
This content originally appeared on HackerNoon and was authored by Auto Encoder: How to Ignore the Signal Noise
:::info Authors:
(1) Liang Wang, Microsoft Corporation, and Correspondence to (wangliang@microsoft.com);
(2) Nan Yang, Microsoft Corporation, and correspondence to (nanya@microsoft.com);
(3) Xiaolong Huang, Microsoft Corporation;
(4) Linjun Yang, Microsoft Corporation;
(5) Rangan Majumder, Microsoft Corporation;
(6) Furu Wei, Microsoft Corporation and Correspondence to (fuwei@microsoft.com).
:::
Table of Links
3 Method
4 Experiments
4.1 Statistics of the Synthetic Data
4.2 Model Fine-tuning and Evaluation
5 Analysis
5.1 Is Contrastive Pre-training Necessary?
5.2 Extending to Long Text Embeddings and 5.3 Analysis of Training Hyperparameters
B Test Set Contamination Analysis
C Prompts for Synthetic Data Generation
D Instructions for Training and Evaluation
5 Analysis
5.1 Is Contrastive Pre-training Necessary?
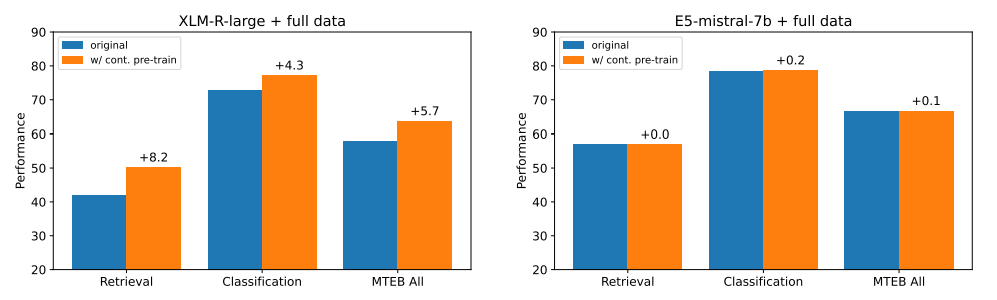
\ Weakly-supervised contrastive pre-training is one of the key factors behind the success of existing text embedding models. For instance, Contriever [18] treats random cropped spans as positive pairs for pre-training, while E5 [46] and BGE [48] collect and filter text pairs from various sources.
\

\
:::info This paper is available on arxiv under CC0 1.0 DEED license.
:::
\
This content originally appeared on HackerNoon and was authored by Auto Encoder: How to Ignore the Signal Noise
Auto Encoder: How to Ignore the Signal Noise | Sciencx (2024-10-09T19:00:17+00:00) Improving Text Embeddings with Large Language Models: Is Contrastive Pre-training Necessary?. Retrieved from https://www.scien.cx/2024/10/09/improving-text-embeddings-withlarge-language-models-is-contrastive-pre-training-necessary/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.