
This content originally appeared on HackerNoon and was authored by Bright Data
Your web scraper got blocked again? Ugh, what now? You nailed those HTTP headers and made it look just like a browser, but the site still figured out your requests were automated. How’s that even possible? Simple: it’s your TLS fingerprint! 😲
\ Dive into the sneaky world of TLS fingerprinting, uncover why it’s the silent killer behind most blocks, and learn you how to get around it.
Anti-Bot Blocked You Again? Time to Learn Why!
Let’s assume you’re dealing with a typical scraping scenario. You're making an automated request using an HTTP client—like Requests in Python or Axios in JavaScript—to fetch the HTML of a web page to scrape some data from it.
\ As you probably already know, most websites have bot protection technologies in place. Curious about the best anti-scraping tech? Check our guide on the best anti-scraping solutions! 🔐
\ These tools monitor incoming requests, filtering out the suspicious ones.
\

\ If your request looks like it’s coming from a regular human, you're good to go. Otherwise? It’s going to get stonewalled! 🧱
Browser Requests vs Bot Requests
Now, what does a request from a regular user look like? Easy! Just fire your browser's DevTools, head to the Network tab, and see for yourself:
\
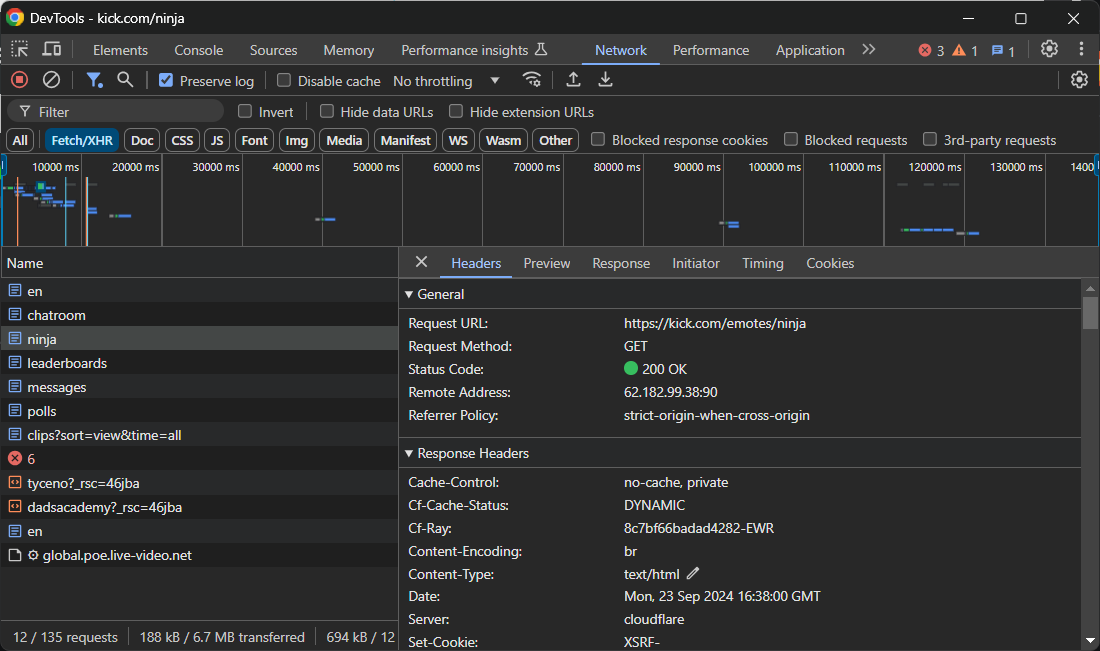
\ If you copy that request to cURL by selecting the option from the right-click menu, you'll get something like this:
curl 'https://kick.com/emotes/ninja' \
-H 'accept: application/json' \
-H 'accept-language: en-US,en;q=0.9' \
-H 'cache-control: max-age=0' \
-H 'cluster: v1' \
-H 'priority: u=1, i' \
-H 'referer: https://kick.com/ninja' \
-H 'sec-ch-ua: "Google Chrome";v="129", "Not=A?Brand";v="8", "Chromium";v="129"' \
-H 'sec-ch-ua-mobile: ?0' \
-H 'sec-ch-ua-platform: "Windows"' \
-H 'sec-fetch-dest: empty' \
-H 'sec-fetch-mode: cors' \
-H 'sec-fetch-site: same-origin' \
-H 'user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36'
If this syntax looks like Chinese to you, no worries—check out our introduction to cURL. 📖
\
Basically, a “human” request is just a regular HTTP request with some extra headers (the -H flags). Anti-bot systems inspect those headers to figure out if a request is coming from a bot or a legit user in a browser.
\ One of their biggest red flags? The User-Agent header! Explore our post on the best user agents for web scraping. That header is automatically set by HTTP clients but never quite matches the ones used by real browsers.
\ Mismatch in those headers? It’s a dead giveaway for bots! 💀
\ For more information, dive into our guide on HTTP headers for web scraping.
Setting HTTP Headers Isn’t Always the Solution
Now, you might be thinking: “Easy fix, I’ll just perform automated requests with those headers!” But hold on a sec… 🚨
\ Go ahead and run that cURL request you copied from DevTools:
\
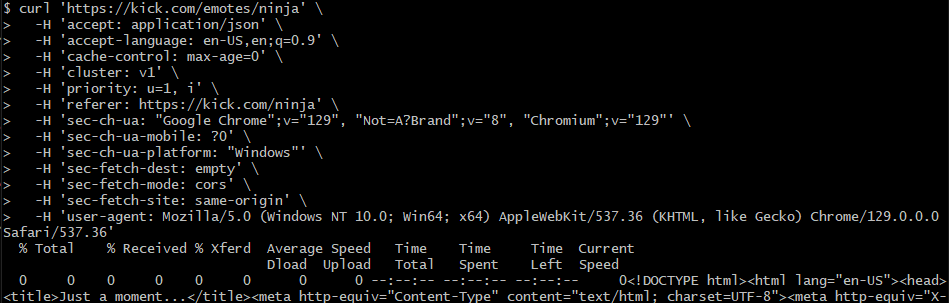
\ Surprise! The server hit you back with a “403 Access Denied” page from Cloudflare. Yep, even with the browser-like headers, you can still get blocked!
\ Cracking Cloudflare isn’t that easy, after all. 😅
\ But wait, how?! Isn’t that the exact same request a browser would make? 🤔 Well, not quite…
The Key Lies in the OSI Model
On the application level of the OSI Model, the browser and cURL requests are the same. Yet, there are all underlying layers you might be overlooking. 🫠
\
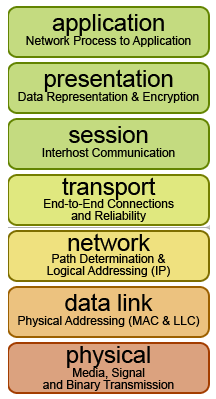
\ Some of these layers are often the culprits behind those pesky blocks, and information transferred there is exactly what advanced anti-scraping technologies focus on. Sly sneaky beasts! 👹
\ For instance, they look at your IP address, which is pulled from the Network layer. Want to dodge those IP bans? Follow our tutorial on how to avoid an IP ban with proxies!
\ Unfortunately, that’s not all! 😩
\ Anti-bot systems also pay close attention to the TLS fingerprint from the secure communication channel established between your script and the target web server at the Transport Layer.
\ That’s where things differ between a browser and an automated HTTP request! Cool, right? But now you must be wondering what that entails… 🔍
What’s a TLS Fingerprint?
A TLS fingerprint is a unique identifier that anti-bot solutions create when your browser or HTTP client sets up a secure connection to a website.
\
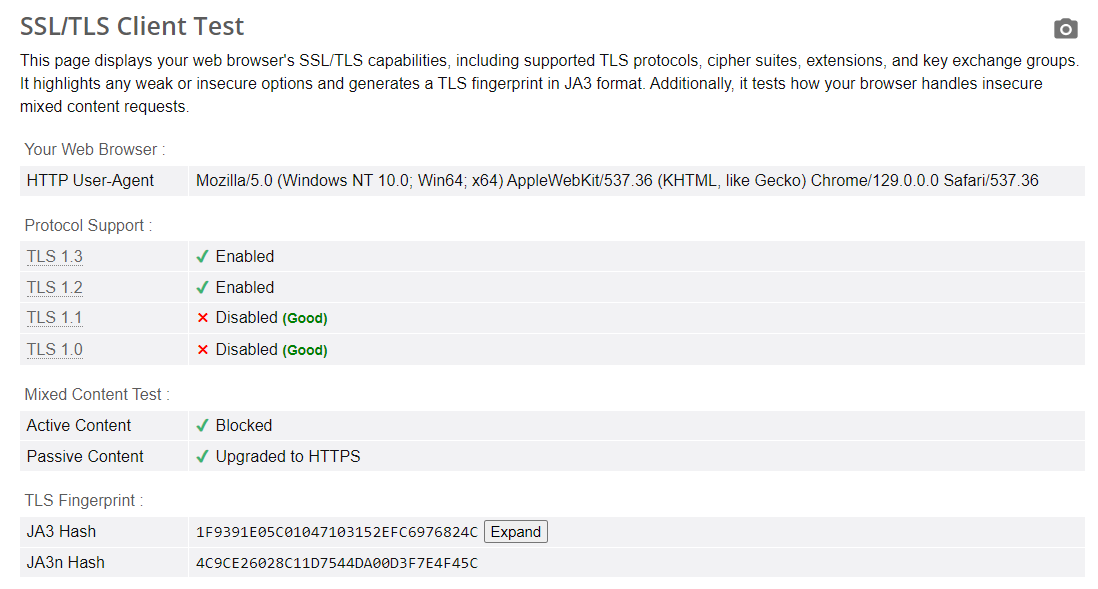
\ It’s like a digital signature your machine leaves behind during the TLS handshake—the initial “conversation” between a client and the web server to decide how they’ll encrypt and secure data at the Transport layer. 🤝
\ When you make an HTTP request to a site, the underlying TLS library in your browser or HTTP client kicks off the handshake procedure. The two parties, the client and the server, start asking each other things like, “What encryption protocols do you support?” and “Which ciphers should we use?” ❓
\
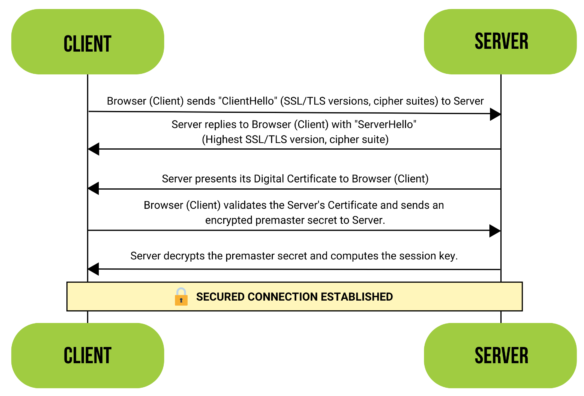
\ Based on your answers, the server can tell if you’re a regular user in a browser or an automated script using an HTTP client. In other words, if your answers don’t match those of typical browsers, you might get blocked.
\ Imagine this handshake like two people meeting:
\ Human version:
Server: "What language do you speak?"
Browser: "English, French, Chinese, and Spanish"
Server: "Great, let’s chat"
\
Bot version:
Server: "What language do you speak?"
Bot: “Meow! 🐈”
Server: “Sorry, but you don’t seem like a human being. Blocked!"
\

\ TLS fingerprinting operates below the Application layer of the OSI model. That means you can’t just tweak your TLS fingerprint with a few lines of code. 🚫 💻 🚫
\ To spoof TLS fingerprints, you need to swap your HTTP client’s TLS configurations with those of a real browser. The catch? Not all HTTP clients let you do this!
\

\ That’s where tools like cURL Impersonate come into play. This special build of cURL is designed to mimic a browser’s TLS settings, helping you simulate a browser from the command line!
Why a Headless Browser May Not Be a Solution Either
Now, you might be thinking: “Well, if HTTP clients give off ‘bot-like’ TLS fingerprints, why not just use a browser for scraping?”
\
\ The idea is to use a browser automation tool to run specific tasks on a webpage with a headless browser.
\ Whether the browser runs in headed or headless mode, it still uses the same underlying TLS libraries. That’s good news because it means headless browsers generate a "human-like" TLS fingerprint! 🎉
\ That’s the solution, right? Not really… 🫤
\

\ Here’s the kicker: headless browsers come with other configurations that scream, “I’m a bot!” 🤖
\ Sure, you could try hiding that with a stealth plugin in Puppeteer Extra, but advanced anti-bot systems can still sniff out headless browsers through JavaScript challenges and browser fingerprinting.
\ So, yeah, headless browsers aren’t your foolproof escape either to anti-bots. 😬
How to Really Bypass TLS Fingerprinting
TLS fingerprint checking is just one of many advanced bot protection tactics that sophisticated anti-scraping solutions implement. 🛡️
\ To truly leave behind the headaches of TLS fingerprinting and other annoying blocks, you need a next-level scraping solution that provides:
Reliable TLS fingerprints
Unlimited scalability
CAPTCHA-solving superpowers
Built-in IP rotation via a 72-million IP proxy network
Automatic retries
JavaScript rendering capabilities
\
Those are some of the many features offered by Bright Data's Scraping Browser API—an all-in-one cloud browser solution to scrape the Web efficiently and effectively.
\ This product integrates seamlessly with your favorite browser automation tools, including Playwright, Selenium, and Puppeteer. ✨
\ Just set up the automation logic, run your script, and let the Scraping Browser API handle the dirty work. Forget about blocks and get back to what matters—scraping at full speed! ⚡️
https://www.youtube.com/watch?v=21Xyi1HMTng&embedable=true
\ Don’t need to interact with the page? Try Bright Data’s Web Unlocker!
Final Thoughts
Now you finally know why working at the application level isn’t enough to avoid all blocks. The TLS library your HTTP client uses plays a big part, too. TLS fingerprinting? No longer a mystery—you’ve cracked it and know how to tackle it.
\ Looking for a way to scrape without hitting blocks? Look no further than Bright Data's suite of tools! Join the mission to make the Internet accessible to all—even via automated HTTP requests. 🌐
\ Until next time, keep surfing the Web with freedom!
This content originally appeared on HackerNoon and was authored by Bright Data
Bright Data | Sciencx (2024-10-18T16:19:15+00:00) The Role of the TLS Fingerprint in Web Scraping. Retrieved from https://www.scien.cx/2024/10/18/the-role-of-the-tls-fingerprint-in-web-scraping/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.