
This content originally appeared on HackerNoon and was authored by Quantization
:::info Authors:
(1) Divyanshu Kumar, Enkrypt AI;
(2) Anurakt Kumar, Enkrypt AI;
(3) Sahil Agarwa, Enkrypt AI;
(4) Prashanth Harshangi, Enkrypt AI.
:::
Table of Links
2 Problem Formulation and Experiments
3 EXPERIMENT SET-UP & RESULTS
The following section outlines the testing environments utilized for various LLMs. The LLMs are tested under three different downstream tasks: (1) fine-tuning, (2) quantization, and (3) guardrails. They are chosen to cover most of the LLM practical use cases and applications in the industry and academia. For TAP configuration, as mentioned before, we use GPT-3.5-turbo as the attack model, and GPT-4-turbo as the judge model. We employ Anyscale endpoints, the OpenAI API, and HuggingFace for our target model. Further information regarding the model and its sources is available in appendix A.1. The details about different settings are mentioned below :
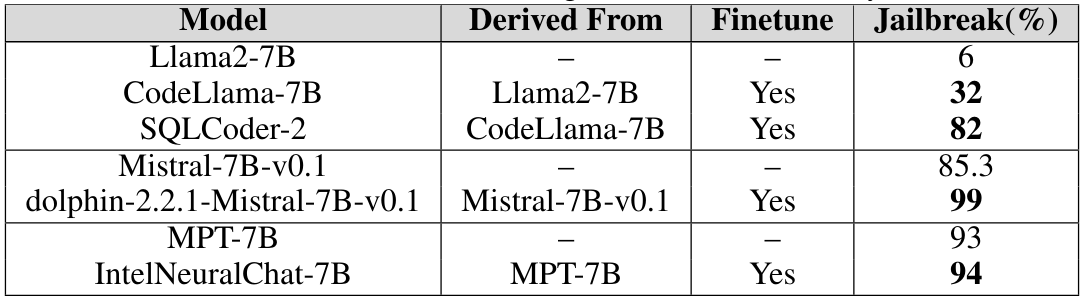
\ • Fine-tuning: Fine-tuning LLMs on different tasks increases their effectiveness in completing the tasks as it incorporates the specialized domain knowledge needed; these can include SQL code generation, chat, and more. We compare the jailbreaking vulnerability of foundational models compared to their fine tune versions. This helps us understand the role of fine-tuning in increasing or decreasing the vulnerability of LLMs and the strategies to mitigate this risk Weyssow et al. (2023). We use foundation models such as Llama2, Mistral, and MPT-7B and their fine-tuned versions such as CodeLlama, SQLCoder, Dolphin, and Intel Neural Chat. The details of the models and versions are specified in the appendix. From the table 1, we empirically conclude that fine-tuned models lose their safety alignment and are jailbroken quite easily compared to the foundational models.
\
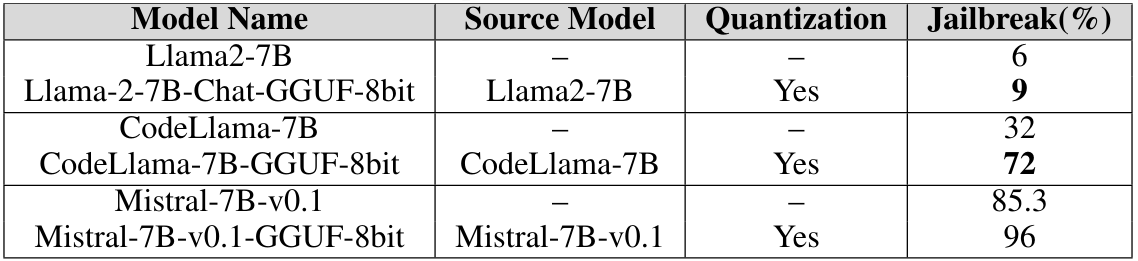
\ • Quantization: Many models require huge computational resources during training, finetuning, and even during inference Hu et al. (2021). Quantization is one of the most popular ways to reduce the computational burden, but it comes at the cost of the numerical precision of model parameters. The quantized models we evaluate below use GPT-Generated Unified Format (GGUF) for quantization, which involves scaling down model weights (stored in 16-bit floating point numbers) to save computational resources at the cost of numerical precision of the model parameters. Kashiwamura et al. (2024) Gorsline et al. (2021) Xiao et al.(2023) Hu et al. (2021) Dettmers et al. (2023). The table 2 demonstrates that quantization of the model renders it susceptible to vulnerabilities.
\
\ • Guardrails: Guardrails act as a line of defence against LLM attacks. Their primary function is to meticulously filter out prompts that could potentially lead to harmful or malicious outcomes, preventing such prompts from reaching the LLM as an instruction Rebedea et al. (2023). This proactive approach not only promotes the safe utilization of LLMs but also facilitates their optimal performance, thereby maximizing their potential benefits in various domains Kumar et al. (2023) Wei et al. (2023) Zhou et al. (2024). We use our proprietary jailbreak attack detector derived from Deberta-V3 models, trained on harmful prompts generated to jailbreak LLMs. You can reach out to the authors to get more details on this model. From table 3, we observe that the introduction of guardrails as a pre-step has a significant effect and can mitigate jailbreaking attempts by a considerable margin.
\
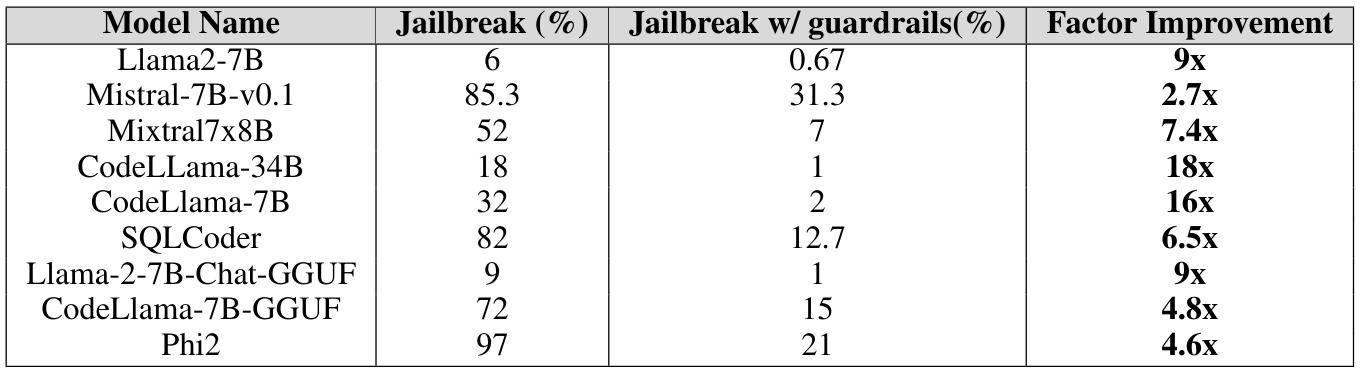
\ The results from tables 1, 2, and 3 conclusively show the vulnerability of LLMs post fine-tuning and quantization, and effectiveness of external guardrails in mitigating this vulnerability. The detailed experimental results can be found in appendix A.2. Additionally, this section provides a comprehensive analysis of the experiments conducted, offering insights into the various aspects of the research findings.
\
:::info This paper is available on arxiv under CC BY-NC-SA 4.0 DEED license.
:::
\
This content originally appeared on HackerNoon and was authored by Quantization
Quantization | Sciencx (2024-10-17T14:00:18+00:00) Increased LLM Vulnerabilities from Fine-tuning and Quantization: Experiment Set-up & Results. Retrieved from https://www.scien.cx/2024/10/17/increased-llm-vulnerabilities-from-fine-tuning-and-quantization-experiment-set-up-results/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.