
This content originally appeared on HackerNoon and was authored by Writings, Papers and Blogs on Text Models
Table of Links
2 Architectural details and 2.1 Sparse Mixture of Experts
3.1 Multilingual benchmarks, 3.2 Long range performance, and 3.3 Bias Benchmarks
6 Conclusion, Acknowledgements, and References
3.1 Multilingual benchmarks
Compared to Mistral 7B, we significantly upsample the proportion of multilingual data during pretraining. The extra capacity allows Mixtral to perform well on multilingual benchmarks while maintaining a high accuracy in English. In particular, Mixtral significantly outperforms Llama 2 70B in French, German, Spanish, and Italian, as shown in Table 4.
\

3.2 Long range performance
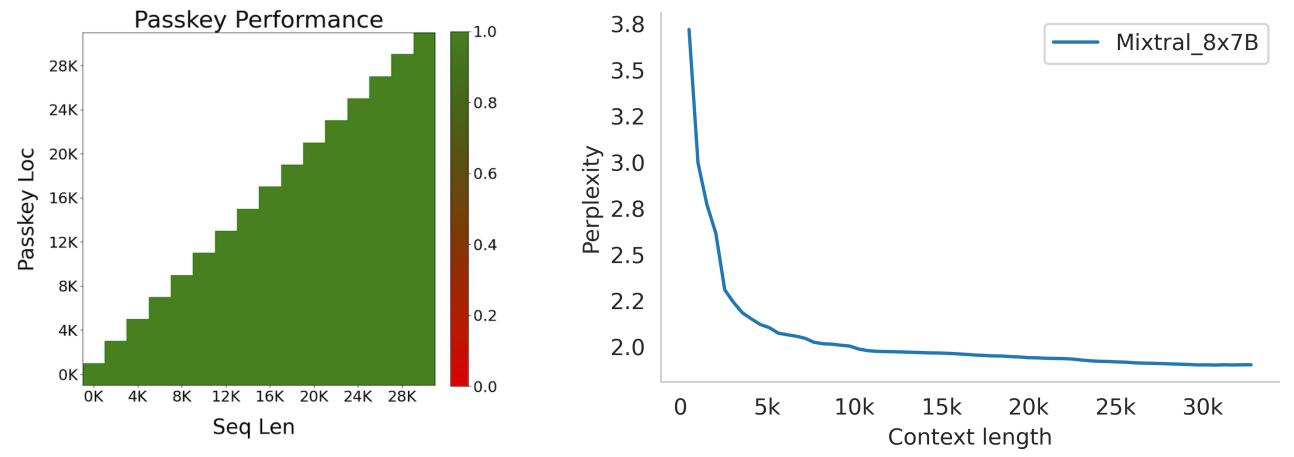
To assess the capabilities of Mixtral to tackle long context, we evaluate it on the passkey retrieval task introduced in [23], a synthetic task designed to measure the ability of the model to retrieve a passkey inserted randomly in a long prompt. Results in Figure 4 (Left) show that Mixtral achieves a 100% retrieval accuracy regardless of the context length or the position of passkey in the sequence. Figure 4 (Right) shows that the perplexity of Mixtral on a subset of the proof-pile dataset [2] decreases monotonically as the size of the context increases.
\
3.3 Bias Benchmarks
To identify possible flaws to be corrected by fine-tuning / preference modeling, we measure the base model performance on Bias Benchmark for QA (BBQ) [24] and Bias in Open-Ended Language Generation Dataset (BOLD) [10]. BBQ is a dataset of hand-written question sets that target attested social biases against nine different socially-relevant categories: age, disability status, gender identity, nationality, physical appearance, race/ethnicity, religion, socio-economic status, sexual orientation. BOLD is a large-scale dataset that consists of 23,679 English text generation prompts for bias benchmarking across five domains.
\
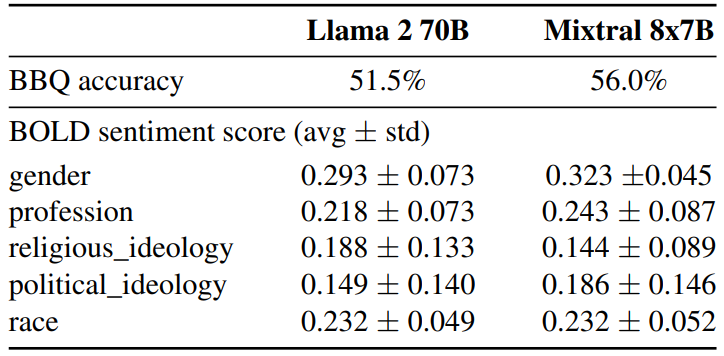
\ We benchmark Llama 2 and Mixtral on BBQ and BOLD with our evaluation framework and report the results in Table 5. Compared to Llama 2, Mixtral presents less bias on the BBQ benchmark (56.0% vs 51.5%). For each group in BOLD, a higher average sentiment score means more positive sentiments and a lower standard deviation indicates less bias within the group. Overall, Mixtral displays more positive sentiments than Llama 2, with similar variances within each group.
\
:::info This paper is available on arxiv under CC 4.0 license.
:::
:::info Authors:
(1) Albert Q. Jiang;
(2) Alexandre Sablayrolles;
(3) Antoine Roux;
(4) Arthur Mensch;
(5) Blanche Savary;
(6) Chris Bamford;
(7) Devendra Singh Chaplot;
(8) Diego de las Casas;
(9) Emma Bou Hanna;
(10) Florian Bressand;
(11) Gianna Lengyel;
(12) Guillaume Bour;
(13) Guillaume Lample;
(14) Lélio Renard Lavaud;
(15) Lucile Saulnier;
(16) Marie-Anne Lachaux;
(17) Pierre Stock;
(18) Sandeep Subramanian;
(19) Sophia Yang;
(20) Szymon Antoniak;
(21) Teven Le Scao;
(22) Théophile Gervet;
(23) Thibaut Lavril;
(24) Thomas Wang;
(25) Timothée Lacroix;
(26) William El Sayed.
:::
\
This content originally appeared on HackerNoon and was authored by Writings, Papers and Blogs on Text Models
Writings, Papers and Blogs on Text Models | Sciencx (2024-10-18T15:50:47+00:00) Mixtral’s Multilingual Benchmarks, Long Range Performance, and Bias Benchmarks. Retrieved from https://www.scien.cx/2024/10/18/mixtrals-multilingual-benchmarks-long-range-performance-and-bias-benchmarks/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.