
This content originally appeared on HackerNoon and was authored by Knapsack
:::info Authors:
(1) Suriya Gunasekar, Microsoft Research;
(2) Yi Zhang, Microsoft Research;
(3) Jyoti Aneja, Microsoft Research;
(4) Caio C´esar Teodoro Mendes, Microsoft Research;
(5) Allie Del Giorno, Microsoft Research;
(6) Sivakanth Gopi, Microsoft Research;
(7) Mojan Javaheripi, Microsoft Research;
(8) Piero Kauffmann, Microsoft Research;
(9) Gustavo de Rosa, Microsoft Research;
(10) Olli Saarikivi, Microsoft Research;
(11) Adil Salim, Microsoft Research;
(12) Shital Shah, Microsoft Research;
(13) Harkirat Singh Behl, Microsoft Research;
(14) Xin Wang, Microsoft Research;
(15) S´ebastien Bubeck, Microsoft Research;
(16) Ronen Eldan, Microsoft Research;
(17) Adam Tauman Kalai, Microsoft Research;
(18) Yin Tat Lee, Microsoft Research;
(19) Yuanzhi Li, Microsoft Research.
:::
Table of Links
- Abstract and 1. Introduction
- 2 Training details and the importance of high-quality data
- 2.1 Filtering of existing code datasets using a transformer-based classifier
- 2.2 Creation of synthetic textbook-quality datasets
- 2.3 Model architecture and training
- 3 Spikes of model capability after finetuning on CodeExercises, 3.1 Finetuning improves the model’s understanding, and 3.2 Finetuning improves the model’s ability to use external libraries
- 4 Evaluation on unconventional problems with LLM grading
- 5 Data pruning for unbiased performance evaluation
- 5.1 N-gram overlap and 5.2 Embedding and syntax-based similarity analysis
- 6 Conclusion and References
- A Additional examples for Section 3
- B Limitation of phi-1
- C Examples for Section 5
4 Evaluation on unconventional problems with LLM grading
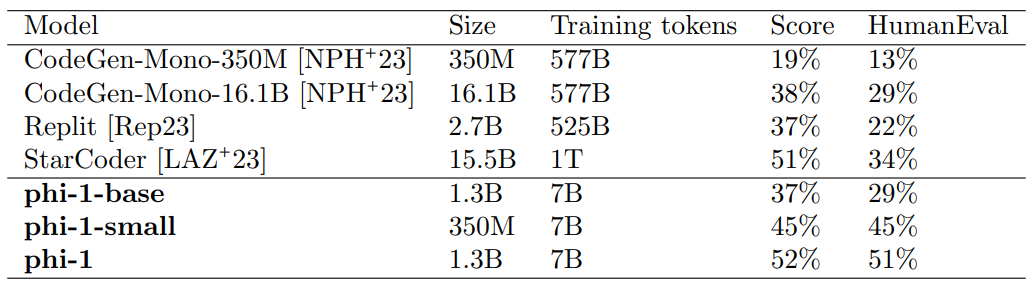
A potential concern with the surprisingly good performance of phi-1 on HumanEval (see Table 1 and Figure 2.1) is that there might be memorization stemming from contamination of the synthetic CodeExercises dataset. We study this potential contamination directly in Section 5, while this section addresses the concern with a new evaluation that is designed to be unconventional enough to be unlikely to appear in our training dataset.
\ To minimize bias and leakage, the new evaluation problems were created by a dedicated team that did not access the CodeExercises dataset or the final model. They created 50 new problems in the same format as HumanEval with instructions to design problems that are unlikely to appear in real-world code bases or as coding exercises. Here is an example of such a problem:
\

\ One of the challenges of evaluating language models on coding tasks is that the output of the model is often binary: either the code passes all the unit tests or it fails. However, this does not capture the nuances of the model’s performance, as it might have produced a code that is almost correct but has a minor error, or a code that is completely wrong but coincidentally passes some tests. Arguably, a more informative way of assessing the model’s coding skills is to compare its output with the correct solution and grade it based on how well it matches the expected logic. This is similar to how humans are evaluated on coding interviews, where the interviewer does not only run the code but also examines the reasoning and the quality of the solution.
\ To evaluate candidate solutions, we therefore adopt the approach of using GPT-4 to grade the solution (such as in [EL23]). This approach has two distinct advantages: (1) by using GPT-4 as a grader, we can leverage its knowledge and generative abilities to obtain a more fine-grained and meaningful signal of the
\
\ student model’s coding capabilities, and (2) it obviates the need for tests[1]. Our prompt instructs the LLM to evaluate a student’s solution first in a short verbal evaluation followed by grades from 0 to 10.
\ See Table 2 for our results with phi-1 and competing models. The grades on our new unconventional problems give the same ranking as HumanEval (see Table 1). phi-1 again achieves a score significantly higher than StarCoder, as it did on HumanEval. Given that the new problems have had no chance to contaminate the training data and, furthermore, were designed to be outside the training distribution, these results greatly increase our confidence in the validity of phi-1’s performance.
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\
This content originally appeared on HackerNoon and was authored by Knapsack
Knapsack | Sciencx (2024-09-12T11:30:16+00:00) Textbooks are All You Need: Evaluation on Unconventional Problems With LLM Grading. Retrieved from https://www.scien.cx/2024/09/12/textbooks-are-all-you-need-evaluation-on-unconventional-problems-with-llm-grading/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.