
This content originally appeared on Level Up Coding - Medium and was authored by Muhammad Rifqi Fatchurrahman
Web scraping is a powerful tool for gathering data from the web, and doing it efficiently with a systems language like Rust brings performance benefits, safety guarantees, and fine-grained control. In this article, I’ll walk you through how I scrape content from the One Piece Fandom page using Rust.
Just an intermezzo, why One Piece? I chose One Piece because I’m a huge fan of it. Other than that, I’m also inspired by https://github.com/danielschuster-muc/scrabby by providing a Harry Potter data repository powering up the PotterDB (a Restful API for the wizarding world) with a source from the Harry Potter Fandom page. My goal is to provide the same case but for the One Piece world.
This guide will be useful whether you’re a Rustacean looking to explore web scraping or a fan of One Piece who wants to extract useful data for analysis or personal projects and is curious about how to do it in Rust.
Let’s dive into how to combine Rust’s power with great crates (libraries) to build a web scraper for One Piece fandom pages.

Disclaimer: I am not a senior Rust Developer. Just learning it on my free time. You can check out my other article about how I try Rust for the first time.
Journey to the Center of the Rust
Why Rust for Web Scraping?
Before diving into the implementation, you might wonder: Why use Rust for web scraping?
- Performance: Rust is a systems-level language that can perform tasks much faster than interpreted languages like Python.
- Memory Safety: Rust’s ownership model ensures that you avoid common issues like null pointer dereferences and data races in a multithreaded context.
- Concurrency: Rust provides excellent concurrency models (e.g., async, multithreading), which are crucial when you need to scrape a large number of pages in parallel. But in this article, we’re not yet diving too deep into that.
We’re already used to knowing that when we do a web scraping task, the first thing that comes up in our minds is Python. Let’s give it a chance to explore web scraping tasks using Rust with those benefits in mind.
Tools of the Trade: Prerequisites
Before getting started, you must have Rust installed on your computer. My recommendation is to always follow the official site for the installation guidelines.
After that you will have these on your machine:
- rustup: An installer and version manager for the Rust programming language, enabling easy installation, setting up build targets (e.g. wasm), and management of different toolchains.
- cargo: The official package manager and build tool for Rust.
Next is IDE for coding in Rust. In my case, I am using Visual Studio Code with the rust-analyzer extension which is a free and reliable option. I also used the Dependi extension which will make your life easier by providing a clear and concise view of your Rust project dependencies and the available version.
Tools of the Trade: Rust Crates for Web Scraping
A little bit about crates, quoted from its sites
crates.io serves as a central registry for sharing “crates”, which are packages or libraries written in Rust that you can use to enhance your projects. This repository contains the source code and infrastructure for the crates.io website, including both frontend and backend components.
In our case, we will use these crates mainly:
- scraper: For parsing and querying HTML content.
- reqwest: For making HTTP requests.
- tokio: For concurrency asynchronous programming.
And other crates to support our case (not all of it will be used in this article):
- serde_json: For saving scraped data into structured JSON formats.
- serde: For serialization/deserialization, the core library of serde_json.
- log: For logging.
- env_logger: For powering up the logging.
- thiserror: For a better-typed error.
- strum: For powering up the enum with string.
- strsim: For string similarity metrics.
- clap: For CLI arg helper.
- itertools: For an iterator helper.
Step 1: Setting Up Your Rust Project
Start by creating a new Rust project using cargo:
cargo new one_piece_scraper
cd one_piece_scraper
Next, open the Cargo.toml file to add the required dependencies:
[dependencies]
serde_json = "1.0.128"
env_logger = "0.11.5"
itertools = "0.13.0"
log = "0.4.22"
reqwest = "0.12.8"
tokio = { version = "1.40.0", features = ["full"] }
serde = { version = "1.0.210", features = ["derive"] }
strsim = "0.11.1"
clap = { version = "4.5.20", features = ["derive"] }
scraper = "0.20.0"
strum = { version = "0.26.3", features = ["derive"] }
thiserror = "1.0.64"
Now run cargo build to install the dependencies. You can see there’s a property other than the version used here, named features. That’s right, crates support feature toggles, or we could say it as Optional Dependencies. There are multiple ways how to write it, you can read it on the Rust documentation here.
You could also add the dependency by calling cargo add <crate> for the default feature, and cargo add <crate> -F <feature> to use the desired feature. For instance, I would just call cargo add serde_json log env_logger to add those 3 crates to my project. And call cargo add tokio -F full for using the full feature in tokio crate.
The high-level flow of our Devil Fruit scraper can be written as follows:
- Download the target page with reqwest.
- Parse the HTML document and get data from it using the scraper.
- Print the scraped data to stdout.
Step 2: Inspecting The Target Web Page
In this article, we will scrap the information related to Devil Fruits Type Information, specific to the total fruit information
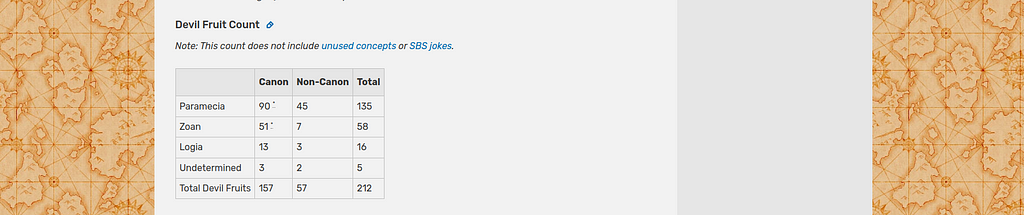
The type itself can be parsed as text, but we will use an enum, since devil fruit types are constant, either Paramecia, Zoan, Logia, or Undetermined.
use strum::{Display, EnumString};
#[derive(Debug, EnumString, PartialEq, Display)]
pub enum DfType {
Logia,
Zoan,
Paramecia,
Undetermined,
}I will not explain about derive and trait here. That is our DfType enum. Ready to be formatted into a string and from a string.
Inspecting The HTML Source
In my opinion, the unique part about the One Piece Fandom page is the HTML structure itself is a bit hard to scrap. Let’s take a look.
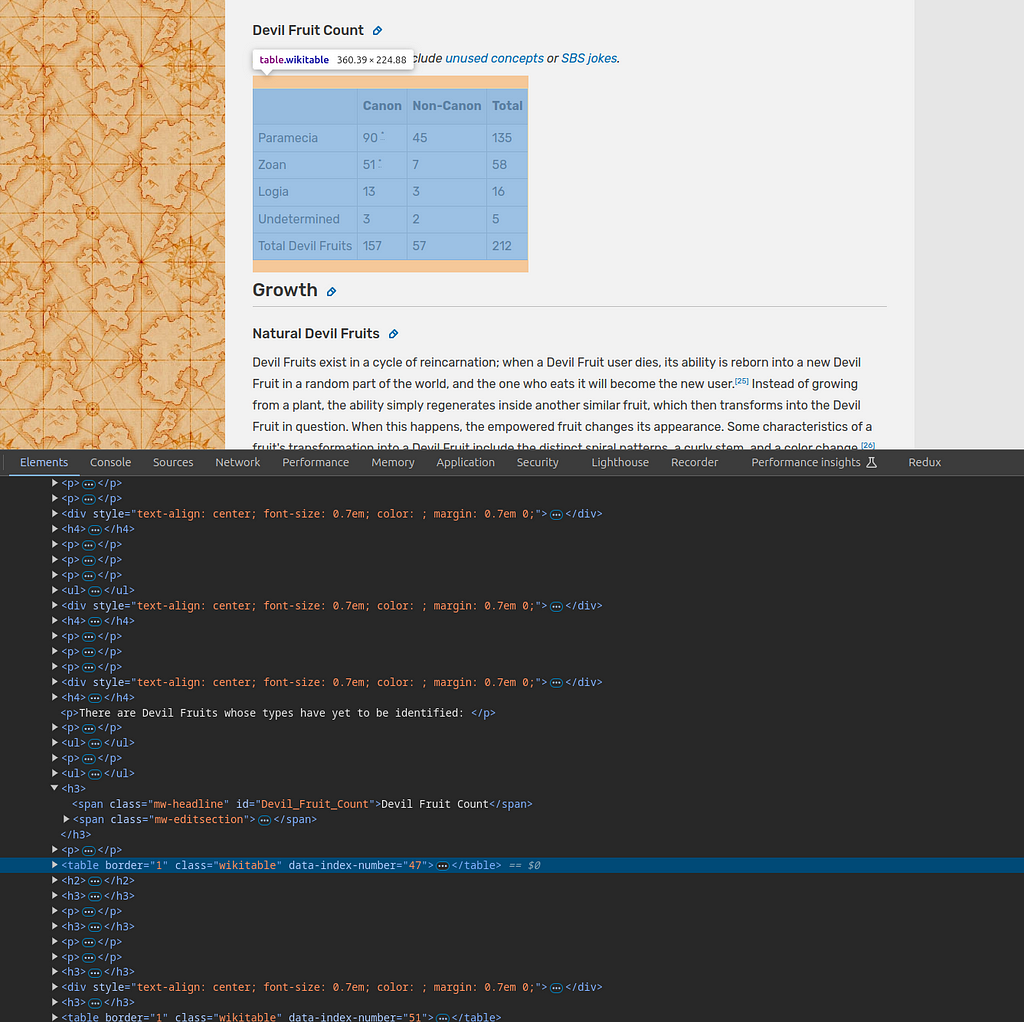
This table is not wrapped at all. Originally I thought it would be inside a div of Devil Fruit Count. But in reality, all contents are flat no matter what section are you in.
There are two ways that I can find to properly select that table. The first one is to find the first table after #Devil_Fruit_Count . Unfortunately, when I tried, the scraper crate failed to get all the siblings after that #Devil_Fruit_Count so that forced us to use the second way. Checking what number that table sits that having this CSS selector table.wikitable , we are only interested in this table and ignore other tables. And after checking on what number this table is in the same root, it is the first table. Now we can write the CSS selector as follows:
table.wikitable:nth-of-type(1)
Next, we will find out how to get the table rows to collect each of the table cell information that we want. We are only interested in getting data related to the enum that we have declared. So we only want the 2nd row until 5th row.
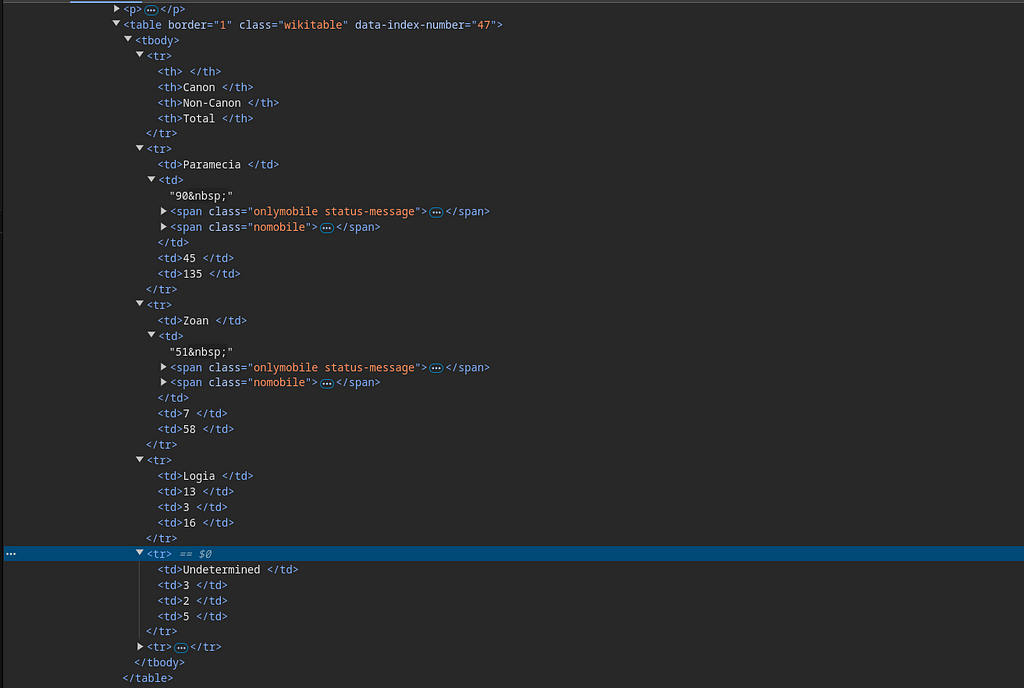
Now we can write the CSS selector as:
table.wikitable:nth-of-type(1) tr:nth-of-type(n+2):nth-of-type(-n+5)
Step 3: Sending HTTP Requests
Let’s first write our Devil Fruit Type Info structure.
use super::df_type::DfType;
use thiserror::Error;
#[derive(Debug)]
pub struct DfTypeInfo {
pub df_type: DfType,
pub cannon_count: u32,
pub non_cannon_count: u32,
pub description: String,
}
impl std::fmt::Display for DfTypeInfo {
fn fmt(&self, f: &mut std::fmt::Formatter) -> std::fmt::Result {
write!(
f,
"(df_type: {}, cannon: {}, non-cannon: {}, description: {})",
self.df_type, self.cannon_count, self.non_cannon_count, self.description
)
}
}
#[derive(Debug, Clone, Error)]
pub enum Error {
#[error("Request error: {0}")]
RequestError(String),
#[error("Invalid html structure: {0}")]
InvalidStructure(String),
}
We are adding the Display implementation on how it is being formatted as a string representation. Here we capture the cannon and non_cannon count. We also add the Error type with the help of thiserror crates.
let response_htm = self
.client
.get(url)
.send()
.await
.map_err(|r| Error::RequestError(r.to_string()))?
.text()
.await
.map_err(|r| Error::RequestError(r.to_string()))?;
This will store the raw HTML from the given UR, where the URL that we are using is the Devil Fruit Page. It will be stored in response_htm as String type. If there’s an error in the process, we already add map_err to map the reqwest’s error type into our error type implementation.
If you’re noticing there’s a question mark in the end. That question mark is used at the end of an expression returning a Result, and is equivalent to a match expression, where the Err(err) branch expands to an early return Err(From::from(err)), and the Ok(ok) branch expands to an ok expression. — cited from the Rust documentation. So we can continue the chain operation as long as the return type where that code resides is a Result with having the same Error type.
Step 4: Parsing HTML with scraper crate
Let’s move on to the Scraper structure first.
pub trait DfScrapable {
async fn get_dftype_info(&self) -> Result<Vec<DfTypeInfo>, Error>;
}
#[derive(Debug)]
pub struct DfScraper {
base_url: String,
client: reqwest::Client,
}
impl DfScraper {
pub fn new(base_url: &str, client: reqwest::Client) -> Self {
Self {
base_url: base_url.to_string(),
client,
}
}
}That is what the Devil Fruit Scraper structure looks like. Having the DfScrapable trait that will be used as the implementation for DfScraper.
Let’s combine what we have written so far into the implementation function.
impl DfScrapable for DfScraper {
async fn get_dftype_info(&self) -> Result<Vec<DfTypeInfo>, Error>{
let url = format!("{}/wiki/Devil_Fruit", self.base_url);
let response_htm = self
.client
.get(url)
.send()
.await
.map_err(|r| Error::RequestError(r.to_string()))?
.text()
.await
.map_err(|r| Error::RequestError(r.to_string()))?;
let doc = Html::parse_document(&response_htm);
let row_selector = &Selector::parse(
"table.wikitable:nth-of-type(1) tr:nth-of-type(n+2):nth-of-type(-n+5)",
)
.unwrap();
}
}Yes, we now have the row_selector ready to be used to select the Devil Fruit Count table’s row elements on the HTML document. We also have created the NodeTree structure based on the HTML response using the Html::parse_document .
Now let’s continue to the actual scrap function. This one will be super specific to the scraper crate features.
let td_selector = &Selector::parse("td").unwrap();
let df_infos: Result<Vec<_>, _> = doc
.select(row_selector)
.map(|row| {
let cells = row.select(td_selector).collect_vec();
let dft = cells[0].text().collect_vec()[0].trim();
let cc = cells[1].text().collect_vec()[0]
.trim()
.parse::<u32>()
.unwrap();
let ncc = cells[2].text().collect_vec()[0]
.trim()
.parse::<u32>()
.unwrap();
let df_type = DfType::from_str(dft).unwrap();
let obj = DfTypeInfo {
df_type,
cannon_count: cc,
non_cannon_count: ncc,
description: String::new(),
};
info!("obj: {}", &obj);
Ok(obj)
})
.collect();By calling select(row_selector) we are making an iterator of ElementRef which in our case is tr element. From there, on each row, we want to get the first, second, and third-column values, extracted as dfType: DfType , cannon_count: u32 , and non_cannon_count: u32. That’s why we are using the map function to map ElementRef of tr into DfTypeInfo.
If you look again closely, inside the td there is a span that we don't care about. That is on the second column, so we only take the first text on each td element for more safety precautions.
let cells = row.select(td_selector).collect_vec();
let dft = cells[0].text().collect_vec()[0].trim();
let cc = cells[1].text().collect_vec()[0]
.trim()
.parse::<u32>()
.unwrap();
let ncc = cells[2].text().collect_vec()[0]
.trim()
.parse::<u32>()
.unwrap();
text() will return a Text which implement Iterator trait. That’s why we can call collect_vec() to collect the iterator as vector Vec. This collect_vec() are part of the ittertools crate, to help us chain more functions like directly accessing the index 0.
Now let’s combine it all.
pub trait DfScrapable {
async fn get_dftype_info(&self) -> Result<Vec<DfTypeInfo>, Error>;
}
#[derive(Debug)]
pub struct DfScraper {
base_url: String,
client: reqwest::Client,
}
impl DfScraper {
pub fn new(base_url: &str, client: reqwest::Client) -> Self {
Self {
base_url: base_url.to_string(),
client,
}
}
}
impl DfScrapable for DfScraper {
async fn get_dftype_info(&self) -> Result<Vec<DfTypeInfo>, Error>{
let url = format!("{}/wiki/Devil_Fruit", self.base_url);
let response_htm = self
.client
.get(url)
.send()
.await
.map_err(|r| Error::RequestError(r.to_string()))?
.text()
.await
.map_err(|r| Error::RequestError(r.to_string()))?;
let doc = Html::parse_document(&response_htm);
let row_selector = &Selector::parse(
"table.wikitable:nth-of-type(1) tr:nth-of-type(n+2):nth-of-type(-n+5)",
)
.unwrap();
let td_selector = &Selector::parse("td").unwrap();
let df_infos: Result<Vec<_>, _> = doc
.select(row_selector)
.map(|row| {
let cells = row.select(td_selector).collect_vec();
let dft = cells[0].text().collect_vec()[0].trim();
let cc = cells[1].text().collect_vec()[0]
.trim()
.parse::<u32>()
.unwrap();
let ncc = cells[2].text().collect_vec()[0]
.trim()
.parse::<u32>()
.unwrap();
let df_type = DfType::from_str(dft).unwrap();
let obj = DfTypeInfo {
df_type,
cannon_count: cc,
non_cannon_count: ncc,
description: String::new(),
};
info!("obj: {}", &obj);
Ok(obj)
})
.collect();
}
}Step 5: Combine it all with the main function
let’s rewrite our main function that supports asynchronous using tokio
#[tokio::main]
async fn main() {
env_logger::builder()
.filter_level(log::LevelFilter::Info)
.init();
let base_url = "https://onepiece.fandom.com";
let df_s = DfScraper::new(base_url, reqwest::Client::new());
df_s.get_dftype_info().await.unwrap();
}
We are now making a clean structure of Devil Fruit Scraper DfScraper where the base_url and the reqwest client are declared outside. Don’t forget to write your module (mod) visibility based on your file structure.
Finally, we can run our code by calling cargo run. The output will be something like:

Conclusion
With Rust’s speed, safety, and powerful libraries like reqwest, scraper, and tokio, you can efficiently scrap web pages like the One Piece Fandom for valuable data. Like in my case, building a data repository for One Piece, Rust offers the tools to do so robustly and quickly. Although it is not a mainstream way of doing web scraping, Rust proved a potential candidate to be used as one, with a bigger learning curve compared to Python.
My Repository for this One Piece Scraper is still private. I need to scrap more pages at least until all the devil fruit data can be pulled. I hope we can collaborate together on it once it is publicly ready :)

My Experience on Web Scraping One Piece Fandom Pages with Rust: Intro was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Muhammad Rifqi Fatchurrahman
Muhammad Rifqi Fatchurrahman | Sciencx (2024-10-21T23:22:49+00:00) My Experience on Web Scraping One Piece Fandom Pages with Rust: Intro. Retrieved from https://www.scien.cx/2024/10/21/my-experience-on-web-scraping-one-piece-fandom-pages-with-rust-intro/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.