
This content originally appeared on HackerNoon and was authored by Knapsack
:::info Authors:
(1) Suriya Gunasekar, Microsoft Research;
(2) Yi Zhang, Microsoft Research;
(3) Jyoti Aneja, Microsoft Research;
(4) Caio C´esar Teodoro Mendes, Microsoft Research;
(5) Allie Del Giorno, Microsoft Research;
(6) Sivakanth Gopi, Microsoft Research;
(7) Mojan Javaheripi, Microsoft Research;
(8) Piero Kauffmann, Microsoft Research;
(9) Gustavo de Rosa, Microsoft Research;
(10) Olli Saarikivi, Microsoft Research;
(11) Adil Salim, Microsoft Research;
(12) Shital Shah, Microsoft Research;
(13) Harkirat Singh Behl, Microsoft Research;
(14) Xin Wang, Microsoft Research;
(15) S´ebastien Bubeck, Microsoft Research;
(16) Ronen Eldan, Microsoft Research;
(17) Adam Tauman Kalai, Microsoft Research;
(18) Yin Tat Lee, Microsoft Research;
(19) Yuanzhi Li, Microsoft Research.
:::
Table of Links
- Abstract and 1. Introduction
- 2 Training details and the importance of high-quality data
- 2.1 Filtering of existing code datasets using a transformer-based classifier
- 2.2 Creation of synthetic textbook-quality datasets
- 2.3 Model architecture and training
- 3 Spikes of model capability after finetuning on CodeExercises, 3.1 Finetuning improves the model’s understanding, and 3.2 Finetuning improves the model’s ability to use external libraries
- 4 Evaluation on unconventional problems with LLM grading
- 5 Data pruning for unbiased performance evaluation
- 5.1 N-gram overlap and 5.2 Embedding and syntax-based similarity analysis
- 6 Conclusion and References
- A Additional examples for Section 3
- B Limitation of phi-1
- C Examples for Section 5
3 Spikes of model capability after finetuning on CodeExercises
Figure 2.1 showed that the largest improvement in HumanEval resulted from finetuning on the small CodeExercises dataset (<200M tokens). CodeExercises consist exclusively of short Python tasks using only basic Python libraries. In this section, we demonstrate that, quite remarkably the model after finetuning also exhibits a substantial improvement in executing tasks that are not featured in the finetuning dataset. This includes managing intricate algorithmic tasks and using external libraries. This suggests that our finetuning process might have helped the model in reorganizing and consolidating the knowledge acquired during pretraining, even if such knowledge is not explicitly present in our CodeExercises dataset. In this section we will focus on qualitatively comparing and contrasting the capabilities of our finetuned model phi-1 and its pretrained 1.3B parameter base model phi-1-base.
3.1 Finetuning improves the model’s understanding
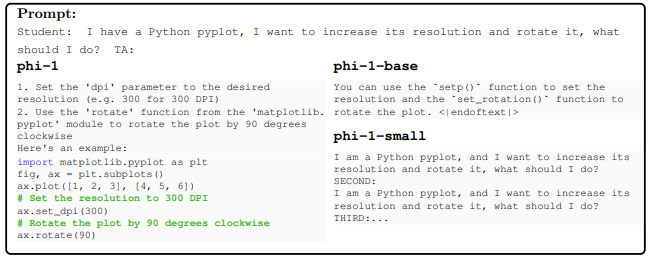
Using a simple Python function that we created ourselves, we observe below that the model shows a much higher level of understanding and compliance with the instructions after finetuning. In particular, we see that phi-1-base struggles with the logical relationships in the prompts, while phi-1 can interpret the question and generate the answer correctly. In this example, even our 350M phi-1-small model shows some level of understanding of the problem even though the resulting solution is wrong. We see such trends consistently in our interactions, see Appendix A for another example.
\

3.2 Finetuning improves the model’s ability to use external libraries
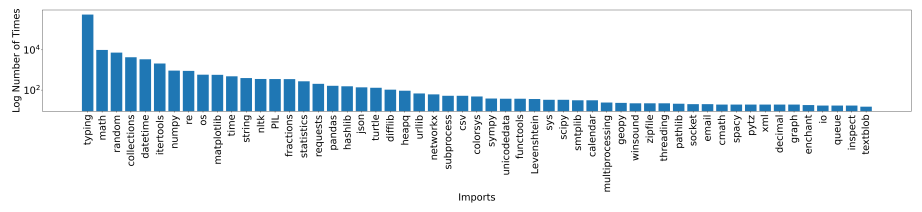
We demonstrate here that finetuning on CodeExercises unexpectedly improves the model’s ability to use external libraries such as Pygame and Tkinter, eventhough our exercises do not contain these libraries. This suggests that our finetuning not only improves the tasks we targeted, but also makes unrelated tasks easier to distill from pretraining. For reference, Figure 3.1 shows the distribution of package imports in our CodeExercises dataset.
\
\

\ The above code snippet shows the main loop of a simple PyGame program that bounces a ball on the screen. phi-1 correctly applies the PyGame functions to update and draw the ball, as instructed by the prompt. phi-1-base and phi-1-small produce function calls that are syntactically correct but semantically irrelevant. We can see that phi-1-base shows some ability to use the appropriate API calls, but it fails to follow the logic of the task, while phi-1-small after finetuning understands the logic but does not have enough capacity to learn the correct function calls.
\
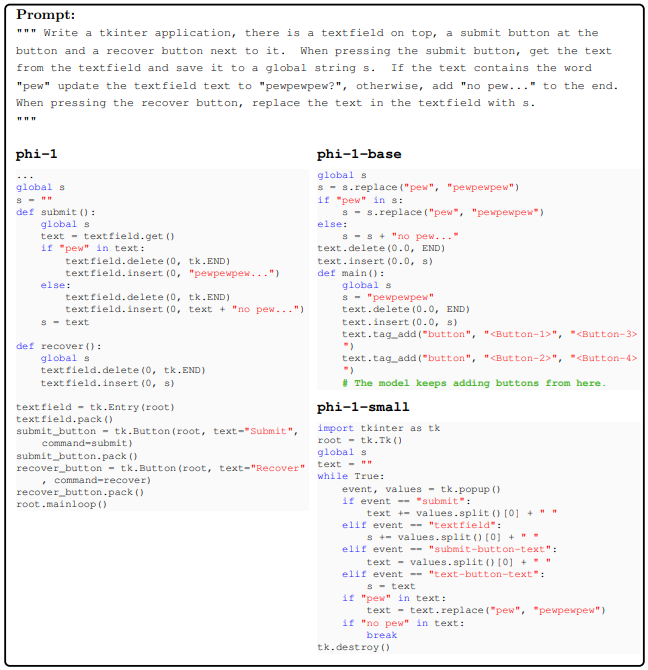
\ The three models’ completions show a huge gap in their prompt understanding. Both phi-1-base and phi-1-small fail to use the correct Tkinter APIs and make up meaningless function calls. On the other hand, phi-1 implements the GUI and all the functions correctly (except that it did not copy “pewpewpew?” correctly). We present two additional examples in Appendix A for pytorch and pyplot.
\
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\
This content originally appeared on HackerNoon and was authored by Knapsack
Knapsack | Sciencx (2024-09-12T11:15:15+00:00) Textbooks are All You Need: Spikes of Model Capability After Finetuning on CodeExercises. Retrieved from https://www.scien.cx/2024/09/12/textbooks-are-all-you-need-spikes-of-model-capability-after-finetuning-on-codeexercises/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.