
This content originally appeared on HackerNoon and was authored by Anchoring
:::info Authors:
(1) Jianhui Pang, from the University of Macau, and work was done when Jianhui Pang and Fanghua Ye were interning at Tencent AI Lab (nlp2ct.pangjh3@gmail.com);
(2) Fanghua Ye, University College London, and work was done when Jianhui Pang and Fanghua Ye were interning at Tencent AI Lab (fanghua.ye.19@ucl.ac.uk);
(3) Derek F. Wong, University of Macau;
(4) Longyue Wang, Tencent AI Lab, and corresponding author.
:::
Table of Links
3 Anchor-based Large Language Models
3.2 Anchor-based Self-Attention Networks
4 Experiments and 4.1 Our Implementation
4.2 Data and Training Procedure
7 Conclusion, Limitations, Ethics Statement, and References
6 Analysis
To further elucidate our method’s insights, we conduct a natural language generation experiment with the German-to-English (De2En) translation task. We evaluate the models using COMET-DA (Rei et al., 2022), indicating translation quality, and the Keys/Values Cache Reduction C⇓ metric, denoting memory efficiency as previously described. In line with previous findings, AnLLMs accept a minor accuracy trade-off (about 3 COMET-DA points) for enhanced memory efficiency. All LLMs are finetuned on the Alpaca dataset, combined with the newstest2017-2020 datasets, following Jiao et al. (2023). Results are presented in Table 2.
6.1 Compatibility and Flexibility of Full Attention and Anchor-based Attention
The results offer significant insight into the interplay between anchor-based attention and full attention mechanisms in the De2En translation task. Since source sentences are vital in translation tasks, applying full attention to them is crucial for maintaining model performance. Thus, retaining the source sentence keys/values caches is expected to enhance AnLLM performance when implementing the AnSAN technique. Specifically, when combining full attention with the AnSAN method, both AnLLM-EP and AnLLM-AC achieve approximately 80.0 COMET-DAE scores, comparable to other models using full attention exclusively. This indicates that the AnSAN technique is compatible with the full attention mechanism. Consequently, our proposed models allow users to choose between full attention and anchor-based attention for input texts based on their needs, emphasizing the compatibility and flexibility of our models.
6.2 Effective Cache Reduction for Real-Time Inference with the AnSAN Technique
The results in Table 2 show that our reduction strategy effectively minimizes keys/values caches during real-time inference. In Specific, as indicated in Line 15 of Algorithm 1, when generating an anchor token (i.e., the endpoint or tokens),
\
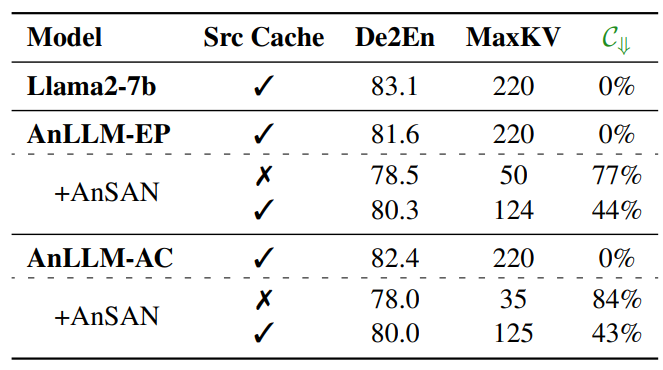
\ our AnSAN-equipped models execute the reduction function to minimize the current keys/values caches. When discarding source sentence caches, we achieve approximately 77% and 84% reduction for the AnLLM-EP and AnLLM-AC models, respectively, albeit with a low COMET-DA score. However, when retaining source sentence caches, we still reduce around 44% of caches for both models, achieving a COMET-DA score of approximately 80.0. These results confirm the effectiveness of our anchor-based inference strategy for practical real-time inference applications.
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\
This content originally appeared on HackerNoon and was authored by Anchoring
Anchoring | Sciencx (2024-10-11T12:00:20+00:00) Anchor-based Large Language Models: Analysis. Retrieved from https://www.scien.cx/2024/10/11/anchor-based-large-language-models-analysis/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.