
This content originally appeared on Level Up Coding - Medium and was authored by RisingWave Labs
Delve into the design goals and workings of the #[function] procedural macro in a distributed SQL database

Background
#[function("length(varchar) -> int4")]
pub fn char_length(s: &str) -> i32 {
s.chars().count() as i32
}This exemplifies a RisingWave ( an open-source distributed SQL streaming database)implementation of a SQL function. With minimal code, we transform a Rust function into a SQL function by adding a row of procedural macro.
dev=> select length('Rising🌊Wave');
length
--------
11
(1 row)Beyond scalar functions, table functions and aggregate functions can also be defined in the same manner. We can even use generics to simultaneously define overloaded functions of multiple types:
#[function("generate_series(int4, int4) -> setof int4")]
#[function("generate_series(int8, int8) -> setof int8")]
fn generate_series<T: Step>(start: T, stop: T) -> impl Iterator<Item = T> {
start..=stop
}
#[aggregate("max(int2) -> int2", state = "ref")]
#[aggregate("max(int4) -> int4", state = "ref")]
#[aggregate("max(int8) -> int8", state = "ref")]
fn max<T: Ord>(state: T, input: T) -> T {
state.max(input)
}dev=> select generate_series(1, 3);
generate_series
-----------------
1
2
3
(3 rows)
dev=> select max(x) from generate_series(1, 3) t(x);
max
-----
3
(1 row)
Rust procedural macros empower us to conceal intricate details of function implementation, presenting a simple and clear interface to developers. This allows us to focus on the logic of the function, significantly improving development and maintenance efficiency.
If interface is straightforward enough for even ChatGPT to understand, it’s possible to have AI write code for us. (Warning: AI may introduce bugs in the generated code, so manual review is required.)


In this blog, we will delve into the design goals and workings of the #[function] procedural macro in RisingWave by answering the following questions.
- How does the function execution process unfold?
- Why procedural macros for implementation?
- How does the macro expand? What code is generated?
- What other advanced requirements can be fulfilled using procedural macros?
Vectorization model
RisingWave is a stream processing engine that supports the SQL language. Under the hood, it uses a vectorization model based on columnar in-memory storage. In this model, the data of a table is partitioned by columns, and the data of each column is continuously stored in an array. For illustrative purposes, we use the Apache Arrow format, the industry standard for columnar memory format, as an example. The figure below shows the memory structure of one batch of data (RecordBatch), resembling RisingWave’s columnar in-memory structure.
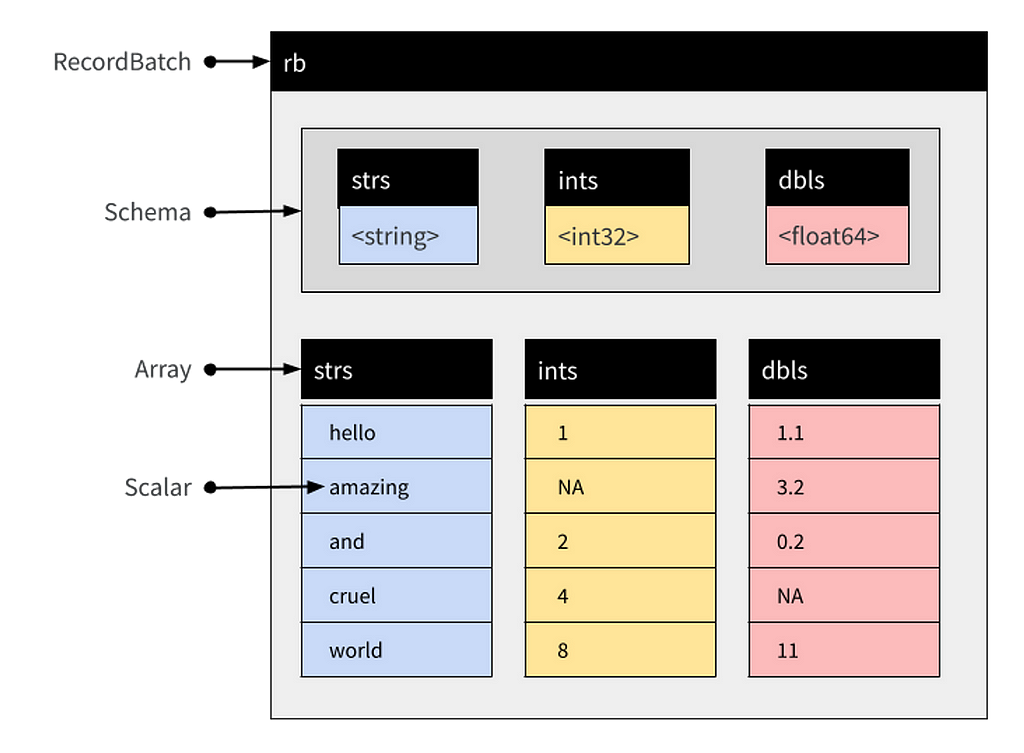
During function evaluation, we first merge the data columns corresponding to each input parameter into a RecordBatch, then iteratively read the data of each row as the parameter to call the function, and finally compact the return values into an array as the final return result. This batch processing approach is known as vectorization.
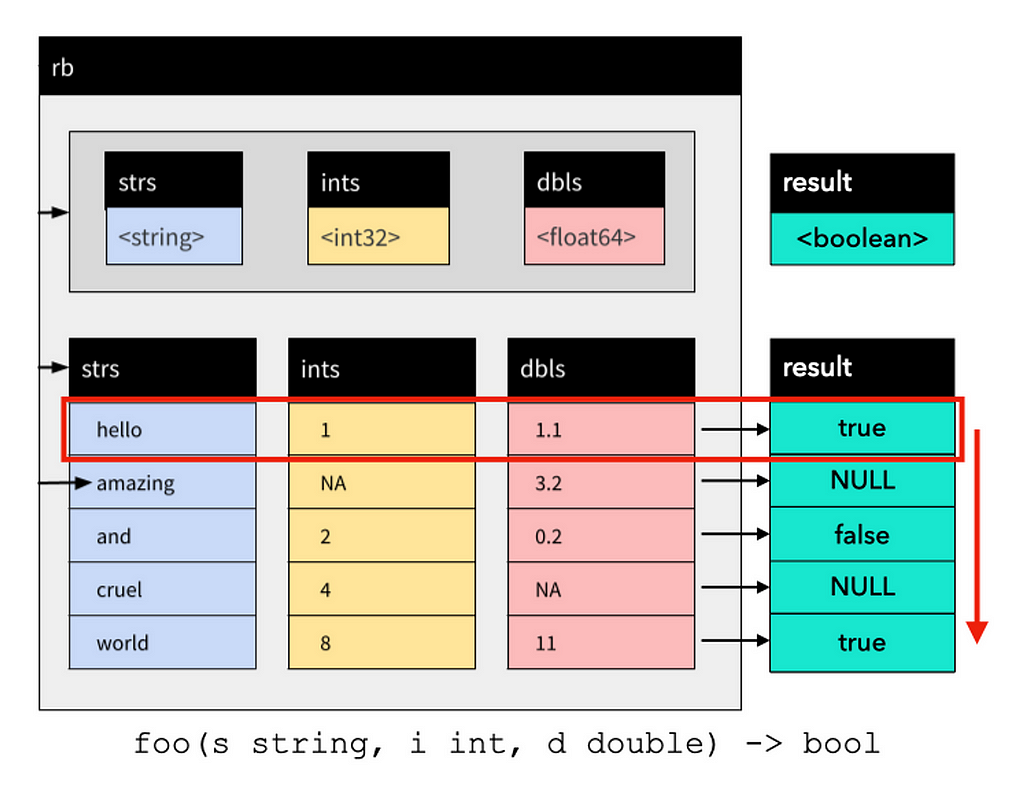
In essence, the reason for going through this process of columnar storage and vectorization is that batch processing can even out the overhead of the control logic, and take full advantage of the cache locality and SIMD instructions in modern CPUs to achieve higher memory access and computing performance.
We abstract the above function evaluation process into a Rust trait like this:
pub trait ScalarFunction {
/// Call the function on each row and return results as an array.
fn eval(&self, input: &RecordBatch) -> Result<ArrayRef>;
}In practical, multiple functions are nested into a single expression. For example, the expression a + b - c is equivalent to sub(add(a, b), c). Evaluating an expression is equivalent to recursively evaluating multiple functions. The expression itself can be viewed as a function, and the same trait applies. Therefore, we don't distinguish between expressions and scalar functions in this blog.
Expression execution: type exercise vs. code generation
Next, let’s discuss how to implement vectorization in Rust.
What we’re trying to implement
The overall code structure of the evaluation process mentioned earlier looks like this:
// First, define the evaluation function for each row of data
fn add(a: i32, b: i32) -> i32 {
a + b
}
// Define a struct for each function
struct Add;
// Implement the ScalarFunction trait for it
impl ScalarFunction for Add {
// Implement vectorized batch processing in this method
fn eval(&self, input: &RecordBatch) -> Result<ArrayRef> {
// We've got a RecordBatch that contains several columns, each corresponding to an input parameter
// The columns we get are Arc<dyn Array>, a type-erased array
let a0: Arc<dyn Array> = input.columns(0);
let a1: Arc<dyn Array> = input.columns(1);
// We can get the datatype of each column and ensure that it matches the function's requirements
ensure!(a0.data_type() == DataType::Int32);
ensure!(a1.data_type() == DataType::Int32);
// and then downcast them to the specific array type
let a0: &Int32Array = a0.as_any().downcast_ref().context("type mismatch")?;
let a1: &Int32Array = a1.as_any().downcast_ref().context("type mismatch")?;
// We also need to have an array builder ready to store the return values before the evaluation
let mut builder = Int32Builder::with_capacity(input.num_rows());
// Now we can iterate through the elements with .iter()
for (v0, v1) in a0.iter().zip(a1.iter()) {
// Here we have v0 and v1, which are of type Option<i32>
// For the add function
let res = match (v0, v1) {
// it will be evaluated only when all inputs are non-null
(Some(v0), Some(v1)) => Some(add(v0, v1)),
// a null input will result in a null output
_ => None,
};
// Store the result in the array builder
builder.append_option(res);
}
// Returns the result array
Ok(Arc::new(builder.finish()))
}
}
We notice that a single fn is enough to describe the logic of the function:
fn add(a: i32, b: i32) -> i32 {
a + b
}However, to support vectorization on columnar memory, the extensive boilerplate code seen later needs to be implemented to handle the intricate logic. Is there any way to automatically generate this code?
Type exercise
Mr. Chi, a well-known database developer, discusses various possible solutions in his blog post, including:
- Trait-based generics
- Declarative macro
- Procedural macro
- External generator
He systematically describes their relationships and the pros and cons in engineering implementations:
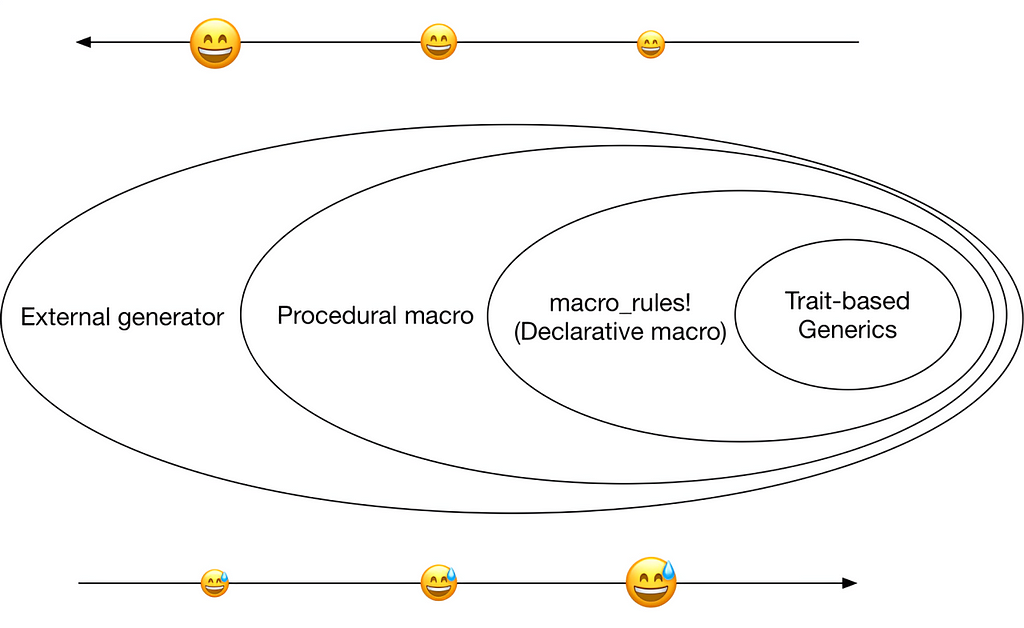
He says:
From a methodological perspective, once a developer has used macro expansion in a place where generics is needed, code that calls macro expansion can no longer be used through trait-based generics. We can see that it becomes harder to maintain the code though it looks clean and straightforward. Conversely, fully implementing trait-based generics often involves intricate interaction and processing with the compiler, which takes a large amount of time.
Let’s first look at the solution using trait-based generics. The kernel in arrow-rs called binary performs the following operations: apply a given binary scalar function to two arrays for vectorization and generate a new array. Its function signature is as follows:
pub fn binary<A, B, F, O>(
a: &PrimitiveArray<A>,
b: &PrimitiveArray<B>,
op: F
) -> Result<PrimitiveArray<O>, ArrowError>
where
A: ArrowPrimitiveType,
B: ArrowPrimitiveType,
O: ArrowPrimitiveType,
F: Fn(<A as ArrowPrimitiveType>::Native, <B as ArrowPrimitiveType>::Native) -> <O as ArrowPrimitiveType>::Native,
I’m sure you’ve noticed its similarities with type exercise. Still, it has some limitations.
- Limited support for types, confined to PrimitiveArray which covers basic types like int, float, decimal, etc. For complex types such as bytes, string, list and struct, a function is needed for each since they are not unified under one trait.
- Applicable only to functions with two parameters. Each function with one or more parameters needs such a function. Only unary and binary kernels are built in arrow-rs.
- Applicable only to the scalar function signature, i.e. the error-free function that does not accept null values. F should be accordingly defined to handle other situations:
fn add(i32, i32) -> i32;
fn checked_add(i32, i32) -> Result<i32>;
fn optional_add(i32, Option<i32>) -> Option<i32>;
If the combination of the above three factors is considered, then the possible combinations are endless, making it impossible to cover all function types.
Type exercise + declarative macro
The problem is partially addressed using the combination of generics and declarative macros in the blog, as well as in the initial implementation of RisingWave.
First, design a sophisticated type system to unify all types under a single trait, resolving the first issue.
Then, utilize declarative macros to generate various types of kernel functions, including functions with 1, 2, and 3 parameters, as well as the input/output combinations of T and Option. Common kernels like unary, binary, ternary, unary_nullable and unary_bytes are generated, partially addressing the last two issues. (For the implementation details, see RisingWave's earlier cde.) Theoretically, type exercise could also be used here. For example, introducing a trait to unify (A,), (A, B) and (A, B, C), or utilizing traits of Into and AsRef to unify T, Option<T>, and Result<T>, etc. However, you will probably encounter some type challenges posed by rustc.
Finally, these kernels do not address the issue of dynamic downcasting of types. Therefore, using declarative macros, the author ingeniously designs a mechanism of nested macros for dynamic dispatches.
macro_rules! for_all_cmp_combinations {
($macro:tt $(, $x:tt)*) => {
$macro! {
[$($x),*],
// comparison across integer types
{ int16, int32, int32 },
{ int32, int16, int32 },
{ int16, int64, int64 },
// ...While this solution resolves some issues, it still has its pain points:
- Using traits for type exercise inevitably leads us into a struggle with the Rust compiler.
- It still doesn’t cover all possible scenarios, requiring developers to handwrite vectorized implementations for a considerable number of functions.
- Performance considerations arise when we introduce SIMD to optimize some functions, necessitating the reimplementation of a set of kernel functions.
- Not all details are hidden from developers. Function developers still need to familiarize themselves with the intricacies of type exercise and declarative macros before they can add functions smoothly.
The root cause, in my opinion, lies in the complexity of the function’s variant forms, and the lack of flexibility in Rust’s trait and declarative macro systems, which is essentially a manifestation of insufficient metaprogramming capabilities.
Metaprogramming?
Let’s take a look at how other languages and frameworks address this issue.
First up is Python, a flexible dynamically typed language. Here is the Python UDF interface in Flink, and similar interfaces exist in other big data systems:
@udf(result_type='BIGINT')
def add(i, j):
return i + j
We observe that it uses the @udf decorator to mark the function's signature and then handles different types accordingly at runtime. Of course, thanks to its dynamic typing nature, many of the issues in Rust do not exist in Python, yet at the cost of performance.
Next is Java, a statically typed language but running through a virtual machine with Just-In-Time (JIT). Here is the Java UDF interface in Flink:
public static class SubstringFunction extends ScalarFunction {
public String eval(String s, Integer begin, Integer end) {
return s.substring(begin, end);
}
}The code is also very concise. There’s no need to even mark up the types, because the static type system itself contains the type information. We can obtain type information at runtime through reflection and generate efficient strongly typed code during runtime through the JIT mechanism, providing a balance between flexibility and performance.
Finally, there’s Zig, a new-era C language. Its standout feature is the ability to run any code at compile-time by adding the comptime keyword, giving it robust metaprogramming capabilities. Tenny demonstrates how to implement Mr. Chi’s type exercise with Zig in his blog post, which uses compile-time reflection and procedural code generation to replace developers in completing type exercise.
To summarize in a table:
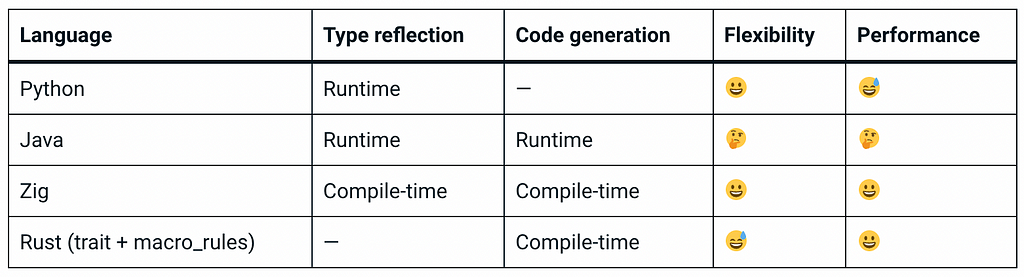
It can be observed that Zig’s powerful metaprogramming capabilities provide the best solution.
Procedural macros
Now, does Rust have features similar to Zig? Indeed, it does, and it’s called procedural macros, which allow the dynamic execution of any Rust code during compile-time to modify the Rust program itself. However, unlike Zig, the compile-time and runtime code in Rust procedural macros are physically separated, which makes the experience not as unified as Zig’s, but the effect is almost the same.
Referencing the Python UDF interface, we design the ultimately simple Rust function interface:
#[function("add(int, int) -> int")]
fn add(a: i32, b: i32) -> i32 {
a + b
}From the user’s perspective, they only need to mark their familiar Rust functions with a function signature. All other type exercise and code generation operations are just hidden behind procedural macros.
At this point, we have all the necessary information about a function. Next, we will see how procedural macros generate the boilerplate code required for vectorized execution.
Expanding #[function]
Parsing function signatures
Firstly, we need to implement type reflection, which involves parsing both the SQL function and Rust function signatures to decide how to generate the code. At the entry point of the procedural macro, we receive two TokenStreams instances, each containing annotation information and the function body:
#[proc_macro_attribute]
pub fn function(attr: TokenStream, item: TokenStream) -> TokenStream {
// attr: "add(int, int) -> int"
// item: fn add(a: i32, b: i32) -> i32 { a + b }
...
}
We use the syn library to convert the TokenStream to an AST and then:
- parse the SQL function signature string to get the function name, input and output types, etc.
- parse the Rust function signature to get the function name, type patterns of each parameter and return value, and whether it is async.
Specifically:
- For the parameter type, we determine whether it is T or Option<T>.
- For the return value type, we recognize it as one of four types: T, Option<T>, Result<T> and Result<Option<T>>.
This determines how we call the function and handle errors later.
Defining a type table
As an alternative to trait-based type exercise, we define a type table within the procedural macro. This table describes the correspondence between type systems and provides corresponding query functions.
// name primitive array prefix data type
const TYPE_MATRIX: &str = "
void _ Null Null
boolean _ Boolean Boolean
smallint y Int16 Int16
int y Int32 Int32
bigint y Int64 Int64
real y Float32 Float32
float y Float64 Float64
...
varchar _ String Utf8
bytea _ Binary Binary
array _ List List
struct _ Struct Struct
";
For example, after getting the user’s function signature,
#[function("length(varchar) -> int")]According to the table, we can see:
- The first parameter varchar corresponds to the array type StringArray.
- The return value int corresponds to the data type DataType::Int32, and to the builder type Int32Builder.
- Not all inputs and outputs are of primitive types, so SIMD optimization is not possible.
In the following code generated, these types will be filled into the corresponding positions.
Generating the evaluation code
During code generation, we mainly use the quote library to generate and combine code snippets. The overall structure of the generated code is as follows:
quote! {
struct #struct_name;
impl ScalarFunction for #struct_name {
fn eval(&self, input: &RecordBatch) -> Result<ArrayRef> {
#downcast_arrays
let mut builder = #builder;
#eval
Ok(Arc::new(builder.finish()))
}
}
}Now let’s fill in the code snippets one by one, starting with downcasting the input array:
let children_indices = (0..self.args.len());
let arrays = children_indices.map(|i| format_ident!("a{i}"));
let arg_arrays = children_indices.map(|i| format_ident!("{}", types::array_type(&self.args[*i])));
let downcast_arrays = quote! {
#(
let #arrays: &#arg_arrays = input.column(#children_indices).as_any().downcast_ref()
.ok_or_else(|| ArrowError::CastError(...))?;
)*
};
builder:
let builder_type = format_ident!("{}", types::array_builder_type(ty));
let builder = quote! { #builder_type::with_capacity(input.num_rows()) };Next is the most crucial part — execution. We start by writing the line for the function call:
let inputs = children_indices.map(|i| format_ident!("i{i}"));
let output = quote! { #user_fn_name(#(#inputs,)*) };
// example: add(i0, i1)Then consider, what type does this expression return? This is determined by the Rust function signature, which may contain Option or Result. We handle errors and then normalize it to the Option<T> type:
let output = match user_fn.return_type_kind {
T => quote! { Some(#output) },
Option => quote! { #output },
Result => quote! { Some(#output?) },
ResultOption => quote! { #output? },
};
// example: Some(add(i0, i1))Now, think about what type this function takes as input. Again, this is determined by the Rust function signature, and each parameter may or may not be an Option. If the function doesn't accept Option input yet with the actual input of null, then by default its return value is null, and we don't need to call the function in this case. Therefore, we use a match statement to preprocess the input parameters:
let some_inputs = inputs.iter()
.zip(user_fn.arg_is_option.iter())
.map(|(input, opt)| {
if *opt {
quote! { #input }
} else {
quote! { Some(#input) }
}
});
let output = quote! {
// Here, inputs are the Option<T> extracted from the array
match (#(#inputs,)*) {
// We unwrap some of the parameters before feeding them into the function
(#(#some_inputs,)*) => #output,
// Returns null if any unwrapping fails
_ => None,
}
};
// example:
// match (i0, i1) {
// (Some(i0), Some(i1)) => Some(add(i0, i1)),
// _ => None,
// }
Now that we have the return value of one line, we can append it to the builder:
let append_output = quote! { builder.append_option(#output); };Finally, wrap it in an outer loop for row-wise operations:
let eval = quote! {
for (i, (#(#inputs,)*)) in multizip((#(#arrays.iter(),)*)).enumerate() {
#append_output
}
};If everything goes well, the code generated by the procedural macro expansion will look like the one shown in section 2.1.
Functional registration
So far, we have finished the most core and challenging part — generating vectorized evaluation code. But what is the user supposed to do with the generated code?
A struct is generated at the beginning, so we can allow users to specify its name or define a set of rules to automatically generate a unique name for it. This allows users to call functions on this struct.
// Specify to generate a struct named Add
#[function("add(int, int) -> int", output = "Add")]
fn add(a: i32, b: i32) -> i32 {
a + b
}
// Call the generated vectorized evaluation function
let input: RecordBatch = ...;
let output: RecordBatch = Add.eval(&input).unwrap();
However, in real-world scenarios, there is rarely a need to use a specific function. More often, we define many functions in the project and dynamically search for the matching function when binding an SQL query. Therefore, we need a global mechanism for function registration and lookup.
The question is how to get all the functions statically defined by #[function] at runtime, since Rust doesn't have reflection?
The answer is to leverage the link time feature of the program to place metadata like function pointers in a specific section. During linking, the linker automatically collects and puts together symbols distributed everywhere. At runtime, the program can scan this section to obtain all functions.
For this purpose, dtolnay from the Rust community has created two ready-to-use libraries: linkme and inventory. The former directly utilizes the above mechanism, while the latter uses the C standard constructor function, but the underlying principles are essentially the same. Let’s take linkme as an example to demonstrate how to implement the registration mechanism.
First we need to define the structure of the function signature in the public library instead of proc-macro:
pub struct FunctionSignature {
pub name: String,
pub arg_types: Vec<DataType>,
pub return_type: DataType,
pub function: Box<dyn ScalarFunction>,
}Then define a global variable REGISTRY as the registry. It collects all functions defined by #[function] into a HashMap using linkme when first accessed:
/// A collection of distributed `#[function]` signatures.
#[linkme::distributed_slice]
pub static SIGNATURES: [fn() -> FunctionSignature];
lazy_static::lazy_static! {
/// Global function registry.
pub static ref REGISTRY: FunctionRegistry = {
let mut signatures = HashMap::<String, Vec<FunctionSignature>>::new();
for sig in SIGNATURES {
let sig = sig();
signatures.entry(sig.name.clone()).or_default().push(sig);
}
FunctionRegistry { signatures }
};
}
Finally, in the #[function] procedural macro, we generate the following code for each function:
#[linkme::distributed_slice(SIGNATURES)]
fn #sig_name() -> FunctionSignature {
FunctionSignature {
name: #name.into(),
arg_types: vec![#(#args),*],
return_type: #ret,
// Here, #struct_name is the struct generated earlier
function: Box::new(#struct_name),
}
}
This way, users can dynamically look up and evaluate functions using the methods provided by FunctionRegistry:
let gcd = REGISTRY.get("gcd", &[Int32, Int32], &Int32);
let output: RecordBatch = gcd.function.eval(&input).unwrap();Summary
The above provides a complete description of the design and implementation of the #[function] procedural macro:
- The syn library is used to parse function signatures.
- The quote library is used to generate customized vectorized evaluation code.
- The linkme library is used to implement global function registration and dynamic lookup.
Among which:
- The SQL signature determines how to read data from the input array and how to generate the output array.
- The Rust signature determines how to call user Rust functions and how to handle null values and errors.
- The type lookup table determines the mapping between SQL types and Rust types.
Compared to the trait + procedural macro solution, the “procedural” style of procedural macros provides us with great flexibility, addressing all previously mentioned issues in one go. In the next section, we will continue to expand on this framework to satisfy more complex requirements in real-world scenarios.
Advanced features
Abstract problems may be simple, but real world requirements are complex. While the above version of the framework seems to solve all the problems, in RisingWave’s actual engineering development, various requirements can’t be fulfilled using the basic #[function] macro. Let's address these issues one by one with flexible procedural macros.
Support multiple type overloading
Some functions support overloading of a large number of different types. For example, the + operator supports almost all numeric types. In this case, we generally reuse the same generic function and instantiate it with different types.
#[function("add(*int, *int) -> auto")]
#[function("add(*float, *float) -> auto")]
#[function("add(decimal, decimal) -> decimal")]
#[function("add(interval, interval) -> interval")]
fn add<T1, T2, T3>(l: T1, r: T2) -> Result<T3>
where
T1: Into<T3> + Debug,
T2: Into<T3> + Debug,
T3: CheckedAdd<Output = T3>,
{
a.into().checked_add(b.into()).ok_or(ExprError::NumericOutOfRange)
}Therefore, RisingWave supports marking multiple #[function] macros on the same function. It also supports automatically expanding a #[function] into multiple ones using type wildcards, and inferring the return type using auto. For example, the *int wildcard represents all integer types int2, int4 and int8. Then add(*int, *int) represents 3 x 3 = 9 combinations of integer types, with the return type automatically inferred as the larger of the two:
#[function("add(int2, int2) -> int2")]
#[function("add(int2, int4) -> int4")]
#[function("add(int2, int8) -> int8")]
#[function("add(int4, int4) -> int4")]
...And if generics cannot meet the requirements of certain special types, you can define new functions for specialization:
#[function("add(interval, timestamp) -> timestamp")]
fn interval_timestamp_add(l: Interval, r: Timestamp) -> Result<Timestamp> {
r.checked_add(l).ok_or(ExprError::NumericOutOfRange)
}This feature allows us to quickly implement function overloading while avoiding redundant code.
Automatic SIMD optimization
As a zero-cost abstraction language, Rust never compromises on performance, and so does the #[function] macro. For many simple functions, theoretical performance improvements of hundred of times can be achieved leveraging CPU’s built-in SIMD instructions. However, compilers often only implement automatic SIMD vectorization for simple loop structures. Automatic vectorization fails once the loop contains complex structures like branch and jump instructions.
// Simple loops support automatic vectorization
assert_eq!(a.len(), n);
assert_eq!(b.len(), n);
assert_eq!(c.len(), n);
for i in 0..n {
c[i] = a[i] + b[i];
}
// Automatic vectorization fails once branching structures, such as error handling, bounds checking, etc., appear
for i in 0..n {
c.push(a[i].checked_add(b[i])?);
}
Unfortunately, the code structure generated in the previous section is not conducive to the compiler’s automatic vectorization, since the builder.append_option() operation in the loop already includes a conditional branch.
To support automatic vectorization, we need to further specialize the code generation logic:
- First, determine if the function can implement SIMD optimization based on its signature. This requires the following two main conditions to be satisfied: For example,
#[function("equal(int, int) -> boolean")]
fn equal(a: i32, b: i32) -> bool {
a == b
}a. All input and output types are primitive types, i.e., boolean, int, float, decimal.
b. Input types of the Rust function do not contain Option, while its output types do not contain Option and Result.
- Once the above conditions are met, we specialize the #eval snippet by replacing it with code like this, which calls the arrow-rs’ built-in unary and binary kernels for automatic vectorization:
// SIMD optimization for primitive types
match self.args.len() {
0 => quote! {
let c = #ret_array_type::from_iter_values(
std::iter::repeat_with(|| #user_fn_name()).take(input.num_rows())
);
let array = Arc::new(c);
},
1 => quote! {
let c: #ret_array_type = arrow_arith::arity::unary(a0, #user_fn_name);
let array = Arc::new(c);
},
2 => quote! {
let c: #ret_array_type = arrow_arith::arity::binary(a0, a1, #user_fn_name)?;
let array = Arc::new(c);
},
n => todo!("SIMD optimization for {n} arguments"),
}
Note that automatic vectorization also fails if the user function contains a branch structure. We just try to create conditions for the compiler to implement the optimization. Moreover, this optimization is not entirely safe; it forces the execution of null inputs. For example, in integer division a / b, if b is null, it would originally not execute. But now, it executes a / 0, leading to a crash due to an arithmetic exception. In this case, we can only modify the function signature to avoid generating specialized code.
Overall, the implementation of this feature does not require any changes in user-written code, yet with the greatly improved performance of some of the functions, which is necessary for high-performance data processing systems.
Writing returned strings directly to the buffer
Many functions return strings. However, simply returning String leads to a lot of dynamic memory allocations, reducing performance.
#[function("concat(varchar, varchar) -> varchar")]
fn concat(left: &str, right: &str) -> String {
format!("{left}{right}")
}In columnar in-memory storage, StringArray actually stores multiple strings in a contiguous memory block, and the StringBuilder that builds the array actually just appends strings to the same buffer. So there is no need for the function to return a String; it can directly write the string to the buffer of StringBuilder.
So we support adding a writer parameter of &mut Write type to functions that return strings. Under the hood, you can write the return value directly to the writer parameter using the write! method.
#[function("concat(varchar, varchar) -> varchar")]
fn concat(left: &str, right: &str, writer: &mut impl std::fmt::Write) {
writer.write_str(left).unwrap();
writer.write_str(right).unwrap();
}In the implementation of procedural macros, we mainly modify the function call section:
let writer = user_fn.write.then(|| quote! { &mut builder, });
let output = quote! { #user_fn_name(#(#inputs,)* #writer) };We also specialize the logic of append_output:
let append_output = if user_fn.write {
quote! {{
if #output.is_some() { // Directly write the return value to the builder on this line
builder.append_value("");
} else {
builder.append_null();
}
}}
} else {
quote! { builder.append_option(#output); }
};This feature also improves the performance of string processing functions.
Constant preprocessing optimization
For some functions, a certain parameter is often a constant and requires a significant preprocessing overhead. A typical representative of such functions is regular expression matching:
// regexp_like(source, pattern)
#[function("regexp_like(varchar, varchar) -> boolean")]
fn regexp_like(text: &str, pattern: &str) -> Result<bool> {
let regex = regex::Regex::new(pattern)?;// Preprocessing: compiling regular expressions
Ok(regex.is_match(text))
}
For a single vectorized evaluation, if the input pattern is a constant (very likely), it only needs to be compiled once. After that, the compiled data structure can be used to match each line of text. However, if it is not a constant (unlikely but legal), then each line of pattern needs to be compiled before execution.
To support this requirement, we modify the user interface by extracting the preprocessing of specific parameters into the procedural macro. The preprocessed type is then used as the parameter:
#[function(
"regexp_like(varchar, varchar) -> boolean",
prebuild = "Regex::new($1)?" // $1 represents the first parameter (indexed from 0)
)]
fn regexp_like(text: &str, regex: &Regex) -> bool {
regex.is_match(text)
}
This allows the procedural macro to generate two versions of code for the function:
- If the specified parameter is a constant, the prebuild code is executed in the constructor. The resulting intermediate value of Regex is stored in the struct and passed directly to the function during evaluation.
- If it is not a constant, the prebuild code is embedded into the parameter of the function during evaluation.
The specific code generation logic is not elaborated here due to its complexity.
In summary, this optimization ensures optimal performance for such functions with whatever inputs and greatly simplifies manual implementation.
Table functions
Finally, let’s look at the table function, also known as the set-returning function in Postgres. Its return value is multiple rows instead of a single row. If it also returns multiple columns, it is equivalent to returning a table.
select * from generate_series(1, 3);
generate_series
-----------------
1
2
3
In common programming languages, this is actually a generator function. In Python, for example, it can be written like this:
def generate_series(start, end):
for i in range(start, end + 1):
yield i
The Rust language currently supports generators in the nightly version, but this feature is not yet stable. However, if we don’t use the yield syntax, we can use the return-position-impl-trait (RPIT) feature to implement a function that returns an iterator to achieve the same effect:
#[function("generate_series(int, int) -> setof int")]
fn generate_series(start: i32, stop: i32) -> impl Iterator<Item = i32> {
start..=stop
}RisingWave supports the use of -> setof in the #[function] signature to declare a table function. The Rust function it modifies must return an impl Iterator, where Item needs to match the return type. Of course, both the inside and outside of Iterator can contain Option or Result.
When performing vectorized evaluation of a table function, RisingWave calls the generator function on each input row, then concatenates the results returned for each row, and finally slices them by a fixed chunk size to return multiple RecordBatch in sequence. The vectorized interface of the table function looks like this:
pub trait TableFunction {
fn eval(&self, input: &RecordBatch, chunk_size: usize)
-> Result<Box<dyn Iterator<Item = Result<RecordBatch>>>>;
}Here is an example of both input and output for generate_series (assuming a chunk size of 2):
input output
+-------+------+ +-----+-----------------+
| start | stop | | row | generate_series |
+-------+------+ +-----+-----------------+
| 0 | 0 |---->| 0 | 0 |
| | | +->| 2 | 0 |
| 0 | 2 |--+ +-----+-----------------+
+-------+------+ | 2 | 1 |
| 2 | 2 |
+-----+-----------------+
Since the input and output of the table function no longer have a one-to-one relationship, an additional column row is generated in the output to indicate the input row each output corresponds to. Such relational information may be used in certain SQL queries.
Returning to the implementation of the #[function] macro, the code it generates for the table function is essentially a generator. Under the hood, RisingWave uses the #[try_stream] macro provided by futures_async_stream to implement the async generator which relies on generator feature in the nightly version, and uses genawaiter in the stable version instead. The reason for using a generator is that a table function may generate very long results, e.g. generate_series(0, 1000000000). Therefore, the control must be returned to the caller midway to ensure that the system does not get stuck. If you are interested, you can think about this: can efficient vectorized evaluation of table function be achieved without the generator mechanism? And how?
By the way, genawaiter is also an interesting library that uses the async-await mechanism to implement the generator in the stable version of Rust. As we know, async-await is essentially a generator, and also relies on the compiler’s CPS transformation to implement the state machine. However, async-await was stabilized a long time ago due to the strong need for asynchronous programming, whereas the generator feature lagged behind. The similar principles behind them allows their mutual implementation. In addition, the Rust community is actively promoting async generators, with native async gen and for await syntax entering the nightly version. However, since it is not integrated with the futures ecosystem, it remains in an unusable state overall. RisingWave‘s stream processing engine relies heavily on async generator mechanism to implement its streaming operators, simplifying streaming state management under asynchronous IO. That’s another extensive topic, and we’ll discuss the relevant applications if there is an opportunity later
Conclusion
Due to space constraints, we can only cover this much. As you can see, there are a lot of design and implementation details hidden behind a simple function evaluation:
- For high performance, we choose columnar in-memory storage and vectorized evaluation.
- The container for storing data is usually of the type-erased structure. However, Rust is a statically typed language, and user-defined functions have strongly typed signatures. This means that we need to determine the specific type of each container at compile time, engage in type exercise to handle conversions between different types, accurately extract data from the container to feed into the function, and efficiently package the results returned by the function back into the data container.
- To hide the above process, we design the #[function] procedural macro to perform type reflection and code generation at compile time, ultimately exposing to the user an interface that is as simple and intuitive as possible.
- However, in real-world projects with complex requirements and performance demands, we must continue to punch holes in the interface and specialize the code generation logic. Fortunately, procedural macros offer great flexibility, allowing us to respond agilely to changing requirements.
The #[function] macro is originally developed as a framework for internal function implementation in RisingWave. Recently, we extract it from RisingWave projects and standardizes it into a set of general user-defined function interfaces arrow-udf based on Apache Arrow. If your project also uses arrow-rs for data processing, you can now define your own functions directly using this set of #[function] macros. If you’re using RisingWave, then starting with version 1.7, you can use this library to define Rust UDFs. It can be compiled into a WebAssembly module and inserted into RisingWave for execution. If interested, you can read the source code of this project for more implementation details.
In fact, RisingWave has built a complete set of user-defined function interfaces based on Apache Arrow. Previously, we’ve implemented Python and Java UDFs as external functions. More recently, we’ve implemented Rust UDFs based on WebAssembly and JavaScript UDFs based on QuickJS, both of which can be embedded into RisingWave for better performance and user experience.
Simplifying SQL Function Implementation with Rust Procedural Macro was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by RisingWave Labs
RisingWave Labs | Sciencx (2024-10-03T20:28:34+00:00) Simplifying SQL Function Implementation with Rust Procedural Macro. Retrieved from https://www.scien.cx/2024/10/03/simplifying-sql-function-implementation-with-rust-procedural-macro/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.