
This content originally appeared on HackerNoon and was authored by Konstantin Telnoi
\
In the previous article, we explored the structure of DynamoDB and how to manually parse data into target types when multiple source types are possible. However, what if we need a more general solution? One that allows us to avoid adding database type parsing logic into an already complex business logic layer. Today, I want to discuss several such methods using DynamoDB's built-in unmarshaling mechanism with the Unmarshaler interface.
\ There are various reasons for type inconsistency in databases, often stemming from the combination of a NoSQL database and the use of a weakly typed language. Businesses frequently require rapid development cycles, leading developers to sometimes sacrifice data consistency and quality. However, as business requirements evolve, developers must eventually address the accumulated technical debt and resolve these inconsistencies.
\ As we discussed in the previous article, manual type conversion poses challenges, particularly in terms of maintainability and scalability. To address these issues, we need to explore an alternative approach: leveraging the native unmarshaling capabilities provided by the DynamoDB driver. I've placed all the code and tests I'll be discussing in a separate repository, which you're welcome to explore and run locally if needed.
Automatic Unmarshaling
Before we start, we need to understand how data is stored in DynamoDB. DynamoDB supports several data types with corresponding abbreviations:
- S -- String
- N -- Number
- B -- Binary
- BOOL -- Boolean
- NULL -- Null
- M -- Map
- L -- List
- SS -- String Set
- NS -- Number Set
- BS -- Binary Set
\ You can see the storage format of these data types through the web interface.
\
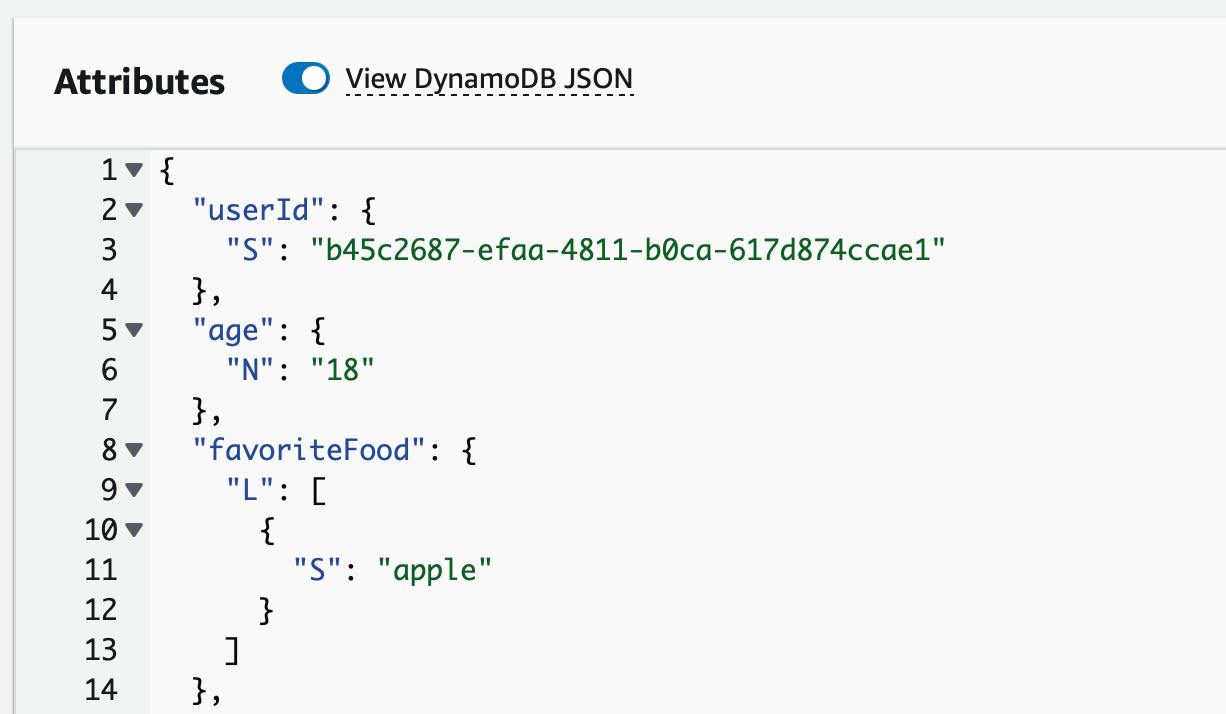
Note that stored and actual data types can also differ, which must be considered in the code. For instance, the field age in a picture has an N type but it's representation is a string.
\
The DynamoDB driver uses a universal type that he returns when we requesting data - AttributeValue. Each data retrieval response contains a map of fields and their values in the AttributeValue format.
\
type AttributeValue interface {
isAttributeValue()
}
type GetItemOutput struct {
Item map[string]types.AttributeValue
}
\
This means that when deserializing the value of each field, its value will be represented by one of the types that implements AttributeValue interface. In DynamoDB, each of these types has different underlying structure and implements the common interface.
\
// An attribute of type String. For example: "S": "Hello"
type AttributeValueMemberS struct {
Value string
}
func (*AttributeValueMemberS) isAttributeValue() {}
// An attribute of type Map. For example: "M": {"Name": {"S": "Joe"}, "Age": {"N": "35"}}
type AttributeValueMemberM struct {
Value map[string]AttributeValue
}
func (*AttributeValueMemberM) isAttributeValue() {}
\ Also, as you can see, there is no other way to determine the type of the returned object since the driver always returns a map of interfaces. This is where the DynamoDB driver's built-in unmarshaling interfaces come into play.
\
The DynamoDB driver provides a Unmarshaler interface that allows for custom handling of attribute values when deserializing data:
\
type Unmarshaler interface {
UnmarshalDynamoDBAttributeValue(types.AttributeValue) error
}
\
By implementing the Unmarshaler interface, you can define how each attribute value should be processed. This approach requires the use of type checking to handle different attribute types appropriately.
\
There are two ways to implement Unmarshaler:
- Adding custom field types
- Implementing it for the entire structure
Custom Field Type Unmarshaling
In the first approach, we can add a method to decode a specific type for a particular field in the target structure, where we know there are multiple source types. For example, for a slice of strings, we can create an alias AgnosticSlice:
\
type UserDataAgnosticSlice struct {
ID string `json:"id" dynamodbav:"id"`
FavoriteFood AgnosticSlice `json:"favorite_food" dynamodbav:"favorite_food"`
}
type AgnosticSlice []string
func (a *AgnosticSlice) UnmarshalDynamoDBAttributeValue(av types.AttributeValue) error {
// implementation
}
\
Thus, when the driver unmarshals a field with the type AgnosticSlice, it will use the method we implemented for its unmarshaling.
In the second approach, we can implement unmarshaling for the entire type:
\
type UserDataAgnosticType struct {
ID string `json:"id" dynamodbav:"id"`
FavoriteFood []string `json:"favorite_food" dynamodbav:"favorite_food"`
}
func (a *UserDataAgnosticType) UnmarshalDynamoDBAttributeValue(av types.AttributeValue) error {
// implementation
}
\ Although both approaches are possible, the second one seems more elegant in terms of separating mapping logic and business logic. However, it is also much more complex to implement. In the first case, we only need to map the value, while in the second, we also need to know the key for this value since we need to return the entire object. In cases where types vary only for a few fields or fields of a certain type, implementing unmarshaling for the entire object is not practical.
\
Let's start with value mapping by implementing the Unmarshaler interface for a string slice alias. Since the AttributeValue type does not provide any way to determine the underlying type, being an interface with only one method, we will have to use type casting and checking for each possible variant. When we receive an AttributeValue, we can use a type switch and, once the underlying type is determined, know how to handle it.
\
func (a *AgnosticSlice) UnmarshalDynamoDBAttributeValue(av types.AttributeValue) error {
switch avTyped := av.(type) {
case *types.AttributeValueMemberSS:
*a = avTyped.Value
return nil
case *types.AttributeValueMemberS:
*a = []string{avTyped.Value}
return nil
case *types.AttributeValueMemberL:
// implementation
return nil
default:
return fmt.Errorf("unsupported type of unmarshal value %v, type %T", av, av)
}
}
\
For example, for the SS type, which is a string array in DynamoDB, we can simply return the underlying Value type as it is already a []string. However, for some types, we will need to handle unusual value formats. For instance, if we receive an untyped JSON list ([]any) and save it in DynamoDB, it will be stored as an untyped list of type L. This format might not make sense from a business logic perspective, but some fields may have been added with this type historically—since we don't have a schema, we can't know for sure. In such cases, we will need to handle the AttributeValueMemberL as an array of objects of various types and convert them to the target type.
\
// untyped json list - {"apple", "banana", 42}
case *types.AttributeValueMemberL:
casted := make([]string, 0)
for _, dynamoValue := range avTyped.Value {
if castedValue, ok := dynamoValue.(*types.AttributeValueMemberS); ok {
casted = append(casted, castedValue.Value)
}
}
*a = casted
return nil
\ The main drawback of this approach is that it introduces custom types, which will still need to be converted to the underlying type in DTOs to avoid spreading unmarshaling logic across other packages. Thus, this approach does not eliminate the need for a mapping layer but introduces more universal structures that could be used in manual mapping within a regular mapping layer.
Custom Struct Unmarshaling
So, what if we implement the Unmarshaler interface by the encapsulating structure? It will potentially allow us to avoid knowing anything about custom types. Let's try. But here is the catch - to do it, we will need to match the field names of the DynamoDB object fields with the fields in our struct. We could use the field name in the structure, but although this is easier, it has a number of problems, potentially making it harder to maintain.
\
Firstly, naming conventions in Go and DynamoDB can differ depending on projects, and this approach will not be universal. Secondly, it contradicts the approach of naming fields for the DynamoDB driver—using string tags. Since developers who have worked with this database before will expect the standard way of specifying field names to work, it is more appropriate to implement support for dynamodbav tags, even though it will be a bit more labor-intensive.
\
To get a list of fields and their tags in Go, we need to use reflection. Then, for each field, we can get the tag using the built-in method Tag.Get('tag_name').
\
visibleFields := reflect.VisibleFields(reflect.TypeOf(parsed))
...
tag := visibleField.Tag.Get("dynamodbav")
\
The final algorithm will look as follows: for each field in our target structure, for its dynamodbav tag, we need to find the value in the map of strings to AttributeValue and parse it according to the type of this field in the target structure.
\
type TargetType struct {
ID string `json:"id" dynamodbav:"id"`
FavoriteFood []string `json:"favorite_food" dynamodbav:"favorite_food"`
}
func (a *TargetType) UnmarshalDynamoDBAttributeValue(av types.AttributeValue) error {
var parsed TargetType
dynamoMap := av.(*types.AttributeValueMemberM)
visibleFields := reflect.VisibleFields(reflect.TypeOf(parsed))
for _, field := range visibleFields {
tag := field.Tag.Get("dynamodbav")
dbValue := dynamoMap.Value[tag]
// parse the value from the db depending on the target dto type
fields := reflect.ValueOf(&parsed).Elem()
switch field.Type.Kind() {
case reflect.String:
if s, ok := dbValue.(*types.AttributeValueMemberS); ok {
fields.FieldByName(field.Name).SetString(s.Value)
}
case reflect.Slice:
// parse dbValue into slice
...
fields.FieldByName(field.Name).Set(reflect.ValueOf(result))
default:
return fmt.Errorf("unsupported field '%v' type", field)
}
}
*a = parsed
return nil
}
\
If your data contains many fields with floating types in DynamoDB, this Unmarshaler is the most universal. Once written and extracted into a function, it can be used on any structure with completely different fields and types. On the other hand, using reflection in this code reduces its performance. If performance is a higher priority for your application, it might be more efficient to use the mappers from the previous approach.
Pros and Cons
The main advantage of this approach is its maintainability. When extending the code structure, one does not need to know the nuances of possible types of objects represented in the database. Structures are easily extendable, and the unmarshaling code is very reusable for similar cases in other entities. The code does not leak details of its implementation. However, a potential downside is performance degradation in structures containing a large number of fields. Since this approach makes use of reflection, which is slower than type casting, it can become noticeable in complex structures.
Conclusion
In this article, we explored two main approaches to handling type inconsistencies in DynamoDB using Go. The first approach, custom field type unmarshaling, is simpler but may lead to the spread of unmarshaling logic across different packages. The second approach, custom struct unmarshaling, is more maintainable but can be less performant due to the use of reflection. Depending on your specific needs and constraints, you can choose the approach that best suits your project.
This content originally appeared on HackerNoon and was authored by Konstantin Telnoi
Konstantin Telnoi | Sciencx (2024-10-08T09:25:26+00:00) GoLang Guide: Automating Data Consistency in DynamoDB. Retrieved from https://www.scien.cx/2024/10/08/golang-guide-automating-data-consistency-in-dynamodb/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.