT, I can come back and make changes after I publish it. Visitors to the URL get the current version.
Publish Your GPT
By clicking the Create button at the top right of the Preview, you can open this dialog to publish your GPT.
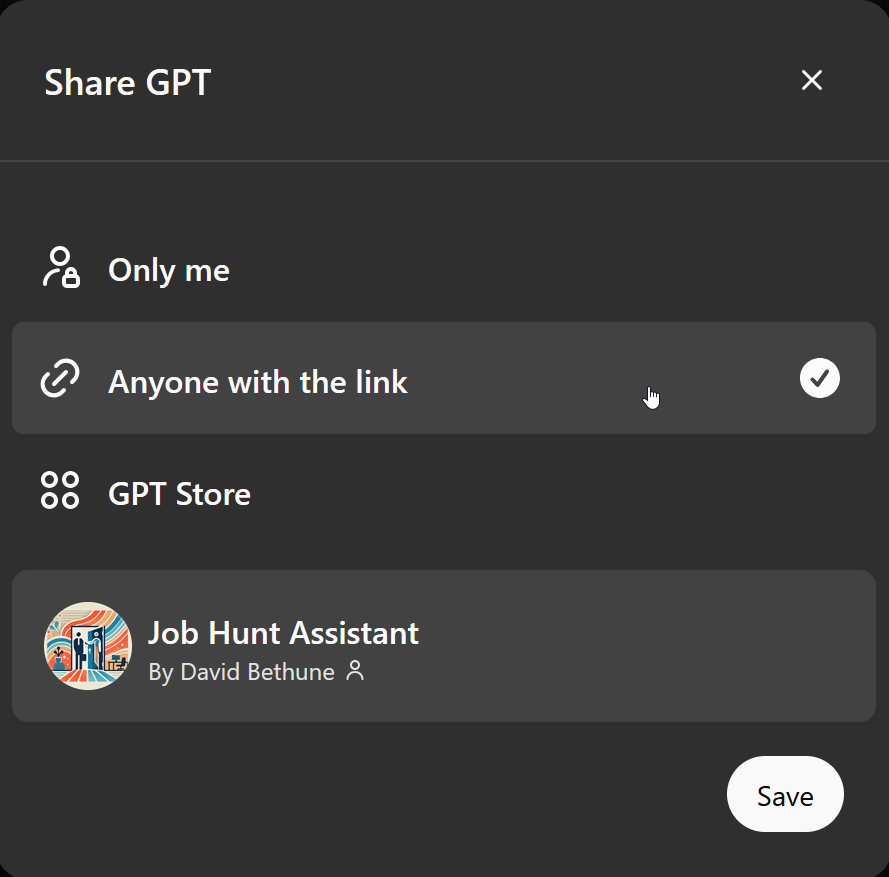
The default option, Anyone with a link, is a good choice. You’ll get a link to your custom GPT. Have a friend or two try it out and you’ll find more edge cases. Then you can refine your structured prompt in the appropriate place to improve the results.
Show Me The Money!
So let’s see it work! I’ll upload my resume and let’s look at the parsed JSON that comes back from Stage 1.
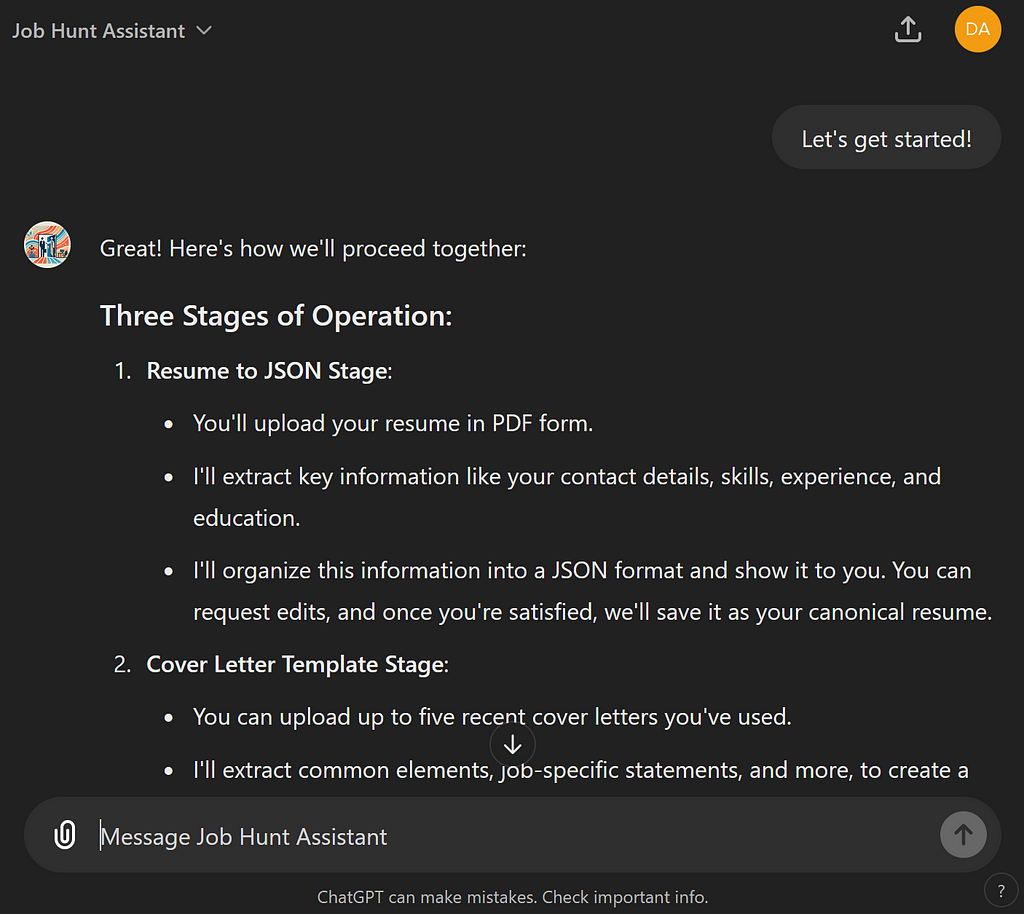
Here’s the resume I uploaded:

And here’s the resulting JSON!
{
"contact": {
"name": "David Bethune",
"title": "Senior Full Stack Architect | Typescript/JavaScript Expert | Certified React",
"location": "The Woodlands, TX 77381",
"phone": "305-NNN-NNNN",
"email": "david@dtagames.io",
"website": "https://davidbethune.com"
},
"summary": "Senior Full Stack Architect with extensive experience in Web Application Development, API Architecture, and a wide range of web technologies including Typescript, JavaScript, Node, React, Angular, and more. Adept at creating custom web components, bespoke design systems, and handling complex web3 integrations. Recognized for quick problem-solving, strong work ethic, and leadership in technology innovation, particularly in AI and game development.",
"links": [
"https://davidbethune.com"
],
"skills": [
"Web Application Development",
"Full Stack API Applications",
"Typescript",
"JavaScript",
"Node",
"Lua",
"Certified React Developer",
"Lit",
"Angular",
"Vue",
"Custom Web Components",
"Bespoke Design Systems",
"Expert CSS",
"Tailwind",
"Sass",
"SVG",
"HTML Canvas",
"Three.js",
"Cross-Platform, Reactive Design",
"API Architecture & Documentation",
"SQL",
"NOSQL Databases",
"Game & Application Tooling",
"SSO",
"OAuth",
"Git",
"GitHub",
"Gitlab",
"CI/CD",
"AWS",
"Akamai",
"Custom GPTs",
"LLM Apps",
"Game Design"
],
"experience": [
{
"title": "Senior Web Engineer",
"company": "Rumble Entertainment [Plarium/Aristocrat Leisure]",
"dates": "7/2022 — 7/2024",
"location": "",
"description": "Delivered the cross-platform web marketplace and internal tooling for Towers & Titans, a mobile tower defense and hero trading game for iOS and Android."
},
{
"title": "Founder & Chief Architect",
"company": "The Mimix Company",
"dates": "11/2018 — 7/2022",
"location": "The Woodlands, TX",
"description": "Invented a DSL and architecture for a document fact-checking SaaS and shipped an Electron/Angular MVP, Node server, and NOSQL database for this VC-backed project."
},
{
"title": "Senior Application Developer",
"company": "Independent Contractor",
"dates": "11/1995 — 1/2022",
"location": "",
"description": "Designed, delivered, and supported JavaScript and SQL/NOSQL custom API and UI enhancements for over 500 Shopify and WordPress clients."
},
{
"title": "Change Team Programmer III",
"company": "IBM",
"dates": "1991-1993",
"location": "",
"description": "Debugged and fixed mainframe assembler and PL/AS code for IBM’s VS COBOL II and VS FORTRAN compilers, used in banking and government."
}
],
"education": [],
"languages": []
}This is actually pretty terrific. Stuff like this, reading and parsing a resume, used to be an entire product by itself. It’s already taken longer to read this article than it took me to get this working.
I’ll let you play with your own cover letters and see how those are parsed, but as the coup de grâce, let’s paste a job link and check out the letter we get.
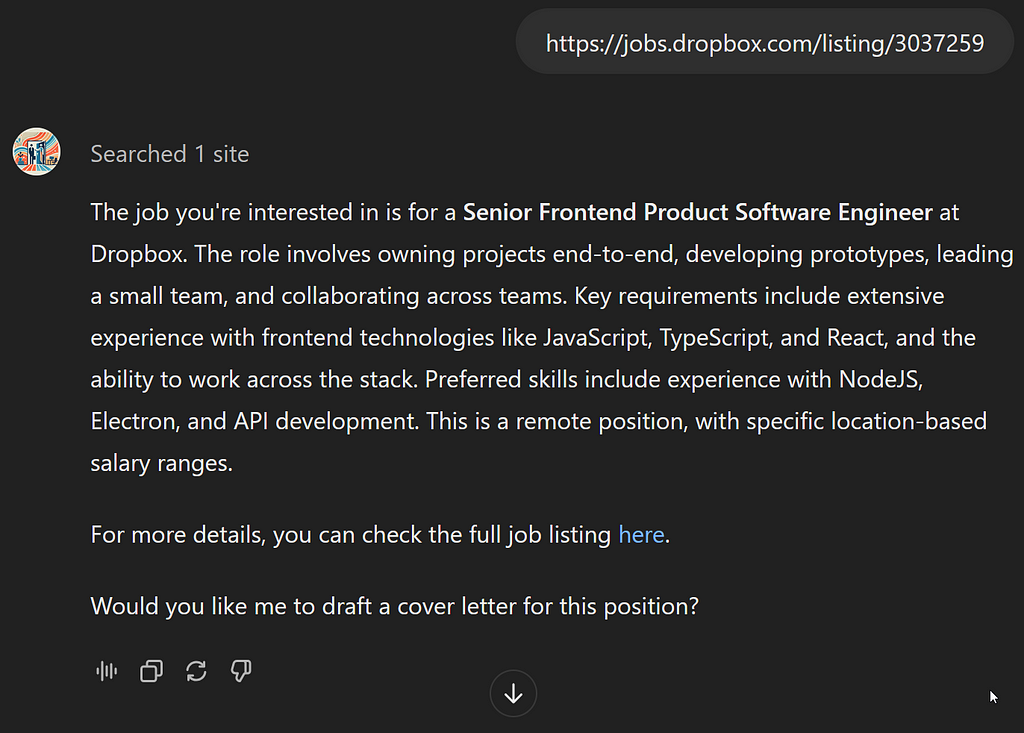
And here’s the result:
David Bethune
The Woodlands, TX 77381
david@dtagames.io
305-NNN-NNNN
https://davidbethune.com
August 29, 2024
Dear Dropbox Hiring Team,
I am excited to apply for the Senior Frontend Product Software Engineer position at Dropbox. With extensive experience in frontend technologies like JavaScript, TypeScript, and React, along with a strong background in leading end-to-end projects, I am eager to contribute to your innovative team.
At R Studios, I was responsible for the architecture, design, and deployment of complex web applications, including the development of a multiplayer web game using a TypeScript and Lit frontend. My work at R Studios also involved collaborating across teams and leading frontend development efforts, which aligns with the responsibilities at Dropbox.
I have a proven track record of delivering high-quality products efficiently, and my hands-on experience with technologies like NodeJS and Electron further strengthens my suitability for this role. My portfolio, available at https://davidbethune.com, showcases my ability to create robust and user-friendly interfaces, ensuring that users enjoy a seamless experience across devices.
I am eager to bring my expertise in frontend development to Dropbox and help drive your product innovations forward. Thank you for considering my application. I look forward to the possibility of discussing how I can contribute to your team.
Sincerely,
David Bethune

Am I Hired?
What do you think of this result? Like anything that requires setup, this pays off when used for multiple job applications where I can just paste the next link and see what I get back. They’re all very likely to use this same formatting and writing style, thanks to my structured prompt.
I can also use this data again in a structured way, by asking for changes to a specific letter or asking for a list of companies and jobs I’ve applied to, for example.
The “Zero” in the title of this article refers to “zero-shot prompting” where no information is given about expected methods or results. The “hero” end of the spectrum is where you are now — with elaborate, structured prompts for your custom GPT applications.
Does this help you get started with a GPT of your own? I hope so!
I’d love to hear about your experiments with custom GPTs. Add your comments here or email me directly. You can find my contact info on my portfolio site at https://davidbethune.com.
As always, thanks for reading!
PS — As I was writing this story, the rejection letter came from Dropbox! [sigh]
Zero to Hero | Crafting a Custom GPT was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by David Bethune
David Bethune | Sciencx (2024-08-31T12:23:32+00:00) Zero to Hero | Crafting a Custom GPT. Retrieved from https://www.scien.cx/2024/08/31/zero-to-hero-crafting-a-custom-gpt/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.