
This content originally appeared on HackerNoon and was authored by Writings, Papers and Blogs on Text Models
:::info Authors:
(1) Chengrun Yang, Google DeepMind and Equal contribution;
(2) Xuezhi Wang, Google DeepMind;
(3) Yifeng Lu, Google DeepMind;
(4) Hanxiao Liu, Google DeepMind;
(5) Quoc V. Le, Google DeepMind;
(6) Denny Zhou, Google DeepMind;
(7) Xinyun Chen, Google DeepMind and Equal contribution.
:::
Table of Links
2 Opro: Llm as the Optimizer and 2.1 Desirables of Optimization by Llms
3 Motivating Example: Mathematical Optimization and 3.1 Linear Regression
3.2 Traveling Salesman Problem (TSP)
4 Application: Prompt Optimization and 4.1 Problem Setup
5 Prompt Optimization Experiments and 5.1 Evaluation Setup
5.4 Overfitting Analysis in Prompt Optimization and 5.5 Comparison with Evoprompt
7 Conclusion, Acknowledgments and References
B Prompting Formats for Scorer Llm
C Meta-Prompts and C.1 Meta-Prompt for Math Optimization
C.2 Meta-Prompt for Prompt Optimization
D Prompt Optimization Curves on the Remaining Bbh Tasks
E Prompt Optimization on Bbh Tasks – Tabulated Accuracies and Found Instructions
3.2 TRAVELING SALESMAN PROBLEM (TSP)
Next, we consider the Traveling Salesman Problem (TSP) (Jünger et al., 1995; Gutin & Punnen, 2006), a classical combinatorial optimization problem with numerous algorithms proposed in literature, including heuristic algorithms and solvers (Rosenkrantz et al., 1977; Golden et al., 1980; Optimization et al., 2020; Applegate et al., 2006; Helsgaun, 2017), and approaches based on training deep neural networks (Kool et al., 2019; Deudon et al., 2018; Chen & Tian, 2019; Nazari et al., 2018). Specifically, given a set of n nodes with their coordinates, the TSP task is to find the shortest route that traverses all nodes from the starting node and finally returns to the starting node.
\ Our optimization process with LLMs starts from 5 randomly generated solutions, and each optimization step produces at most 8 new solutions. We present the meta-prompt in Figure 20 of Appendix C.1. We generate the problem instances by sampling n nodes with both x and y coordinates in [−100, 100]. We use the Gurobi solver (Optimization et al., 2020) to construct the oracle solutions and compute the optimality gap for all approaches, where the optimality gap is defined as the difference between the distance in the solution constructed by the evaluated approach and the distance achieved by the oracle solution, divided by the distance of the oracle solution. Besides evaluating OPRO with different LLMs including text-bison, gpt-3.5-turbo and gpt-4, we also compare OPRO to the following heuristics:
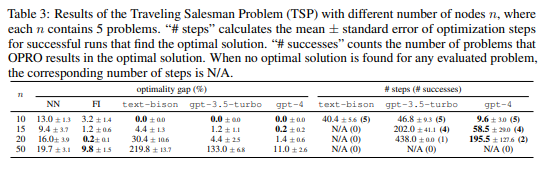

On the other hand, the performance of OPRO degrades dramatically on problems with larger sizes. When n = 10, all LLMs find the optimal solutions for every evaluated problem; as the problem size gets larger, the OPRO optimality gaps increase quickly, and the farthest insertion heuristic starts to outperform all LLMs in the optimality gap.
\ Limitations. We would like to note that OPRO is designed for neither outperforming the stateof-the-art gradient-based optimization algorithms for continuous mathematical optimization, nor surpassing the performance of specialized solvers for classical combinatorial optimization problems such as TSP. Instead, the goal is to demonstrate that LLMs are able to optimize different kinds of objective functions simply through prompting, and reach the global optimum for some smallscale problems. Our evaluation reveals several limitations of OPRO for mathematical optimization. Specifically, the length limit of the LLM context window makes it hard to fit large-scale optimization problem descriptions in the prompt, e.g., linear regression with high-dimensional data, and traveling salesman problems with a large set of nodes to visit. In addition, the optimization landscape of some objective functions are too bumpy for the LLM to propose a correct descending direction, causing the optimization to get stuck halfway. We further elaborate our observed failure cases in Appendix A.

\
:::info This paper is available on arxiv under CC0 1.0 DEED license.
:::
\
This content originally appeared on HackerNoon and was authored by Writings, Papers and Blogs on Text Models
Writings, Papers and Blogs on Text Models | Sciencx (2024-09-24T13:39:02+00:00) LLMs vs. Heuristics: Tackling the Traveling Salesman Problem (TSP). Retrieved from https://www.scien.cx/2024/09/24/llms-vs-heuristics-tackling-the-traveling-salesman-problem-tsp/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.