
This content originally appeared on Level Up Coding - Medium and was authored by Javier Martín
Generative AI models can be sometimes… unpredictable. Who has never encountered with Chat-GPT hallucinating and generating some weird responses?
But what if there was something, a way, a method, to improve and enhance the accuracy and reliability of those models. That, my dear reader, is called Retrieval Augmented Generation, aka RAG.
Do not be scared because of the name, it is not that complicated. I was amazed when I learnt about this technique and the new possibilities it offered. Truly I tell you this would be the future of Generative AI.
But what is exactly RAG?
Following the formal definition of AWS, it is the process of improving the output of a LLM, so it can achieve better results given additional data outside the initial training data set. RAG is specially used when the model have some lack or scarcity of knowledge about a very specific topic (e.g. legal information).
Doing this process, not only the precision of the model will increase, but the data set can be updated in order to maintain a model with the latest information.
As far as you have read, RAG seems quite similar to Chat-GPT tuning with extra steps. Well, that’s because I have not talk about the autonomous agents yet.
The autonomous agents are that extra tool that complements the Text-Generative AI and take it to the next level. They are systems that can work independently, usually managed with AI, having the ability to interact with their pre-programmed tools in order to achieve their objective.
Note that autonomous agents are not an intrinsic characteristic of RAG, but a powerful complement for increasing the uses cases of AI.
Let’s use this example: Imagine an AI that can interact with the internet (natively), search everything about research articles and then upload a resume to a database. This are several autonomous agents working in a coordinated way (comparison with threads and mutex).
Awesome, I know. However, in this article we will focus on implementing a RAG model. We will talk more about autonomous agents in another one.
Very cool, but how can I implement this?
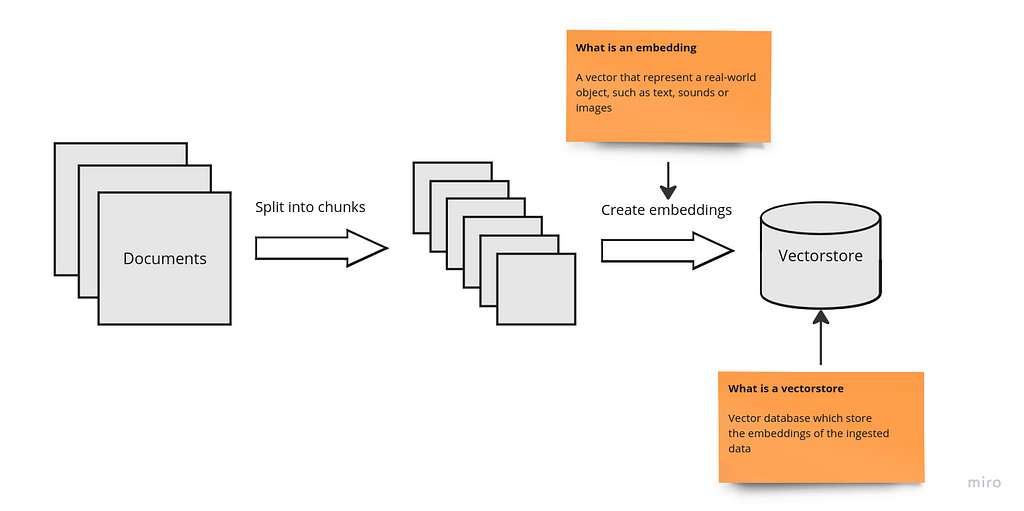
Firstly, you must understand how we must feed the documents (information) to our AI model. We all know that a .pdf is a big chunk of ASCII characters and bytes, right? Obviously, processing the entire document would be a tremendous (and expensive) amount of work.
But this has an easy solution! You just have to divide the document in some little chunks and give the model the ones you consider relevant.
Now we’re at the part everyone enjoys: converting to vectors. No technical jargon here — language models work with probabilities, picking the word most likely to come next in a sentence. We do something similar here.
After doing so, we obtain an embedding; a vector that represents an object of the real world. It’s like saving your image in a little tensor with a lot of matrices with incomprehensible numbers.
But do not worry about this, our model can understand what this vector means. But we must save it somewhere if we want to have a great data collection.
We must use a vector store.
I won’t be tricky here. Although the names seems cools, its just a database used for saving this vectors. You can find specialized databases such as Pinecone and Milvus or other more typical approaches with some extensions such as PosgreSQL.
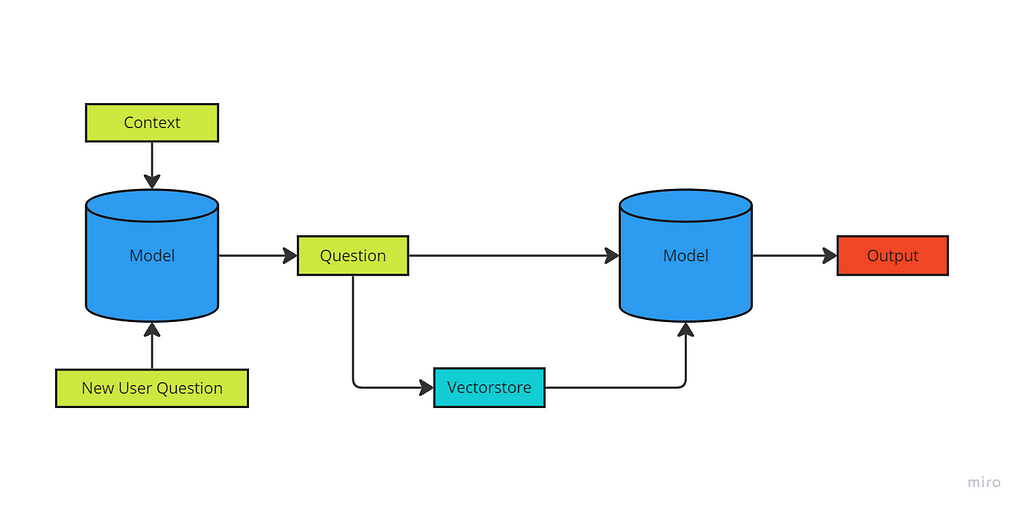
Now that we have our database ready, we should start implementing the logic of RAG. But how does RAG really work?
In this context, the model processes the new user query independently. However, it also has the ability to check if the query relates to our vector space, and if so, it can generate a response by leveraging both the main model and the vector database.
Essentially, it combines the capabilities of the primary model with the option to retrieve additional information from the vector store.
But the best part is that a RAG model may not be use solely the database. It might be capable of search external data through the internet — here is when the autonomous agent enters in scene. But remember that the output of that search must be previously tokenized in order to be saved in the vector database.
It wasn’t that hard, right?
To put in a nutshell, RAG is a powerful tool that, when used effectively, can significantly enhance AI capabilities. Whether you aim to develop an AI specialized in Discrete Mathematics or any other domain, the possibilities are limitless. By combining the strengths of a robust model with the targeted knowledge stored in a vector database, you can create tailored AI solutions that excel in specialized tasks.
Keep coding,
Javier Martín
Retrieval Augmented Generation: How to feed documents to your AI was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Javier Martín
Javier Martín | Sciencx (2024-09-04T09:52:28+00:00) Retrieval Augmented Generation: How to feed documents to your AI. Retrieved from https://www.scien.cx/2024/09/04/retrieval-augmented-generation-how-to-feed-documents-to-your-ai/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.