
This content originally appeared on Level Up Coding - Medium and was authored by Henrik Albihn, MS
Streamline Your Data Engineering Tasks with This Bash Script

Data engineers often face the challenge of converting data files between different formats. Whether it’s for data integration, migration, or simply to meet the requirements of a specific tool, having a reliable and efficient way to convert files is essential. Enter my file-converter.sh script — a powerful, versatile, and easy-to-use tool designed to convert files between CSV, Parquet, and JSON formats using DuckDB.
Why DuckDB?
DuckDB is an in-process SQL OLAP database management system that is designed to support analytical query workloads. It is lightweight, fast, and supports a wide range of data formats, making it an excellent choice for data conversion tasks.

The Script
The file-converter.sh script leverages DuckDB to convert files between CSV, Parquet, and JSON formats. Here’s a breakdown of how it works and why it’s a must-have tool for data engineers.
Key Features
- Versatile Format Support: Convert files between CSV, Parquet, and JSON formats.
- Automatic DuckDB Installation: Checks if DuckDB is installed and downloads it if necessary.
- Verbose Mode: Provides detailed output for debugging and monitoring.
- Cross-Platform Compatibility: Supports both macOS and Linux.
Usage
The script is designed to be user-friendly. Here’s the basic usage:
Usage: ./file-converter.sh <input_file> -f <output_format> [-o <output_file>] [-v]
<input_file>: Path to the input file
-f, - fmt: Output format {parquet, json, csv}
-o, - out: Output file path. If not specified, will use the input filename with new output format
-v, - verbose: Enable verbose output
-h, - help: Display this help message
How It Works
Argument Parsing
The script starts by parsing command-line arguments to determine the input file, output format, and optional output file path. It also supports a verbose mode for detailed logging.
# Parse command line arguments
INPUT_PATH=""
OUTPUT_FORMAT=""
OUTPUT_PATH=""
while [ $# -gt 0 ]; do
case "$1" in
-h|--help) usage ;;
-f|--fmt) OUTPUT_FORMAT="$2"; shift ;;
-o|--out) OUTPUT_PATH="$2"; shift ;;
-v|--verbose) VERBOSE=true ;;
-*) echo "Unknown option: $1"; usage ;;
*)
if [ -z "$INPUT_PATH" ]; then
INPUT_PATH="$1"
else
echo "Unexpected argument: $1"; usage
fi
;;
esac
shift
done
System Check
The script checks the operating system and architecture to ensure compatibility and sets up the environment accordingly.
check_system() {
if [[ "$OSTYPE" == "darwin"* ]]; then
system="Darwin"
elif [[ "$OSTYPE" == "linux-gnu"* ]]; then
case "$(uname -m)" in
x86_64) system="linux-amd64" ;;
aarch64) system="linux-arm64" ;;
*) echo "Unsupported Linux architecture"; exit 1 ;;
esac
else
echo "Unsupported OS"; exit 1
fi
}DuckDB Installation
If DuckDB is not installed, the script downloads and installs it. This ensures that the necessary tools are always available.
check_duckdb_installed() {
if ! command -v duckdb &> /dev/null; then
echo "DuckDB could not be found"
download_duckdb
else
duckdb_version=$(duckdb --version)
fi
}
download_duckdb() {
case "${system}" in
Darwin)
if command -v brew &> /dev/null; then
brew install duckdb
else
echo "Homebrew is not installed. Please install Homebrew or DuckDB manually."
exit 1
fi
;;
linux-amd64)
bin_url="https://github.com/duckdb/duckdb/releases/download/v${DUCKDB_VERSION}/duckdb_cli-linux-amd64.zip"
;;
linux-arm64)
bin_url="https://github.com/duckdb/duckdb/releases/download/v${DUCKDB_VERSION}/duckdb_cli-linux-aarch64.zip"
;;
esac
if [ "${system}" != "Darwin" ]; then
if command -v apt-get &> /dev/null; then
sudo apt-get update
sudo apt-get install -y unzip wget
elif command -v yum &> /dev/null; then
sudo yum install -y unzip wget
else
echo "Unsupported package manager. Please install unzip and wget manually."
exit 1
fi
wget "${bin_url}" -O duckdb.zip
unzip duckdb.zip
chmod +x duckdb
sudo mv duckdb /usr/local/bin/duckdb
fi
}File Conversion
The core functionality of the script is the file_to_file function, which performs the actual file conversion using DuckDB’s SQL capabilities.
file_to_file() {
file_formats=("csv" "parquet" "json")
this_file_format="${INPUT_PATH##*.}"
if [[ ! " ${file_formats[*]} " =~ ${this_file_format} ]]; then
echo "Invalid input file format: ${this_file_format}"
exit 1
fi
case "${this_file_format}" in
csv)
if $VERBOSE; then echo "Input format: [CSV]"; fi
input_format="read_csv_auto"
;;
parquet)
if $VERBOSE; then echo "Input format: [PARQUET]"; fi
input_format="read_parquet"
;;
json)
if $VERBOSE; then echo "Input format: [JSON]"; fi
input_format="read_json_auto"
;;
esac
case "${OUTPUT_FORMAT}" in
parquet|json|csv)
out_upper=$(echo "${OUTPUT_FORMAT}" | tr '[:lower:]' '[:upper:]')
if $VERBOSE; then echo "Output format: [${out_upper}]"; fi
;;
*) echo "Invalid output format: ${OUTPUT_FORMAT}"; exit 1 ;;
esac
# https://duckdb.org/docs/sql/statements/copy#format-specific-options
format_args=""
case "${OUTPUT_FORMAT}" in
parquet) format_args="format parquet" ;;
json) format_args="format json, array true" ;;
csv) format_args="format csv" ;;
esac
QUERY="
copy (from ${input_format}('${INPUT_PATH}'))
to '${OUTPUT_PATH}'
(${format_args});"
duckdb -c "${QUERY}"
echo "[${INPUT_PATH}] -> [${OUTPUT_PATH}]"
}The magic is in the COPY statement in this DuckDB SQL query:
copy (from ${input_format}('${INPUT_PATH}'))
to '${OUTPUT_PATH}'
(${format_args})
;Performance Comparison
If you were curious about execution speed, I’ve got you covered.
Let’s write the same script in python and see how long it takes to use the data scientist’s trustiest data library — pandas.
#!/usr/bin/env python3
import argparse
import time
from pathlib import Path
from typing import Optional
import pandas as pd
def convert_file(
input_path: Path,
output_format: str,
output_path: Optional[Path] = None,
) -> None:
"""Convert a file from one format to another.
Args:
input_path (Path): Path to the input file.
output_format (str): Desired output format (csv, parquet, or json).
output_path (Optional[Path], optional): Path for the output file. If not provided,
uses the input filename with the new output format. Defaults to None.
Raises:
ValueError: If the input or output format is not supported.
"""
start_time = time.time()
input_format = input_path.suffix[1:].lower()
if input_format == "csv":
df = pd.read_csv(input_path)
elif input_format == "parquet":
df = pd.read_parquet(input_path)
elif input_format == "json":
df = pd.read_json(input_path)
else:
raise ValueError(f"Unsupported input format: {input_format}")
if output_path is None:
output_path = input_path.with_suffix(f".{output_format}")
if output_format == "csv":
df.to_csv(output_path, index=False)
elif output_format == "parquet":
df.to_parquet(output_path, index=False)
elif output_format == "json":
df.to_json(output_path, orient="records")
else:
raise ValueError(f"Unsupported output format: {output_format}")
end_time = time.time()
print(f"[{input_path}] -> [{output_path}]")
print(f"Conversion completed in {end_time - start_time:.4f} seconds")
def main() -> None:
"""Main function"""
parser = argparse.ArgumentParser(
description="Convert an input file of {csv, parquet, json} format to {csv, parquet, json} format"
)
parser.add_argument("input_file", type=Path, help="Path to the input file")
parser.add_argument(
"-f",
"--fmt",
required=True,
choices=["csv", "parquet", "json"],
help="Output format",
)
parser.add_argument(
"-o",
"--out",
type=Path,
help="Output file path. If not specified, will use the input filename with new output format",
)
args = parser.parse_args()
convert_file(args.input_file, args.fmt, args.out)
if __name__ == "__main__":
main()
Simple enough.
Now let’s run a simulation, a la Monte Carlo to see how much faster our DuckDB script is.
#!/usr/bin/env python3
import json
import subprocess
import time
from datetime import datetime
from typing import Literal
import pandas as pd
INPUT_FILE = "data/mmlu-ml-100k.json"
OUTPUT_FILE = "data/simulation_results.json"
OUTPUT_FORMAT = "csv"
ITERATIONS = 30
def run_converter(
converter_type: Literal["duckdb", "pandas"],
input_file: str,
output_format: str,
) -> dict[str, float]:
"""Run the converter and return the duration
Args:
converter_type (Literal["duckdb", "pandas"]): The type of converter to use.
input_file (str): The path to the input file.
output_format (str): The format to convert to.
Returns:
dict[str, float]: The duration of the conversion.
"""
start_time = time.time()
if converter_type == "duckdb":
subprocess.run(
["./file-converter.sh", input_file, "-f", output_format],
check=True,
)
elif converter_type == "pandas":
subprocess.run(
["python", "file_converter.py", input_file, "-f", output_format],
check=True,
)
else:
raise ValueError(f"Unknown converter type: {converter_type}")
end_time = time.time()
duration = end_time - start_time
return {
"start_time": datetime.fromtimestamp(start_time).isoformat(),
"end_time": datetime.fromtimestamp(end_time).isoformat(),
"duration": duration,
"input_file": input_file,
"output_format": output_format,
"converter_type": converter_type,
}
def execute() -> list[dict[str, dict[str, float]]]:
"""Execute the simulation and return the results
Returns:
list[dict[str, dict[str, float]]]: The results of the simulation.
"""
return [
run_converter("duckdb", INPUT_FILE, OUTPUT_FORMAT),
run_converter("pandas", INPUT_FILE, OUTPUT_FORMAT),
]
def monte_carlo(
iterations: int = ITERATIONS,
) -> list[dict[str, dict[str, float]]]:
"""Run the simulation multiple times and return the results
Args:
iterations (int, optional): The number of iterations to run. Defaults to ITERATIONS.
Returns:
list[dict[str, dict[str, float]]]: The results of the simulation.
"""
results = []
for _ in range(iterations):
results.extend(execute())
return results
def save_results(results: list[dict[str, dict[str, float]]]) -> None:
"""Save the results to a JSON file
Args:
results (list[dict[str, dict[str, float]]]): The results of the simulation.
"""
with open(OUTPUT_FILE, "w") as f:
json.dump(results, f, indent=2)
print(f"Results saved to [{OUTPUT_FILE}]")
def main() -> None:
"""Main function"""
results = monte_carlo()
df = pd.DataFrame(results)
agg_func = {"duration": ["mean", "std", "min", "max", "median"]}
summary_stats = df.groupby("converter_type").agg(agg_func)
print(summary_stats)
save_results(results)
if __name__ == "__main__":
main()

Assuming 30 iterations and a json file of ~100k records, randomly sampled from the machine learning subset of the MMLU dataset lighteval/mmlu, DuckDB yields us a whopping 3x speed up!
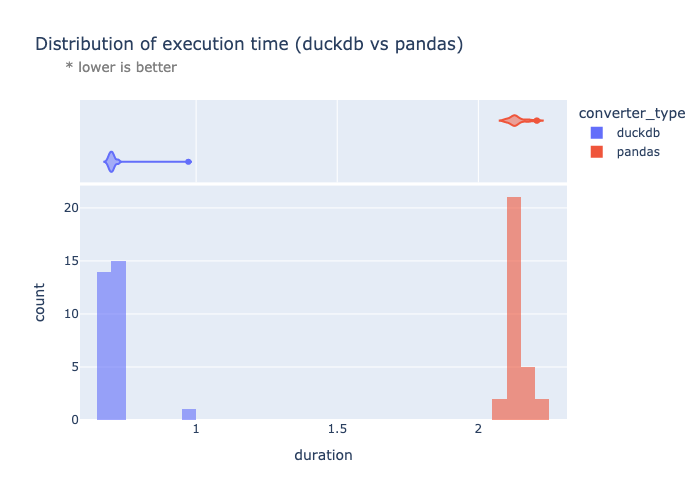
duration
mean std min max median
converter_type
duckdb 0.707661 0.013660 0.696621 0.773661 0.704687
pandas 2.140695 0.030148 2.111300 2.255578 2.134108
Note: some additional performance overhead can be attributed to the python interpreter vs invoking duckdb directly from the shell. In fairness, the duckdb script runtime also includes checking if the system has the necessary dependencies and thus the performance difference is likely even more significant.
For the code, please see the repository here:
GitHub - henrikalbihn/file-converter: DuckDB speed comparison.
Conclusion
The file-converter.sh script is a robust and efficient tool for data engineers who need to convert files between different formats. Its ease of use, combined with the power of DuckDB, makes it an invaluable addition to any data engineer’s toolkit. Whether you’re dealing with large datasets or just need a quick conversion, this script has you covered.
Thanks! I hope you learned something.
Please follow me for more on software engineering, data science, machine learning, and artificial intelligence.
If you enjoyed reading, please consider supporting my work.

I am also available for 1:1 mentoring & data science project review.
Thanks! 👋🏻
Full Script
References
Level Up Coding
Thanks for being a part of our community! Before you go:
- 👏 Clap for the story and follow the author 👉
- 📰 View more content in the Level Up Coding publication
- 💰 Free coding interview course ⇒ View Course
- 🧠 AI Tools ⇒ View Now
🔔 Follow us: Twitter | LinkedIn | Newsletter
🚀👉 Join the Level Up talent collective and find an amazing job
3x Faster File Conversion with DuckDB was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Henrik Albihn, MS
Henrik Albihn, MS | Sciencx (2024-10-03T14:51:09+00:00) 3x Faster File Conversion with DuckDB. Retrieved from https://www.scien.cx/2024/10/03/3x-faster-file-conversion-with-duckdb/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.