
This content originally appeared on HackerNoon and was authored by Cosmological thinking: time, space and universal causation
:::info Authors:
(1) Zhan Ling, UC San Diego and equal contribution;
(2) Yunhao Fang, UC San Diego and equal contribution;
(3) Xuanlin Li, UC San Diego;
(4) Zhiao Huang, UC San Diego;
(5) Mingu Lee, Qualcomm AI Research and Qualcomm AI Research
(6) Roland Memisevic, Qualcomm AI Research;
(7) Hao Su, UC San Diego.
:::
Table of Links
Motivation and Problem Formulation
Deductively Verifiable Chain-of-Thought Reasoning
Conclusion, Acknowledgements and References
\ A Deductive Verification with Vicuna Models
C More Details on Answer Extraction
E More Deductive Verification Examples
A Deductive Verification with Vicuna Models
We further explore the efficacy of deductive verification for open-source models. We select two popular models: Vicuna-7B and Vicuna-13B [7]. These models are fine-tuned versions of LLaMA-7B and LLaMA-13B [47] using the ShareGPT data[3]. We use the same Natural Program-based one-shot verification method we used in the main paper. Results are shown in the first and the third rows of Table 9. We observe for the original Vicuna models without finetuning, Vicuna-7B exhibits poor performance in deductive verification and fails to find out reasoning mistakes, while the larger Vicuna-13B exhibits better verification accuracy.
\
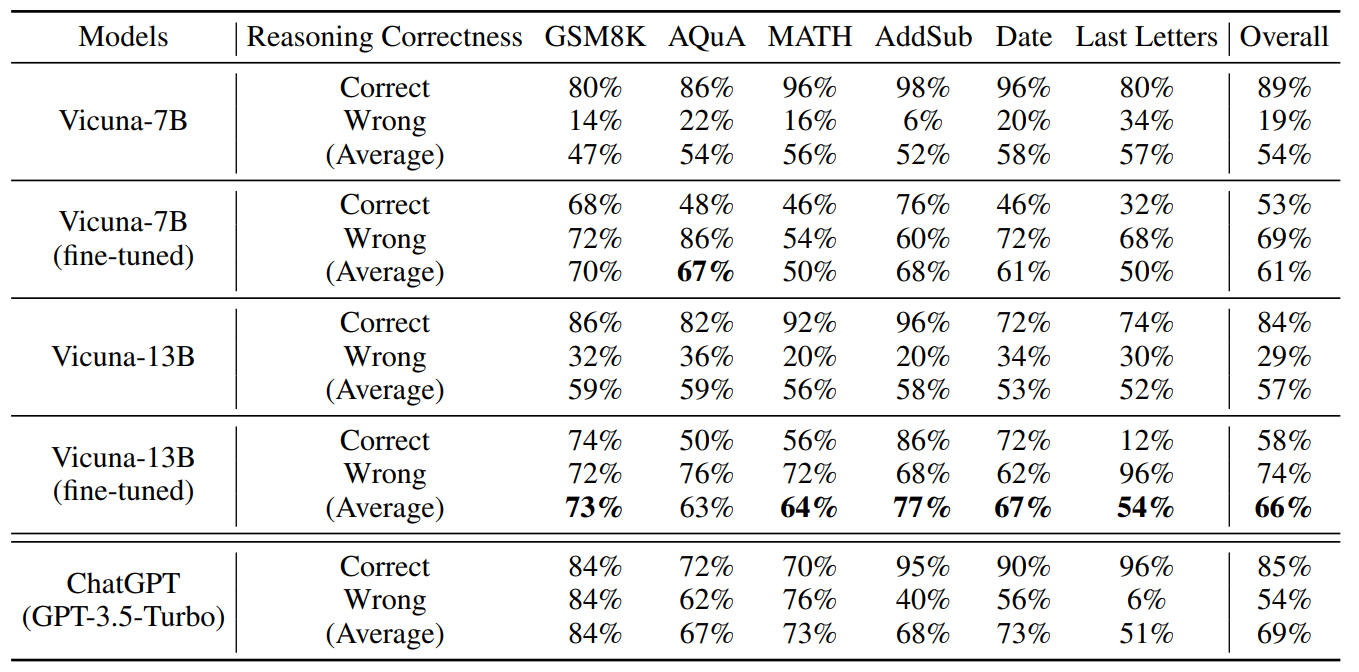
\ We therefore conduct an additional experiment to investigate if the verification accuracy of Vicuna models can be improved by fine-tuning. To this end, we generate a deductive verification dataset, which consists of 2000 reasoning steps evenly distributed between correct and incorrect categories. We automatically generate this dataset using GPT-3.5-turbo since it exhibits a very high accuracy of single-step verification. We first use GPT-3.5-turbo to generate solutions for problems in GSM8K’s training set. We then execute step-by-step deductive verification on these solutions using GPT-3.5- turbo. For solutions that result in correct final answers, we retain the reasoning steps that pass deductive verification. For solutions that yield incorrect final answers, we retain the reasoning steps that cannot pass deductive verification. After constructing our dataset, we then fine-tune the Vicuna models using the verifications of the 2000 reasoning steps. Models were fine-tuned with 4 A100-80GB over 3 epochs. Training parameters are shown in Table 10.
\ As shown in Tab. 9, we observe that fine-tuning with our dataset can enhance the deductive verification accuracy of Vicuna models not only on the dataset where the training dataset is constructed (GSM8K), but also on many other datasets. However, the accuracy is still worse than non-finetuned GPT-3.5, which suggests that model capacity has a significant impact on deductive verification capabilities.
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
[3] https://github.com/domeccleston/sharegpt
This content originally appeared on HackerNoon and was authored by Cosmological thinking: time, space and universal causation
Cosmological thinking: time, space and universal causation | Sciencx (2024-09-08T13:59:29+00:00) How Fine-Tuning Impacts Deductive Verification in Vicuna Models. Retrieved from https://www.scien.cx/2024/09/08/how-fine-tuning-impacts-deductive-verification-in-vicuna-models/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.