
This content originally appeared on HackerNoon and was authored by Benchmarking in Business Technology and Software
:::info Authors:
(1) Qian Yang, Zhejiang University, Equal contribution. This work was conducted during Qian Yang’s internship at Alibaba Group;
(2) Jin Xu, Alibaba Group, Equal contribution;
(3) Wenrui Liu, Zhejiang University;
(4) Yunfei Chu, Alibaba Group;
(5) Xiaohuan Zhou, Alibaba Group;
(6) Yichong Leng, Alibaba Group;
(7) Yuanjun Lv, Alibaba Group;
(8) Zhou Zhao, Alibaba Group and Corresponding to Zhou Zhao (zhaozhou@zju.edu.cn);
(9) Yichong Leng, Zhejiang University
(10) Chang Zhou, Alibaba Group and Corresponding to Chang Zhou (ericzhou.zc@alibaba-inc.com);
(11) Jingren Zhou, Alibaba Group.
:::
Table of Links
4 Experiments
4.3 Human Evaluation and 4.4 Ablation Study of Positional Bias
A Detailed Results of Foundation Benchmark
3.4 Evaluation Strategy
In this paper, we leverage a unified evaluation method, as shown in Fig. 3, by viewing both the single-choice question in the foundation benchmark, and the open-ended question in the chat benchmark, as the generation tasks for the purpose of better alignment with actual use case scenarios of LALMs. That is, given audio and questions, LALMs are required to directly generate the answers as hypotheses, rather than comparing the perplexity on the probability of different reference answers via teacher forcing. Automated and accurate evaluation of open-ended generation is a challenging problem. Traditional automatic metrics such as WER, ROUGE (Lin, 2004), METEOR (Banerjee and Lavie, 2005) have been shown low correlation with human judgements (Liu et al., 2023a). Recently, LLM-based evaluation, such as GPT-4,
\
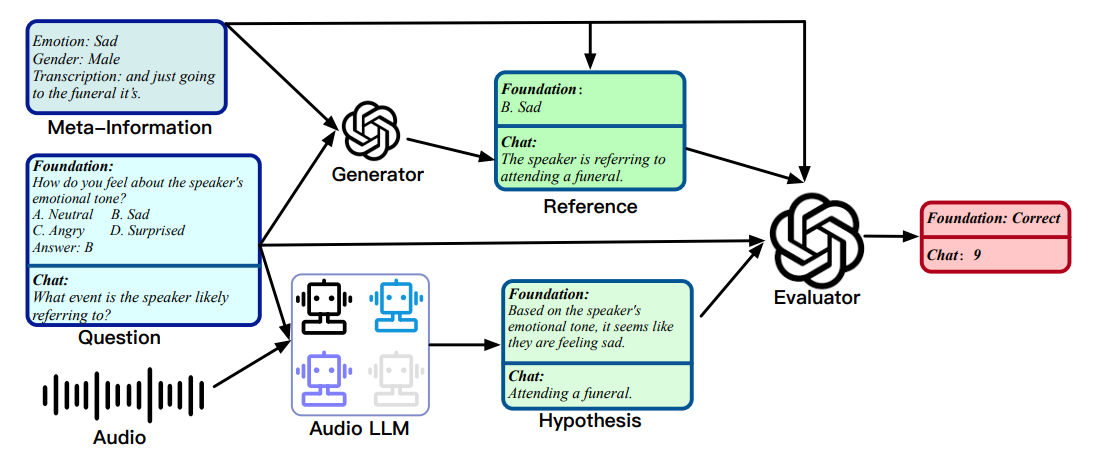
\ shows better human preference alignment (Zheng et al., 2023; Liu et al., 2023a). In this work, we adopt reference-based GPT-4 evaluators to judge the generation quality of LALMs in the audio domain.
\ However, GPT-4 cannot be directly used as an evaluator since it cannot receive audio inputs. To address this limitation, we offer the GPT-4 model rich meta-information of audio to replace audio input. Subsequently, we present questions and employ GPT-4 to evaluate the hypotheses produced by LALMs. To ensure consistency and fairness for evaluation, each model’s answer is compared against the same reference answer for scoring. For the foundation benchmark, the reference answer is the golden choice, and we prompt the evaluator to determine whether the hypothesis is correct or not. For the chat benchmark, the reference answer is generated by GPT-4, and we prompt the evaluator to provide a score ranging from 1 to 10, based on the assessment of usefulness, relevance, accuracy, and comprehensiveness of the hypothesis. Note that for the chat benchmark, the role of the reference is not to serve as the ground truth answer, but rather as a reference for scoring by GPT-4, in order to stabilize its scoring. Additionally, to mitigate any potential position bias resulting from the order of hypothesis and reference, following Bai et al.
\ (2023b), we perform a second scoring round by swapping their positions and then compute the average of the two scores. Unless otherwise specified, the GPT-4 evaluator is GPT-4 Turbo, the gpt-4- 0125-preview version [2].
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
[2] https://platform.openai.com/docs/models/gpt-4-and-gpt4-turbo
This content originally appeared on HackerNoon and was authored by Benchmarking in Business Technology and Software
Benchmarking in Business Technology and Software | Sciencx (2024-10-16T15:13:03+00:00) Unified Evaluation Method for LALMs Using GPT-4 in Audio Tasks. Retrieved from https://www.scien.cx/2024/10/16/unified-evaluation-method-for-lalms-using-gpt-4-in-audio-tasks/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.