
This content originally appeared on HackerNoon and was authored by Jim
\
Preface: Applications and Challenges of RAG Technology
Hey, developers and AI enthusiasts! Today, I want to talk about RAG (Retrieval-Augmented Generation) technology. I believe this term is not unfamiliar to everyone, right? RAG has become an indispensable part of AI applications, especially in scenarios that require a large amount of precise information.
\ Before diving deeper, I would like to invite everyone to try out the “C# AI Buddy” I developed. This is a C# AI assistant that integrates over 800 pages of Microsoft Learn documentation. It can not only answer your C# related questions but also ==provide accurate document reference links==. Interested readers can experience it first to see how it utilizes the technology I will discuss today. The workflow will be revealed later in this article!
\
C# AI Buddy
👉 https://www.coze.com/s/Zs8k6Co9K/
\ Back to the main topic, although RAG technology is powerful, it also faces some challenges in practical applications. The first issue is the =="full-text indexing"== approach. When we directly index a large amount of text, we often find that the retrieval results are not precise enough. Imagine searching for specific information in a vast number of documents but never finding the most relevant one. Without the correct reference material, of course AI cannot provide the correct answers.
\ Another tricky problem is the limitation of chunk size. When dealing with long texts, we usually need to split them into smaller chunks for processing. However, ==the upper limit of chunk size often restricts our ability to retain the complete context==. As a result, we may miss important contextual information, leading to inaccurate understanding or hallucinations by the AI.
\ These challenges have prompted me to think:
Is there a better way to improve RAG technology, enhancing retrieval accuracy while retaining more valuable information within limited space?
\ Next, let's explore the "summary indexing and full-text reference" method to see how it addresses these challenges and brings new possibilities to RAG technology.
Summary Indexing and Full-Text Reference Method
When facing the challenges of RAG technology, I thought of an interesting approach: ==why not create a "condensed version" of the documents first, and then use this condensed version to locate?== This is the core idea of the "Summary Index and Full-text Reference Method."
\ In a list format, this method consists of several steps:
First, use AI to generate a concise summary for each document.
Link the summaries to the original documents.
Perform vector indexing on these summaries.
During a search, first find the relevant summaries, and then use the summaries to locate the complete original documents.
Finally, let AI answer questions based on the content of the complete documents.
\
It sounds a bit convoluted, but this process is actually quite similar to finding books in a library. You first look at the title and summary (abstract), and if it seems relevant, you then open the entire book (original document) to read.
Detailed Workflow
Let's take a step-by-step look at how this method works:
- Generate document summaries using LLM: Utilize the intelligent large language model (LLM) to generate a concise summary for each document. This summary should include the keywords and main points of the document.
- Associate summaries with original documents: Link each summary to the location of the original document (which could be a URL or file path). This way, we can quickly find the complete document through the summary.
- Vector indexing of summaries: Convert the summaries into vectors and create the index. The purpose of this step is to enable quick and efficient retrieval of relevant summaries, ensuring that the most relevant content can be found swiftly when a user poses a question.
- Retrieve and extract full text based on summaries: When a user poses a question, we first search the summary index for the most relevant content. After finding the relevant summaries, we can quickly locate and extract the complete original documents through the previously established associations. In practice, it is recommended to use Hybrid Search, as its results are always superior to using either full-text search or vector search alone.
- LLM answers questions using the full document content: Finally, we pass the user's question along with the extracted full documents to the intelligent LLM. LLM will generate an answer based on this complete contextual information, ensuring the accuracy of the information and avoiding AI hallucinations.
Technical Highlights
When implementing the "Summary Indexing and Full-text Reference Method," the quality of the summary generation is crucial. We need to ensure that the summary is not only concise but also contains all the keywords. This is because vector search is not semantic search but rather a comparison of the relevance between the user's query and the index. However, considering the needs of hybrid search, the summary cannot merely be a pile of keywords; it must also retain enough semantic meaning for the model to judge. Therefore, a good practice is to emphasize the two key points of =="a five-sentence summary"== and =="including all keywords"== when instructing LLM to generate the summary.
\
I specifically created a Coze bot to summarize a large number of web pages at once.
👉 https://www.coze.com/s/Zs8kjAdbH/
\ In terms of context management, we can fully utilize the large context window of LLM. For example, Claude 3.5 Sonnet has a context window of up to 200k tokens. In practical applications, we can use the following formula to calculate the length limit of each document:
(200k - Question Content - system prompt - Chat History) / Number of Reference Documents
Assuming the query, system prompt, and Chat History occupy a total of 8k tokens, and we intend to use 5 reference documents, then the length limit for each document is (200k - 8k) / 5 ≈ 38k tokens. This length is actually quite large and is generally sufficient to accommodate a complete book chapter or a full page of online webpages. When organizing data, the first step is to segment it according to reasonable context, and then ensure it falls within this length limit.
Method Advantage Analysis
==The "Summary Indexing and Full-text Reference Method" significantly improves retrieval accuracy.== Traditional full-text indexing methods often lead to imprecise retrieval results due to the complexity of document content and the uniformity of terminology. By using AI-generated summary as indexes, we can better capture the core content and keywords of documents, thereby improving the relevance of search results. This method is particularly suitable for handling long documents or literature in specialized fields, as it effectively extracts the most critical information, making the retrieval process more efficient and accurate.
\ ==This method also effectively addresses the challenge of chunk size limitations.== In traditional RAG implementations, we often need to split long texts into smaller chunks for indexing, which can lead to loss and truncation of contextual information. By using the "Summary Indexing and Full-text Reference Method," we can use concise summaries during the indexing phase while referencing the complete original document when answering questions. This not only preserves the full context of the reference documents but also fully utilizes the large context window of LLM, resulting in more comprehensive and accurate answers.
\ ==Fully utilizing the large context window of LLM is another important advantage of this method.== Modern LLM such as Claude 3.5 Sonnet have a context window of up to 200k tokens, which provides us with the ability to handle large amounts of text. Through carefully designed context management strategies, we can include multiple complete documents or long chapters in a single query, rather than relying solely on scattered text fragments. This greatly enhances the AI's ability to understand and synthesize information, making the generated answers more coherent and in-depth.
\ ==This method also significantly reduces the risk of AI-generated hallucinations.== When an AI model lacks sufficient contextual information, it may fill in knowledge gaps with fabricated content, leading to inaccurate or completely erroneous information. By providing the original document with complete context as a reference, we greatly mitigate this risk, allowing the AI to form responses based on reliable and comprehensive information rather than potentially incomplete or fragmented knowledge. This not only improves the accuracy of the responses but also enhances the credibility of the entire system.
\ Finally, ==this method offers excellent scalability and flexibility.== Whether dealing with a small collection of specialized literature or large-scale web content, the approach of summary indexing and full-text referencing can be well applied. By adjusting the strategy for generating summaries, the length of individual documents, and the method of extracting full texts, we can tailor the approach to different application scenarios and needs, applying the same set of concepts to various implementations. This adaptability allows the method to be effective in various AI-assisted information retrieval and question-answering systems.
\
Practical Application Cases
Theory remains theory; practice is the only criterion for testing truth. To verify the practical effectiveness of the summary indexing and full-text referencing method, I developed two specific applications: Batch Webpage Summary Assistant and C# AI Buddy.
Batch Webpage Summary Assistant
https://www.coze.com/s/Zs8k6x4DJ/
\ First up is the Batch Webpage Summary Assistant, an AI assistant developed on the Coze platform. As the name suggests, ==the main function of this assistant is to batch process a large number of web pages, generating concise yet comprehensive summaries for each page.== In developing this assistant, I particularly focused on two key points: "control of summary length" and "retention of keywords."
\ Why are these two points so important?
\ First, controlling the summary length ensures that our index remains concise and does not exceed the chunk length limit. I limited the summary length to about five sentences, which is sufficient to encapsulate the main content of the article without being overly lengthy. In practice, AI cannot fully adhere to the "length" requirement, but approximate compliance is acceptable.
\ Secondly, retaining keywords is crucial for improving the accuracy of vector searches. After all, vector search is not semantic search but is based on text similarity matching. By retaining keywords in the summary, we greatly enhance the precision of subsequent retrievals. Additionally, considering that hybrid search may involve secondary semantic judgment, the output cannot be merely a pile of keywords but needs to contain complete semantics. Therefore, it should be an output of "short sentences rich in keywords."
\ Using the Batch Webpage Summary Assistant is very simple. Just input multiple webpage URLs, and it will automatically fetch the content of these pages, generate summaries, and return a JSON output containing the URLs and summaries. In scenarios involving large amounts of webpage data, this tool greatly simplifies the process of building a knowledge base with indexed summaries.
\
C# AI Buddy

https://www.coze.com/s/Zs8k6skpT/
\ ==C# AI Buddy is an AI assistant designed specifically for C# developers.== It utilizes summary indexing and full-text reference methods, integrating over 800 pages of Microsoft Learn C# documentation using the Batch Webpage Summary Assistant.
\ First, ==classify the user's question to determine if it falls within the scope of the built-in knowledge base.== If the question involves third-party packages or is outside the knowledge base, the system will automatically switch to the Google Search process to ensure the most relevant information is provided.
\ Next, ==extract keywords from the user's question.== This step improves the accuracy of vector searches. Remember what our summaries contain? "Keywords." By having LLM extract keywords from the user's question — essentially summarizing the user's input, we can more accurately match the summary index. Once the summary is found, C# AI Buddy will ==instantly retrieve the full content of these webpages==, ensuring LLM receives the latest and most complete information.
\ Finally, call a super large context window LLM (here using Claude 3.5 Sonnet) ==to reference the full document content to answer the user's question and provide links to the reference URLs.== This not only increases the credibility of the answer but also offers users the opportunity for in-depth learning. Users can easily click these links to directly view the original documents, thereby verifying the answers and gaining more related knowledge.
\
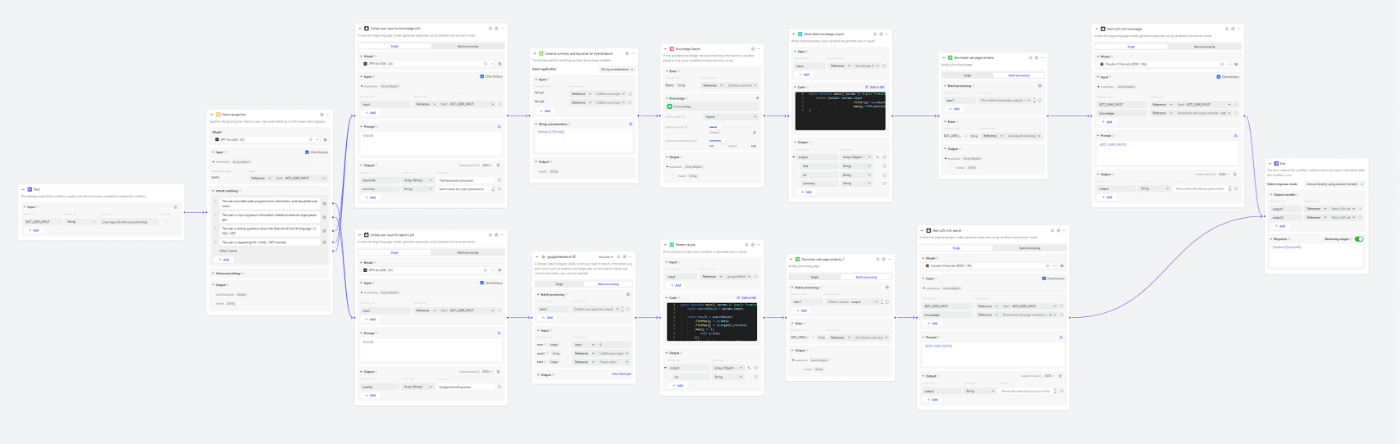
\ This meticulously designed process significantly improves the accuracy and relevance of the answers. Whether using the internal knowledge base or Google Search, C# AI Buddy can flexibly handle various C# related questions, providing accurate answers and official document resources, enhancing the user's learning efficiency and Q&A experience.
Summary: A new chapter in RAG technology balancing performance and cost.
After delving into the advantages of the "summary indexing and full-text reference method," we must also confront a significant drawback of this approach: ==the cost issue==. This method requires relying on LLM to summarize all documents during the preparation phase and using a super large context window LLM to process the complete document at the end. ==These two processes can significantly improve the accuracy of responses but also consume a large number of tokens, leading to a sharp increase in costs,== which could become a major obstacle for many projects.
\ However, the Coze platform offers an effective solution.
\ Allow me to briefly introduce Coze, a no-code, one-stop AI Bot development platform. Whether you have a programming background or not, you can quickly build various Q&A Bots based on AI models here. The platform's features are extensive, covering everything from simple Q&A to complex logical conversations. Additionally, Coze allows users to publish the built Bots to communication software such as LINE, Discord, and Telegram to interact with users, expanding the application scope of AI Bots.
\
Coze.com
Please refer to the official documentation for detailed pricing rules, as the official explanation shall prevail.
\ One major advantage of the Coze platform is its unique pricing model. In addition to the traditional token-based billing model, ==Coze also adopts a message-based pricing method.== This means that the cost of each message exchange between the user and the assistant is fixed and will not increase due to the use of more tokens on LLM. This allows us to confidently use the large context window of LLM, providing the complete document content to the AI assistant without worrying about runaway costs.
\ Overall, ==the "summary indexing and full-text reference method" provides a powerful and flexible framework for the application of RAG technology.== This method not only improves the accuracy of information retrieval but also overcomes many limitations of traditional RAG implementations. By generating precise summary indexes, we can more effectively capture the core content of documents while retaining the ability to reference the complete original document during the response phase. This method fully leverages the large context window of modern LLM, enabling the AI to generate responses based on more comprehensive information, significantly reducing the risk of generating hallucinations.
\ Despite the cost challenges, I believe that with technological advancements and the emergence of more innovative solutions, this method will play an increasingly important role in the future. Whether building knowledge Q&A systems in professional fields or developing large-scale information retrieval tools, the summary indexing and full-text reference method provides developers with a powerful tool to help create smarter and more accurate AI applications.
\
The original Chinese version of this article is published on my blog:
\
This content originally appeared on HackerNoon and was authored by Jim
Jim | Sciencx (2024-09-06T14:18:27+00:00) Say Goodbye to AI Hallucinations: A Simple Method to Improving the Accuracy of Your RAG System. Retrieved from https://www.scien.cx/2024/09/06/say-goodbye-to-ai-hallucinations-a-simple-method-to-improving-the-accuracy-of-your-rag-system/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.