
This content originally appeared on HackerNoon and was authored by William Guo
\ Continuing from the previous article, Source Code Analysis of Apache SeaTunnel Zeta Engine (Part 1): Server Initialization
\
Task Submission on the Client Side
In this section, we will explain the task submission process in Apache SeaTunnel using the command-line interface (CLI).
To submit a task using the CLI, the command is:
./bin/seatunnel.sh -c <config_path>
When we check this script file, we see it ultimately calls the org.apache.seatunnel.core.starter.seatunnel.SeaTunnelClient class.
public class SeaTunnelClient {
public static void main(String[] args) throws CommandException {
ClientCommandArgs clientCommandArgs =
CommandLineUtils.parse(
args,
new ClientCommandArgs(),
EngineType.SEATUNNEL.getStarterShellName(),
true);
SeaTunnel.run(clientCommandArgs.buildCommand());
}
}
This class has only one main method. Similar to the server-side code mentioned earlier, it constructs ClientCommandArgs.
Command-Line Parameters
Let’s examine the clientCommandArgs.buildCommand method.
public Command<?> buildCommand() {
Common.setDeployMode(getDeployMode());
if (checkConfig) {
return new SeaTunnelConfValidateCommand(this);
}
if (encrypt) {
return new ConfEncryptCommand(this);
}
if (decrypt) {
return new ConfDecryptCommand(this);
}
return new ClientExecuteCommand(this);
}
Here, jcommander is used to parse the arguments. Depending on the user's input, it decides which class to construct—for example, whether to validate the configuration file, encrypt or decrypt a file, or submit a task as a client. We will not go into detail about the other classes here; instead, let's focus on ClientExecuteCommand.
The main code for this class is in the executemethod. Since the method is quite long, I will break it down into parts and explain each section.
Connecting to the Cluster
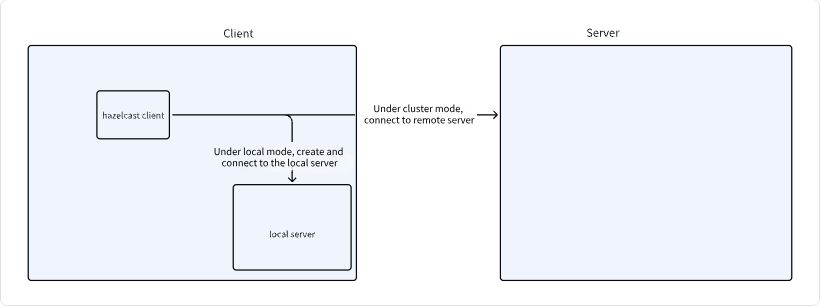
In this section of the code, the hazelcast-client.yaml file is read, and an attempt is made to establish a connection to the server. When using the local mode, a Hazelcast instance is created locally, and the client connects to it. When using the cluster mode, it connects directly to the cluster.
public void execute() throws CommandExecuteException {
JobMetricsRunner.JobMetricsSummary jobMetricsSummary = null;
LocalDateTime startTime = LocalDateTime.now();
LocalDateTime endTime = LocalDateTime.now();
SeaTunnelConfig seaTunnelConfig = ConfigProvider.locateAndGetSeaTunnelConfig();
try {
String clusterName = clientCommandArgs.getClusterName();
// Load configuration
ClientConfig clientConfig = ConfigProvider.locateAndGetClientConfig();
// Depending on the task type, if 'local' mode is used, the server-side process mentioned above has not been executed,
// so we create a local SeaTunnel server first.
if (clientCommandArgs.getMasterType().equals(MasterType.LOCAL)) {
clusterName =
creatRandomClusterName(
StringUtils.isNotEmpty(clusterName)
? clusterName
: Constant.DEFAULT_SEATUNNEL_CLUSTER_NAME);
instance = createServerInLocal(clusterName, seaTunnelConfig);
int port = instance.getCluster().getLocalMember().getSocketAddress().getPort();
clientConfig
.getNetworkConfig()
.setAddresses(Collections.singletonList("localhost:" + port));
}
// Connect to the remote or local SeaTunnel server and create an engineClient
if (StringUtils.isNotEmpty(clusterName)) {
seaTunnelConfig.getHazelcastConfig().setClusterName(clusterName);
clientConfig.setClusterName(clusterName);
}
engineClient = new SeaTunnelClient(clientConfig);
// Omitted second part of the code
// Omitted third part of the code
}
} catch (Exception e) {
throw new CommandExecuteException("SeaTunnel job executed failed", e);
} finally {
if (jobMetricsSummary != null) {
// When the job ends, print the log
log.info(
StringFormatUtils.formatTable(
"Job Statistic Information",
"Start Time",
DateTimeUtils.toString(
startTime, DateTimeUtils.Formatter.YYYY_MM_DD_HH_MM_SS),
"End Time",
DateTimeUtils.toString(
endTime, DateTimeUtils.Formatter.YYYY_MM_DD_HH_MM_SS),
"Total Time(s)",
Duration.between(startTime, endTime).getSeconds(),
"Total Read Count",
jobMetricsSummary.getSourceReadCount(),
"Total Write Count",
jobMetricsSummary.getSinkWriteCount(),
"Total Failed Count",
jobMetricsSummary.getSourceReadCount()
- jobMetricsSummary.getSinkWriteCount()));
}
closeClient();
}
}
The image below illustrates the process:
\
Determine the Task Type and Call Related Methods
The task type is determined based on the user’s parameters, and different methods are called accordingly.
For example, if the task is to cancel a job, the corresponding cancel task method is invoked. We won’t analyze each task type here; instead, we’ll focus on the task submission process. Once we understand the submission process, the rest will be easier to comprehend.
if (clientCommandArgs.isListJob()) {
String jobStatus = engineClient.getJobClient().listJobStatus(true);
System.out.println(jobStatus);
} else if (clientCommandArgs.isGetRunningJobMetrics()) {
String runningJobMetrics = engineClient.getJobClient().getRunningJobMetrics();
System.out.println(runningJobMetrics);
} else if (null != clientCommandArgs.getJobId()) {
String jobState =
engineClient
.getJobClient()
.getJobDetailStatus(Long.parseLong(clientCommandArgs.getJobId()));
System.out.println(jobState);
} else if (null != clientCommandArgs.getCancelJobId()) {
engineClient
.getJobClient()
.cancelJob(Long.parseLong(clientCommandArgs.getCancelJobId()));
} else if (null != clientCommandArgs.getMetricsJobId()) {
String jobMetrics =
engineClient
.getJobClient()
.getJobMetrics(Long.parseLong(clientCommandArgs.getMetricsJobId()));
System.out.println(jobMetrics);
} else if (null != clientCommandArgs.getSavePointJobId()) {
engineClient
.getJobClient()
.savePointJob(Long.parseLong(clientCommandArgs.getSavePointJobId()));
} else {
// Omitted third section of the code
}
Submit the Task to the Cluster
// Get the path of the configuration file and check if the file exists
Path configFile = FileUtils.getConfigPath(clientCommandArgs);
checkConfigExist(configFile);
JobConfig jobConfig = new JobConfig();
// Depending on whether the task is a restart from a savepoint or a new task, different methods are called to construct the ClientJobExecutionEnvironment object
ClientJobExecutionEnvironment jobExecutionEnv;
jobConfig.setName(clientCommandArgs.getJobName());
if (null != clientCommandArgs.getRestoreJobId()) {
jobExecutionEnv =
engineClient.restoreExecutionContext(
configFile.toString(),
clientCommandArgs.getVariables(),
jobConfig,
seaTunnelConfig,
Long.parseLong(clientCommandArgs.getRestoreJobId()));
} else {
jobExecutionEnv =
engineClient.createExecutionContext(
configFile.toString(),
clientCommandArgs.getVariables(),
jobConfig,
seaTunnelConfig,
clientCommandArgs.getCustomJobId() != null
? Long.parseLong(clientCommandArgs.getCustomJobId())
: null);
}
// Get job start time
startTime = LocalDateTime.now();
// Create job proxy
// Submit the task
ClientJobProxy clientJobProxy = jobExecutionEnv.execute();
// Check if it's an asynchronous submission; if so, exit directly without checking the status
if (clientCommandArgs.isAsync()) {
if (clientCommandArgs.getMasterType().equals(MasterType.LOCAL)) {
log.warn("The job is running in local mode, cannot use async mode.");
} else {
return;
}
}
// Register cancelJob hook
// Add a hook method to cancel the submitted job when the command line exits after the task is submitted
Runtime.getRuntime()
.addShutdownHook(
new Thread(
() -> {
CompletableFuture<Void> future =
CompletableFuture.runAsync(
() -> {
log.info(
"Running shutdown hook due to close signal");
shutdownHook(clientJobProxy);
});
try {
future.get(15, TimeUnit.SECONDS);
} catch (Exception e) {
log.error("Cancel job failed.", e);
}
}));
// Synchronous task status check related code
// Get the task ID and start a background thread to periodically check the task status
long jobId = clientJobProxy.getJobId();
JobMetricsRunner jobMetricsRunner = new JobMetricsRunner(engineClient, jobId);
// Create a thread to periodically check the status
executorService =
Executors.newSingleThreadScheduledExecutor(
new ThreadFactoryBuilder()
.setNameFormat("job-metrics-runner-%d")
.setDaemon(true)
.build());
executorService.scheduleAtFixedRate(
jobMetricsRunner,
0,
seaTunnelConfig.getEngineConfig().getPrintJobMetricsInfoInterval(),
TimeUnit.SECONDS);
// Wait for job completion
// Wait for the task to complete and check the status. If the task exits abnormally, throw an exception
JobResult jobResult = clientJobProxy.waitForJobCompleteV2();
jobStatus = jobResult.getStatus();
if (StringUtils.isNotEmpty(jobResult.getError())
|| jobResult.getStatus().equals(JobStatus.FAILED)) {
throw new SeaTunnelEngineException(jobResult.getError());
}
// Get job end time
endTime = LocalDateTime.now();
// Get job statistic information when the job is finished
jobMetricsSummary = engineClient.getJobMetricsSummary(jobId);
Next, let’s take a look at the initialization and the execute method of the jobExecutionEnv class.
public ClientJobExecutionEnvironment(
JobConfig jobConfig,
String jobFilePath,
List<String> variables,
SeaTunnelHazelcastClient seaTunnelHazelcastClient,
SeaTunnelConfig seaTunnelConfig,
boolean isStartWithSavePoint,
Long jobId) {
super(jobConfig, isStartWithSavePoint);
this.jobFilePath = jobFilePath;
this.variables = variables;
this.seaTunnelHazelcastClient = seaTunnelHazelcastClient;
this.jobClient = new JobClient(seaTunnelHazelcastClient);
this.seaTunnelConfig = seaTunnelConfig;
Long finalJobId;
if (isStartWithSavePoint || jobId != null) {
finalJobId = jobId;
} else {
finalJobId = jobClient.getNewJobId();
}
this.jobConfig.setJobContext(new JobContext(finalJobId));
this.connectorPackageClient = new ConnectorPackageClient(seaTunnelHazelcastClient);
}
The initialization of this class is straightforward, consisting mainly of variable assignments without any other initialization operations.
Next, let’s look at the execute method.
public ClientJobProxy execute() throws ExecutionException, InterruptedException {
LogicalDag logicalDag = getLogicalDag();
log.info(
"jarUrls are: [{}]",
jarUrls.stream().map(URL::getPath).collect(Collectors.joining(", ")));
JobImmutableInformation jobImmutableInformation =
new JobImmutableInformation(
Long.parseLong(jobConfig.getJobContext().getJobId()),
jobConfig.getName(),
isStartWithSavePoint,
seaTunnelHazelcastClient.getSerializationService().toData(logicalDag),
jobConfig,
new ArrayList<>(jarUrls),
new ArrayList<>(connectorJarIdentifiers));
return jobClient.createJobProxy(jobImmutableInformation);
}
In this method, getLogicalDag is first called to generate a logical plan. Then, JobImmutableInformation is constructed and passed to jobClient. We will look at the later steps first, and then examine how the logical plan is generated.
public ClientJobProxy createJobProxy(@NonNull JobImmutableInformation jobImmutableInformation) {
return new ClientJobProxy(hazelcastClient, jobImmutableInformation);
}
public ClientJobProxy(
@NonNull SeaTunnelHazelcastClient seaTunnelHazelcastClient,
@NonNull JobImmutableInformation jobImmutableInformation) {
this.seaTunnelHazelcastClient = seaTunnelHazelcastClient;
this.jobId = jobImmutableInformation.getJobId();
submitJob(jobImmutableInformation);
}
private void submitJob(JobImmutableInformation jobImmutableInformation) {
LOGGER.info(
String.format(
"Start submit job, job id: %s, with plugin jar %s",
jobImmutableInformation.getJobId(),
jobImmutableInformation.getPluginJarsUrls()));
ClientMessage request =
SeaTunnelSubmitJobCodec.encodeRequest(
jobImmutableInformation.getJobId(),
seaTunnelHazelcastClient
.getSerializationService()
.toData(jobImmutableInformation),
jobImmutableInformation.isStartWithSavePoint());
PassiveCompletableFuture<Void> submitJobFuture =
seaTunnelHazelcastClient.requestOnMasterAndGetCompletableFuture(request);
submitJobFuture.join();
LOGGER.info(
String.format(
"Submit job finished, job id: %s, job name: %s",
jobImmutableInformation.getJobId(), jobImmutableInformation.getJobName()));
}
In the provided code, after generating the JobImmutableInformation, this information is converted into a ClientMessage(SeaTunnelSubmitJobCodec) and then sent to the Master node, which is the master node in the Hazelcast server. After submission, the process returns to the task status detection steps mentioned above.
The message sending uses Hazelcast methods, and we don't need to focus on its implementation here.
The Logical Plan
The next chapter will revisit the server side to review the processing logic upon receiving the task submission from the client. For now, let’s go back and see how the logical plan is generated on the client side.
LogicalDag logicalDag = getLogicalDag();
First, let’s examine the structure of LogicalDag.
@Getter private JobConfig jobConfig;
private final Set<LogicalEdge> edges = new LinkedHashSet<>();
private final Map<Long, LogicalVertex> logicalVertexMap = new LinkedHashMap<>();
private IdGenerator idGenerator;
private boolean isStartWithSavePoint = false;
This class contains several variables, with two key classes: LogicalEdge and LogicalVertex, which are used to build the DAG through the relationships between tasks.
The LogicalEdge class contains simple variables, representing the connection between two points.
/** The input vertex connected to this edge. */
private LogicalVertex inputVertex;
/** The target vertex connected to this edge. */
private LogicalVertex targetVertex;
private Long inputVertexId;
private Long targetVertexId;
The LogicalVertex class has the following variables, including the current vertex ID, required parallelism, and the Action interface, which may be implemented by SourceAction, SinkAction, TransformAction, etc.
private Long vertexId;
private Action action;
/** Number of subtasks to split this task into at runtime. */
private int parallelism;
Now, let’s look at the getLogicalDag method.
public LogicalDag getLogicalDag() {
//
ImmutablePair<List<Action>, Set<URL>> immutablePair = getJobConfigParser().parse(null);
actions.addAll(immutablePair.getLeft());
// SeaTunnel has a feature where it doesn’t require all nodes on the server to have all dependencies.
// Instead, dependencies can be uploaded from the client to the server.
// The if-else block here handles this feature, determining whether to upload JAR packages from the client to the server,
// so the server doesn’t need to maintain all JAR packages.
boolean enableUploadConnectorJarPackage =
seaTunnelConfig.getEngineConfig().getConnectorJarStorageConfig().getEnable();
if (enableUploadConnectorJarPackage) {
Set<ConnectorJarIdentifier> commonJarIdentifiers =
connectorPackageClient.uploadCommonPluginJars(
Long.parseLong(jobConfig.getJobContext().getJobId()), commonPluginJars);
Set<URL> commonPluginJarUrls = getJarUrlsFromIdentifiers(commonJarIdentifiers);
Set<ConnectorJarIdentifier> pluginJarIdentifiers = new HashSet<>();
uploadActionPluginJar(actions, pluginJarIdentifiers);
Set<URL> connectorPluginJarUrls = getJarUrlsFromIdentifiers(pluginJarIdentifiers);
connectorJarIdentifiers.addAll(commonJarIdentifiers);
connectorJarIdentifiers.addAll(pluginJarIdentifiers);
jarUrls.addAll(commonPluginJarUrls);
jarUrls.addAll(connectorPluginJarUrls);
actions.forEach(
action -> {
addCommonPluginJarsToAction(
action, commonPluginJarUrls, commonJarIdentifiers);
});
} else {
jarUrls.addAll(commonPluginJars);
jarUrls.addAll(immutablePair.getRight());
actions.forEach(
action -> {
addCommonPluginJarsToAction(
action, new HashSet<>(commonPluginJars), Collections.emptySet());
});
}
return getLogicalDagGenerator().generate();
}
In this method, the .parse(null) method is first called. This method returns an immutable pair where the first value is a List<Action> object. The getJobConfigParser returns an object of type MultipleTableJobConfigParser.
public MultipleTableJobConfigParser(
Config seaTunnelJobConfig,
IdGenerator idGenerator,
JobConfig jobConfig,
List<URL> commonPluginJars,
boolean isStartWithSavePoint) {
this.idGenerator = idGenerator;
this.jobConfig = jobConfig;
this.commonPluginJars = commonPluginJars;
this.isStartWithSavePoint = isStartWithSavePoint;
this.seaTunnelJobConfig = seaTunnelJobConfig;
this.envOptions = ReadonlyConfig.fromConfig(seaTunnelJobConfig.getConfig("env"));
this.fallbackParser =
new JobConfigParser(idGenerator, commonPluginJars, this, isStartWithSavePoint);
}
When calling the parse(null) method, parsing occurs as follows:
public ImmutablePair<List<Action>, Set<URL>> parse(ClassLoaderService classLoaderService) {
// Add env.jars from the configuration file to commonJars
this.fillJobConfigAndCommonJars();
// Read and process source, transform, and sink configurations from the configuration file
List<? extends Config> sourceConfigs =
TypesafeConfigUtils.getConfigList(
seaTunnelJobConfig, "source", Collections.emptyList());
List<? extends Config> transformConfigs =
TypesafeConfigUtils.getConfigList(
seaTunnelJobConfig, "transform", Collections.emptyList());
List<? extends Config> sinkConfigs =
TypesafeConfigUtils.getConfigList(
seaTunnelJobConfig, "sink", Collections.emptyList());
// Get connector JAR paths
List<URL> connectorJars = getConnectorJarList(sourceConfigs, sinkConfigs);
if (!commonPluginJars.isEmpty()) {
// Add commonJars to connector JARs
connectorJars.addAll(commonPluginJars);
}
ClassLoader parentClassLoader = Thread.currentThread().getContextClassLoader();
ClassLoader classLoader;
if (classLoaderService == null) {
// Create a SeaTunnelChildFirstClassLoader since we passed null
classLoader = new SeaTunnelChildFirstClassLoader(connectorJars, parentClassLoader);
} else {
classLoader =
classLoaderService.getClassLoader(
Long.parseLong(jobConfig.getJobContext().getJobId()), connectorJars);
}
try {
Thread.currentThread().setContextClassLoader(classLoader);
// Check if the DAG contains cycles to avoid infinite loops during construction
ConfigParserUtil.checkGraph(sourceConfigs, transformConfigs, sinkConfigs);
LinkedHashMap<String, List<Tuple2<CatalogTable, Action>>> tableWithActionMap =
new LinkedHashMap<>();
log.info("start generating all sources.");
for (int configIndex = 0; configIndex < sourceConfigs.size(); configIndex++) {
Config sourceConfig = sourceConfigs.get(configIndex);
// The parseSource method generates the source
// The return value is a tuple where the first value is the table name
// and the second value is a list of tuples of CatalogTable and Action
Tuple2<String, List<Tuple2<CatalogTable, Action>>> tuple2 =
parseSource(configIndex, sourceConfig, classLoader);
tableWithActionMap.put(tuple2._1(), tuple2._2());
}
log.info("start generating all transforms.");
// parseTransforms generates transforms
// The tableWithActionMap is passed in, so no return value is needed
parseTransforms(transformConfigs, classLoader, tableWithActionMap);
log.info("start generating all sinks.");
List<Action> sinkActions = new ArrayList<>();
for (int configIndex = 0; configIndex < sinkConfigs.size(); configIndex++) {
Config sinkConfig = sinkConfigs.get(configIndex);
// The parseSink method generates the sink
// The tableWithActionMap is also passed in
sinkActions.addAll(
parseSink(configIndex, sinkConfig, classLoader, tableWithActionMap));
}
Set<URL> factoryUrls = getUsedFactoryUrls(sinkActions);
return new ImmutablePair<>(sinkActions, factoryUrls);
} finally {
// Restore the original class loader for the current thread
Thread.currentThread().setContextClassLoader(parentClassLoader);
if (classLoaderService != null) {
classLoaderService.releaseClassLoader(
Long.parseLong(jobConfig.getJobContext().getJobId()), connectorJars);
}
}
}
Source
Let’s take a look at the parseSource method:
public Tuple2<String, List<Tuple2<CatalogTable, Action>>> parseSource(
int configIndex, Config sourceConfig, ClassLoader classLoader) {
final ReadonlyConfig readonlyConfig = ReadonlyConfig.fromConfig(sourceConfig);
// factoryId is the source name in the configuration, e.g., FakeSource, Jdbc
final String factoryId = getFactoryId(readonlyConfig);
// Get the name of the table generated by the current data source
// Note that this table may not correspond to a single table
// Since SeaTunnel source supports reading multiple tables, this will be a one-to-many relationship
final String tableId =
readonlyConfig.getOptional(CommonOptions.RESULT_TABLE_NAME).orElse(DEFAULT_ID);
// Get parallelism
final int parallelism = getParallelism(readonlyConfig);
// Some sources do not yet support construction via Factory, so there are two construction methods
// When all connectors support factory creation,
this code will be removed, so it is ignored here
// The internal method checks if the corresponding factory class exists, returning true if not, false if it exists
boolean fallback =
isFallback(
classLoader,
TableSourceFactory.class,
factoryId,
(factory) -> factory.createSource(null));
if (fallback) {
Tuple2<CatalogTable, Action> tuple =
fallbackParser.parseSource(sourceConfig, jobConfig, tableId, parallelism);
return new Tuple2<>(tableId, Collections.singletonList(tuple));
}
// Create the Source using FactoryUtil
// The return value is a SeaTunnelSource instance and a List<CatalogTable>
// This creates the Source instance for the synchronization task, with the catalog table list representing the table structure of the source
Tuple2<SeaTunnelSource<Object, SourceSplit, Serializable>, List<CatalogTable>> tuple2 =
FactoryUtil.createAndPrepareSource(readonlyConfig, classLoader, factoryId);
// Get the JAR paths for the current source connector
Set<URL> factoryUrls = new HashSet<>();
factoryUrls.addAll(getSourcePluginJarPaths(sourceConfig));
List<Tuple2<CatalogTable, Action>> actions = new ArrayList<>();
long id = idGenerator.getNextId();
String actionName = JobConfigParser.createSourceActionName(configIndex, factoryId);
SeaTunnelSource<Object, SourceSplit, Serializable> source = tuple2._1();
source.setJobContext(jobConfig.getJobContext());
PluginUtil.ensureJobModeMatch(jobConfig.getJobContext(), source);
// Build SourceAction
SourceAction<Object, SourceSplit, Serializable> action =
new SourceAction<>(id, actionName, tuple2._1(), factoryUrls, new HashSet<>());
action.setParallelism(parallelism);
for (CatalogTable catalogTable : tuple2._2()) {
actions.add(new Tuple2<>(catalogTable, action));
}
return new Tuple2<>(tableId, actions);
}
In the new version, the Source instance is created through a factory:
public static <T, SplitT extends SourceSplit, StateT extends Serializable>
Tuple2<SeaTunnelSource<T, SplitT, StateT>, List<CatalogTable>> createAndPrepareSource(
ReadonlyConfig options, ClassLoader classLoader, String factoryIdentifier) {
try {
// Load the TableSourceFactory class via SPI and find the corresponding class by factoryIdentifier
final TableSourceFactory factory =
discoverFactory(classLoader, TableSourceFactory.class, factoryIdentifier);
// Create the Source instance using the factory
// The Source class initialization happens once on the client side. Ensure the environment can connect to the Source
SeaTunnelSource<T, SplitT, StateT> source =
createAndPrepareSource(factory, options, classLoader);
List<CatalogTable> catalogTables;
try {
// Retrieve the list of tables produced by the source, including fields, data types, partition info, etc.
catalogTables = source.getProducedCatalogTables();
} catch (UnsupportedOperationException e) {
// For backward compatibility with connectors not implementing getProducedCatalogTables
// Call the older method to get the data type and convert it to Catalog
SeaTunnelDataType<T> seaTunnelDataType = source.getProducedType();
final String tableId =
options.getOptional(CommonOptions.RESULT_TABLE_NAME).orElse(DEFAULT_ID);
catalogTables =
CatalogTableUtil.convertDataTypeToCatalogTables(seaTunnelDataType, tableId);
}
LOG.info(
"get the CatalogTable from source {}: {}",
source.getPluginName(),
catalogTables.stream()
.map(CatalogTable::getTableId)
.map(TableIdentifier::toString)
.collect(Collectors.joining(",")));
// If the parameter is set to SHARDING, only take the first table structure
// This parameter is not documented and its purpose is unclear
if (options.get(SourceOptions.DAG_PARSING_MODE) == ParsingMode.SHARDING) {
CatalogTable catalogTable = catalogTables.get(0);
catalogTables.clear();
catalogTables.add(catalogTable);
}
return new Tuple2<>(source, catalogTables);
} catch (Throwable t) {
throw new FactoryException(
String.format(
"Unable to create a source for identifier '%s'.", factoryIdentifier),
t);
}
}
private static <T, SplitT extends SourceSplit, StateT extends Serializable>
SeaTunnelSource<T, SplitT, StateT> createAndPrepareSource(
TableSourceFactory factory, ReadonlyConfig options, ClassLoader classLoader) {
// Create Source via TableSourceFactory
TableSourceFactoryContext context = new TableSourceFactoryContext(options, classLoader);
ConfigValidator.of(context.getOptions()).validate(factory.optionRule());
TableSource<T, SplitT, StateT> tableSource = factory.createSource(context);
return tableSource.createSource();
}
On the client side, the Source instance is created using SPI to load the Source’s Factory, ensuring that the client can also connect to the Source/Sink to avoid network issues.
Transforms
Next, let’s look at how transforms are created:
public void parseTransforms(
List<? extends Config> transformConfigs,
ClassLoader classLoader,
LinkedHashMap<String, List<Tuple2<CatalogTable, Action>>> tableWithActionMap) {
if (CollectionUtils.isEmpty(transformConfigs) || transformConfigs.isEmpty()) {
return;
}
Queue<Config> configList = new LinkedList<>(transformConfigs);
int index = 0;
while (!configList.isEmpty()) {
parseTransform(index++, configList, classLoader, tableWithActionMap);
}
}
private void parseTransform(
int index,
Queue<Config> transforms,
ClassLoader classLoader,
LinkedHashMap<String, List<Tuple2<CatalogTable, Action>>> tableWithActionMap) {
Config config = transforms.poll();
final ReadonlyConfig readonlyConfig = ReadonlyConfig.fromConfig(config);
final String factoryId = getFactoryId(readonlyConfig);
// get jar urls
Set<URL> jarUrls = new HashSet<>();
jarUrls.addAll(getTransformPluginJarPaths(config));
final List<String> inputIds = getInputIds(readonlyConfig);
// inputIds are source_table_name, find the upstream sources based on this value
// Currently, Transform does not support processing multiple tables, so an exception will be thrown if multiple upstream tables are found
List<Tuple2<CatalogTable, Action>> inputs =
inputIds.stream()
.map(tableWithActionMap::get)
.filter(Objects::nonNull)
.peek(
input -> {
if (input.size() > 1) {
throw new JobDefineCheckException(
"Adding transform to multi-table source is not supported.");
}
})
.flatMap(Collection::stream)
.collect(Collectors.toList());
// If inputs are empty, it indicates that no upstream nodes were found for the current Transform node
// There are a few cases here
if (inputs.isEmpty()) {
if (transforms.isEmpty()) {
// No source_table_name set, and results do not match the previous ones, with only one transform
// Use the last source as the upstream table for this transform
inputs = findLast(tableWithActionMap);
} else {
// The dependent transform may not have been created yet, so reinsert this transform into the queue for later parsing
transforms.offer(config);
return;
}
}
// Name of the table produced by this transform
final String tableId =
readonlyConfig.getOptional(CommonOptions.RESULT_TABLE_NAME).orElse(DEFAULT_ID);
// Get the Action of the upstream sources
Set<Action> inputActions =
inputs.stream()
.map(Tuple2::_2)
.collect(Collectors.toCollection(LinkedHashSet::new));
// Check if the tables produced by the multiple upstreams are of the same structure
checkProducedTypeEquals(inputActions);
// Set parallelism
int spareParallelism = inputs.get(0)._2().getParallelism();
int parallelism =
readonlyConfig.getOptional(CommonOptions.PARALLELISM).orElse(spareParallelism);
// Create Transform instance, similar behavior as creating Source
CatalogTable catalogTable = inputs.get(0)._1();
SeaTunnelTransform<?> transform =
FactoryUtil.createAndPrepareTransform(
catalogTable, readonlyConfig, classLoader, factoryId);
transform.setJobContext(jobConfig.getJobContext());
long id = idGenerator.getNextId();
String actionName = JobConfigParser.createTransformActionName(index, factoryId);
// Encapsulate as Action
TransformAction transformAction =
new TransformAction(
id,
actionName,
new ArrayList<>(inputActions),
transform,
jarUrls,
new HashSet<>());
transformAction.setParallelism(parallelism);
// Put into map, now the map stores sources and transforms
// With each node's produced table structure as the key, and action as the value
tableWithActionMap.put(
tableId,
Collections.singletonList(
new Tuple2<>(transform.getProducedCatalogTable(), transformAction)));
}
Sink
After reviewing the logic for sources and transforms, the logic if sinks is quite straightforward:
public List<SinkAction<?, ?, ?, ?>> parseSink(
int configIndex,
Config sinkConfig,
ClassLoader classLoader,
LinkedHashMap<String, List<Tuple2<CatalogTable, Action>>> tableWithActionMap) {
ReadonlyConfig readonlyConfig = ReadonlyConfig.fromConfig(sinkConfig);
//
String factoryId = getFactoryId(readonlyConfig);
// Get the upstream nodes that the current sink node depends on
List<String> inputIds = getInputIds(readonlyConfig);
// Find in tableWithActionMap
List<List<Tuple2<CatalogTable, Action>>> inputVertices =
inputIds.stream()
.map(tableWithActionMap::get)
.filter(Objects::nonNull)
.collect(Collectors.toList());
// If the sink node cannot find upstream nodes, find the last node's information as the upstream node
// Unlike transforms, sink nodes do not wait for other sink nodes to initialize because sinks cannot depend on other sink nodes
if (inputVertices.isEmpty()) {
// Tolerates incorrect configuration of simple graph
inputVertices = Collections.singletonList(findLast(tableWithActionMap));
} else if (inputVertices.size() > 1) {
for (List<Tuple2<CatalogTable, Action>> inputVertex : inputVertices) {
if (inputVertex.size() > 1) {
// If a sink node has multiple upstream nodes and some upstream nodes produce multiple tables, an exception is thrown
// Sink supports multiple data sources or multiple tables under a single data source, but not both at the same time
throw new JobDefineCheckException(
"Sink doesn't support simultaneous writing of data from multi-table sources and other sources.");
}
}
}
// For compatibility with older code
boolean fallback =
isFallback(
classLoader,
TableSinkFactory.class,
factoryId,
(factory) -> factory.createSink(null));
if (fallback) {
return fallbackParser.parseSinks(configIndex, inputVertices, sinkConfig, jobConfig);
}
// Get the sink connector jar files
Set<URL> jarUrls = new HashSet<>();
jarUrls.addAll(getSinkPluginJarPaths(sinkConfig));
List<SinkAction<?, ?, ?, ?>> sinkActions = new ArrayList<>();
// Multiple data sources case
if (inputVertices.size() > 1) {
Set<Action> inputActions =
inputVertices.stream()
.flatMap(Collection::stream)
.map(Tuple2::_2)
.collect(Collectors.toCollection(LinkedHashSet::new));
// Check if the table structures produced by multiple upstream data sources are consistent
checkProducedTypeEquals(inputActions);
// Create sinkAction
Tuple2<CatalogTable, Action> inputActionSample = inputVertices.get(0).get(0);
SinkAction<?, ?, ?, ?> sinkAction =
createSinkAction(
inputActionSample._1(),
inputActions,
readonlyConfig,
classLoader,
jarUrls,
new HashSet<>(),
factoryId,
inputActionSample._2().getParallelism(),
configIndex);
sinkActions.add(sinkAction);
return sinkActions;
}
// At this point, there is only one data source, and there may be multiple tables under this data source, creating sinkActions in a loop
for (Tuple2<CatalogTable, Action> tuple : inputVertices.get(0)) {
SinkAction<?, ?, ?, ?> sinkAction =
createSinkAction(
tuple._1(),
Collections.singleton(tuple._2()),
readonlyConfig,
classLoader,
jarUrls,
new HashSet<>(),
factoryId,
tuple._2().getParallelism(),
configIndex);
sinkActions.add(sinkAction);
}
// When multiple tables are under a single data source, this extra step is taken
// The above createSinkAction is consistent
// This method will check if the sink supports multiple tables, and
Optional<SinkAction<?, ?, ?, ?>> multiTableSink =
tryGenerateMultiTableSink(
sinkActions, readonlyConfig, classLoader, factoryId, configIndex);
// Finally, return the created sink actions
return multiTableSink
.<List<SinkAction<?, ?, ?, ?>>>map(Collections::singletonList)
.orElse(sinkActions);
}
Next, let’s look at the createSinkActionmethod:
private SinkAction<?, ?, ?, ?> createSinkAction(
CatalogTable catalogTable,
Set<Action> inputActions,
ReadonlyConfig readonlyConfig,
ClassLoader classLoader,
Set<URL> factoryUrls,
Set<ConnectorJarIdentifier> connectorJarIdentifiers,
String factoryId,
int parallelism,
int configIndex) {
// Create sink using the factory class
SeaTunnelSink<?, ?, ?, ?> sink =
FactoryUtil.createAndPrepareSink(
catalogTable, readonlyConfig, classLoader, factoryId);
sink.setJobContext(jobConfig.getJobContext());
SinkConfig actionConfig =
new SinkConfig(catalogTable.getTableId().toTablePath().toString());
long id = idGenerator.getNextId();
String actionName =
JobConfigParser.createSinkActionName(
configIndex, factoryId, actionConfig.getMultipleRowTableId());
// Create sinkAction
SinkAction<?, ?,
?, ?> sinkAction =
new SinkAction<>(
id,
actionName,
new ArrayList<>(inputActions),
sink,
factoryUrls,
connectorJarIdentifiers);
sinkAction.setParallelism(parallelism);
return sinkAction;
}
public void handleSaveMode(SeaTunnelSink<?, ?, ?, ?> sink) {
// When the sink class supports save mode features, save mode handling is performed
// For example: deleting a table, recreating a table, reporting errors, etc.
if (SupportSaveMode.class.isAssignableFrom(sink.getClass())) {
SupportSaveMode saveModeSink = (SupportSaveMode) sink;
// When save mode is set to execute on the client side, these actions will be performed on the client side
// We previously encountered an error where the task, after completion on the client side, encountered issues when reaching the cluster,
// getting stuck in the scheduling state, resulting in data being cleared without timely writing
// Additionally, be aware that the machine executing this on the client side needs to have network connectivity to the sink cluster;
// it is recommended to perform this action on the server side instead
if (envOptions
.get(EnvCommonOptions.SAVEMODE_EXECUTE_LOCATION)
.equals(SaveModeExecuteLocation.CLIENT)) {
log.warn(
"SaveMode execute location on CLIENT is deprecated, please use CLUSTER instead.");
Optional<SaveModeHandler> saveModeHandler = saveModeSink.getSaveModeHandler();
if (saveModeHandler.isPresent()) {
try (SaveModeHandler handler = saveModeHandler.get()) {
new SaveModeExecuteWrapper(handler).execute();
} catch (Exception e) {
throw new SeaTunnelRuntimeException(HANDLE_SAVE_MODE_FAILED, e);
}
}
}
}
}
Having reviewed the Source/Transform/Sink logic, let’s return to where the logic is invoked.
List<Action> sinkActions = new ArrayList<>();
for (int configIndex = 0; configIndex < sinkConfigs.size(); configIndex++) {
Config sinkConfig = sinkConfigs.get(configIndex);
// parseSink method generates sink actions
// It also passes the tableWithActionMap
sinkActions.addAll(
parseSink(configIndex, sinkConfig, classLoader, tableWithActionMap));
}
Set<URL> factoryUrls = getUsedFactoryUrls(sinkActions);
return new ImmutablePair<>(sinkActions, factoryUrls);
The parseSink method returns all created Sink Actions, and each Action maintains upstream Actions. Therefore, we can find related Transform Actions and Source Actions through the final Sink Action.
Ultimately, getUsedFactoryUrls identifies all dependent JARs in this chain and returns a pair of results.
The Logical Plan
Next, let’s look at how the logical plan is generated.
public LogicalDag getLogicalDag() {
// Initialize with all SinkActions we generated
ImmutablePair<List<Action>, Set<URL>> immutablePair = getJobConfigParser().parse(null);
actions.addAll(immutablePair.getLeft());
....
return getLogicalDagGenerator().generate();
}
Having reviewed how to configure the parameters, let’s now see how the logical plan is generated:
// Initialize with all SinkAction we generated
protected LogicalDagGenerator getLogicalDagGenerator() {
return new LogicalDagGenerator(actions, jobConfig, idGenerator, isStartWithSavePoint);
}
public LogicalDag generate() {
// Generate node information based on actions
actions.forEach(this::createLogicalVertex);
// Create edges
Set<LogicalEdge> logicalEdges = createLogicalEdges();
// Build LogicalDag object and set parsed values to appropriate attributes
LogicalDag logicalDag = new LogicalDag(jobConfig, idGenerator);
logicalDag.getEdges().addAll(logicalEdges);
logicalDag.getLogicalVertexMap().putAll(logicalVertexMap);
logicalDag.setStartWithSavePoint(isStartWithSavePoint);
return logicalDag;
}
Creating Logical Plan Nodes:
private void createLogicalVertex(Action action) {
// Get the ID of the current action, and return if it already exists in the map
final Long logicalVertexId = action.getId();
if (logicalVertexMap.containsKey(logicalVertexId)) {
return;
}
// Loop through upstream dependencies and create them
// The storage structure of the map is as follows:
// The current node's ID is the key
// The value is a list storing the IDs of downstream nodes that use this node
action.getUpstream()
.forEach(
inputAction -> {
createLogicalVertex(inputAction);
inputVerticesMap
.computeIfAbsent(
inputAction.getId(), id -> new LinkedHashSet<>())
.add(logicalVertexId);
});
// Finally, create information for the current node
final LogicalVertex logicalVertex =
new LogicalVertex(logicalVertexId, action, action.getParallelism());
// Note that there are two maps here
// One is inputVerticesMap and the other is logicalVertexMap
// inputVerticesMap stores the relationships between nodes
// logicalVertexMap stores the relationship between node IDs and nodes
logicalVertexMap.put(logicalVertexId, logicalVertex);
}
private Set<LogicalEdge> createLogicalEdges() {
// Use the two maps created above to create edges
return inputVerticesMap.entrySet().stream()
.map(
entry ->
entry.getValue().stream()
.map(
targetId ->
new LogicalEdge(
logicalVertexMap.get(
entry.getKey()),
logicalVertexMap.get(targetId)))
.collect(Collectors.toList()))
.flatMap(Collection::stream)
.collect(Collectors.toCollection(LinkedHashSet::new));
}
\
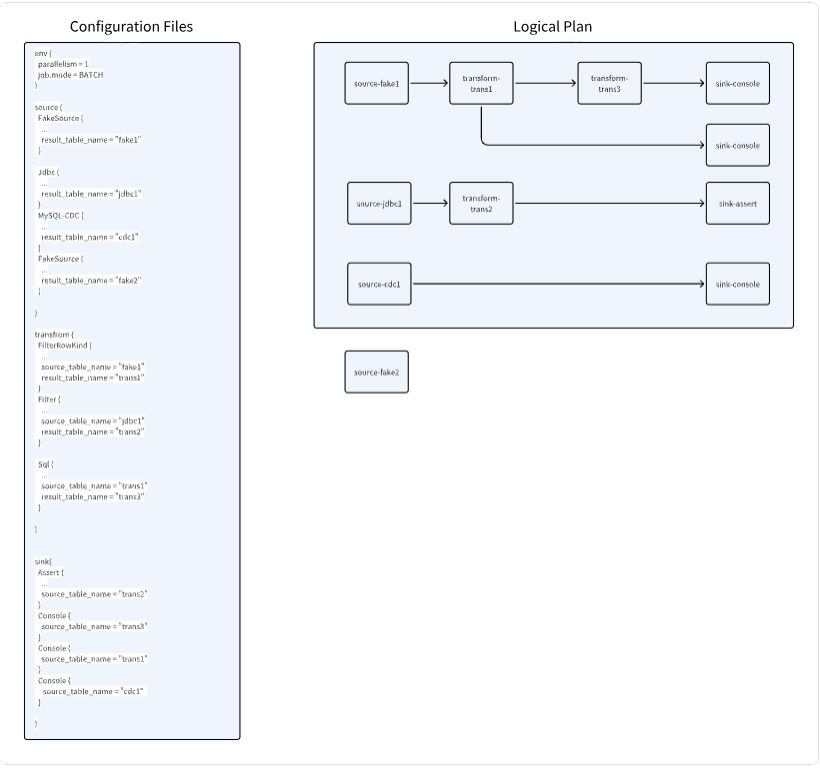
\ In the above configuration, the logical plan graph is generated based on upstream and downstream relationships. Nodes like Fake2, which have no downstream tasks, are excluded from the logical plan.
Summary
We have now reviewed the task submission process on the client side.
Here’s a summary:
- Execution Mode Determination: First, the execution mode is determined. In Local mode, a Server node is created on the local machine.
- Hazelcast Connection: A
Hazelcastnode is created on the current node, connecting either to the Hazelcast cluster or the locally started node. - Task Type Evaluation: The type of task being executed is determined, and different methods are called accordingly.
- For task submission, for example, the configuration file is parsed and the logical plan is generated. During logical plan generation,
Source/Transform/Sinkinstances are created on the submitting machine.SaveModefunctions may also be executed, such as creating tables, rebuilding tables, or deleting data (when client-side execution is enabled). - Logical Plan Encoding and Communication: Once the logical plan is parsed, the information is encoded and sent to the
Server'sMasternode using Hazelcast’s cluster communication functionality. - Task Status Checking: After sending, based on the configuration, the program decides whether to exit or continue monitoring the task status.
- Add Hook Configuration: A Hook configuration is added to cancel the submitted task when the client exits.
That’s all about this article!
\
This content originally appeared on HackerNoon and was authored by William Guo
William Guo | Sciencx (2024-09-12T20:30:24+00:00) Source Code Analysis of Apache SeaTunnel Zeta Engine (Part 2): Task Submission Process on the Client Side. Retrieved from https://www.scien.cx/2024/09/12/source-code-analysis-of-apache-seatunnel-zeta-engine-part-2-task-submission-process-on-the-client-side-2/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.