
This content originally appeared on HackerNoon and was authored by Andrew Redican
\
Pretty but Slow/Ugly but Fast
\ In programming, just as in life, we are constantly making decisions about what problems we are willing to deal with. When architecting software, we accept trade-offs with each decision.
\ Some of those choices prioritize beauty and ease of use, while others focus purely on performance. This is especially true in a language like JavaScript, which was famously developed in 10 days. With every iteration of ECMAScript, we get more elegant and syntactically sweet features, but these improvements don’t always come without cost.
\ Programming languages evolve, and what we now consider clean, elegant, or succinct wasn’t always even on the minds of the original creators of JavaScript.
\ Brendan Eich could not have foreseen all the modern use cases or the optimizations necessary to meet today’s expectations of performance. This mismatch leads us to a critical understanding:
\ A language built with specific initial goals will always carry certain architectural and optimization biases that may not align with newer, shinier features.
\
Finding the Balance Between Elegance and Performance
\ JavaScript, at its core, was architected with certain performance considerations in mind, but these considerations often get overshadowed by newer features designed for ease of use rather than efficiency. The purpose of this exercise is to explore 19 examples of TypeScript/JavaScript code patterns, comparing common, elegant approaches to their more optimized, but perhaps less attractive, counterparts. These examples are cross-domain — not tied to specific frontend or backend environments — and are designed to help you make more informed decisions when writing code.
\
The Power of Informed Decisions
\ To move beyond assumptions and truly understand performance trade-offs, we must test our theories in practice. I’ve used a structured performance testing framework within GitHub Codespaces, running Node.js v22, to measure execution time and memory usage at varying scales. Testing patterns at 10, 100, 1,000, 10,000, and even 100,000 iterations helps reveal when certain optimizations kick in and how different environments can influence results.
\ As you dive into these examples, remember that performance isn’t just a matter of syntax. The underlying system, operating system version, and hardware configuration can all impact performance. The goal is to discover general principles by testing, not assuming. After all, in a language like JavaScript (insert any other language here), the prettiest code isn’t always the fastest.
\ Performance results are highly sensitive to context—such as the underlying operating system and the size of data flowing through the code. So, take the following results with a grain of salt; the benchmarks were run using a small performance testing framework I created last week.
To be 100% sure of your performance, you need to set aside general assumptions and conduct your own tests—you may be surprised!
\ If execution speed is a primary concern, optimize for that. However, in the real world, performance might not be your only consideration. It's important to find a solution that strikes the right balance. Therefore, always make a conscious assessment and understand first what should be optimized. For more on this topic, see To optimize or not to optimize.
\ As engineers, we may have a bias toward a "favorite language"—perhaps the first one we used or the one we employed to build an interesting project. In the end, if you truly care about performance, you might as well find the best tool (or programming language) for a particular job—which may not be JavaScript/TypeScript. The same goes for every other language.
\
1. String Concatenation (Using Template Literals vs + Operator)
Template literals can perform faster in many cases, especially with multiple variables, by reducing intermediate string allocations.
\
Performance tests showed template literals were executed faster, on average in 0.0007ms vs regular string concatenation 0.0011ms for 100 iterations and template literals remained faster when tested against 100k iterations, averaging 0.0002ms vs 0.0003ms.
\

\ \
2. Array Copying (Using slice() vs Spread Operator)
When comparing the spread operator to the slice() method, I found that (for smaller arrays at least), slice() outperformed the spread operator. The average execution of slice() was 0.0013ms which was shorter than spead operator, averaging 0.0018ms. However, when the performance test was scaled to 100k, iterations discovered that it performed roughly the same.
\

\ \
3. Looping Over Arrays (Using for vs forEach)
Traditional for loops are generally faster due to fewer function calls and memory overhead compared to forEach().
For 100 iterations, performance tests demonstrated for loops outperformed forEach() by executing 8% faster. This result was surprising, as I was personally expecting a much bigger gap. Then again, it could be down to the amount of data that was used for iteration, or it could be over time forEach() have been optimized.
\ For 100k iterations, it seemed like Node optimizations kicked in, and performance was about the same.
\

\ \
4. Object Property Access (Dot Notation vs Destructuring)
Destructuring can sometimes lead to more readable code, and inlining multiple property accesses may be faster in certain contexts.
\ The performance results observed for these tests showed counterintuitive results! I was expecting the dot notation to have the upper hand. However, in a simple performance test, where not much else is going on, except these two code snippets, we found that for 100 iterations, destructuring was 57% faster.
\ For 100k iterations however, I found execution speed, the difference was neglibible and virtually the same.
\

\
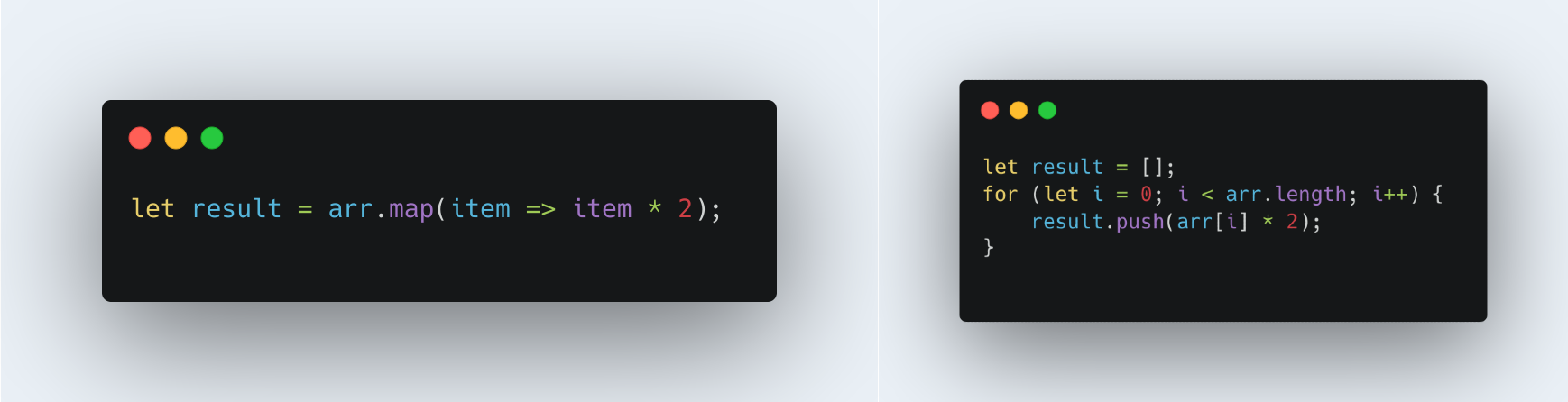
5. Using map() vs for Loop
for loops can outperform map() since there's less overhead in function calls, especially in performance-critical sections.
Surprisingly, using a small data array (~100 items of varying data types), found that it was virtually a draw! Regardless of whether it was 100 iterations or 100k iterations. The actual difference was too small be relevant, but if for loop beat map.
\
In relatively, if I had to declare a winner, it would be map() since the difference found was so negligible that I’d much better the clear more succinct code.
\
\
6. Object Cloning (Object.assign() vs Spread Operator)
Spread syntax can be faster and more concise when cloning objects compared to Object.assign().
\
For 100 iterations, the spread operator was 35% faster than using Object.assign(). This completely challenges and proves the exception to the rule. Apparently, the “pretty” syntax was faster!
\ For 100k iterations, similar to other tests, performance seemed to improve for both approaches, but the spread operator seemed to be the superior choice, being 40% faster.
\

\ \
7. Default Function Parameters (Using || vs Default Syntax)
Using default parameters is generally more optimized as it avoids unnecessary checks., you would think.
\
For 100 iterations, using || operator seemed 6% faster. For 100k iterations, however, the situation reverted, and default parameters were 33% faster!
\ I conclude there isn’t a clear winner for this one. Ultimately, the better performance test result is one run against the actual code you want to test. I would not take the results here and assume they will be the same for different codes, as things occurring in real production code may affect how Node executes code.
\

\
8. Array Search (indexOf vs includes)
includes() is faster and more readable for checking existence in arrays. By how much? includes() was 50% faster than indexOf() for 100 iterations test. Under the 100k iterations test, the difference in execution speed was negligible.
\

\
9. Object Lookup (hasOwnProperty vs in Operator)
The in operator is faster and simpler in many cases for object key lookups.
\
Both approaches clocked in about 0.0012ms for 100 iterations and 0.0002ms for 100k.
Whatever optimizations occur under the hood, make it 6 x faster.
It’s a draw! However, in such cases, I might prefer the succinctness that comes from the in operator.
\

\
10. Array Filtering (Using filter() vs. Loop and Condition)
for loops can often be faster for filtering large arrays as they avoid function calls and temporary arrays.
\
I discovered in 100 iterations the performance test, filter() happened to be about 11% faster than the loop and condition approach.
On 100k iterations, surprisingly, the situation was reversed; loop and condition outperformed filter() by completing executions 33% faster.
\ This is one of those inconclusive tests; I think you must test on your own to validate the results.
\

11. Using Math.pow() vs Exponentiation Operator
The exponentiation operator (**) is faster than Math.pow() for small calculations, or so I thought.
\
Math.pow() was approximately 11% faster that ** on average for 100 iterations.
For 100k iterations, however, ** was 33% faster.
\

\
12. Array Concatenation (concat() vs Spread Operator)
The Spread operator can be more performant in terms of memory usage and speed for array concatenation.
\
Tests showed concat() was 25% faster than the spread operator, with 100 iterations. With 100k, however, the difference seemed negligible.
\

\
13. Memoization for Expensive Function Calls
Memoization can improve performance for expensive, repeatable calculations by caching results.
I did not run a performance test for this one. I decided to include it for the sake of completeness.
\ With memoization, we make a conscious trade-off, holding onto more memory (increasing our memory usage) with the hopes of not re-running an expensive calculation in execution time. This strategy only makes sense when the the deficit in execution time is bad enough, and the occurrence of the same input value or values passing through have a likely chance to be received repeatedly, otherwise it might not be a good idea to make this trade-off.
\

\
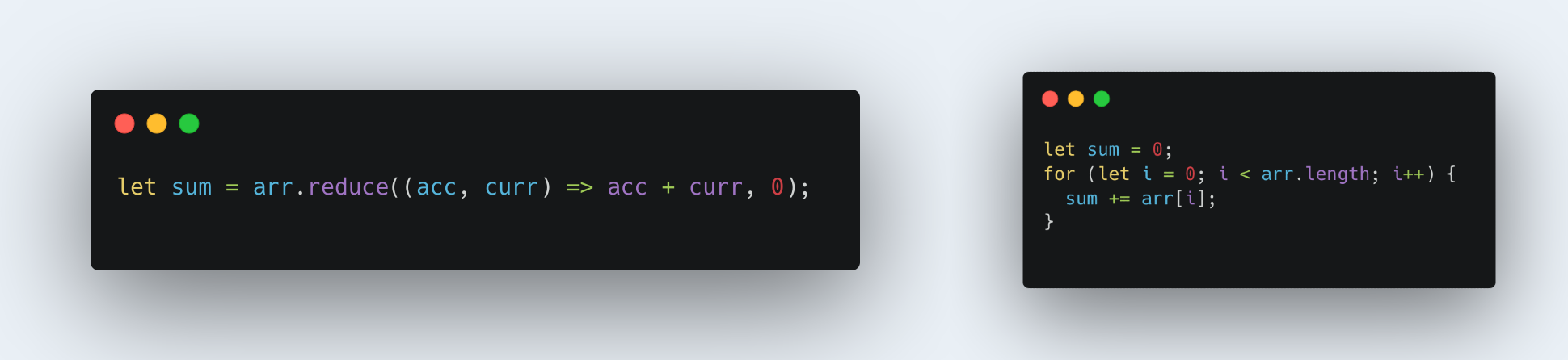
14. Looping with reduce() vs for
While reduce() is clean and readable, for loops can be faster for basic summing or accumulating values, is what I thought.
\ I am not giving out the answer to this one :smile:. Which one do you think will be faster?
\ You can create a new repo and select this project as a template https://github.com/AndrewRedican/structura and find the answer on your own!
\
\ \
15. Short-circuiting with && vs if Statements
Short-circuit evaluation can reduce the number of branching operations in simple conditions.
\ However, it seems like performance was roughly the same, regardless of the number of iterations in the test. Both were equally fast.
\ It is a draw.
\

\
16. Array Flattening (flat() vs Custom Loop)
Manual flattening can be faster for shallow arrays compared to flat(), which can handle deep nesting but with overhead.
The verbose custom loop was approximately 38% faster on average during 100 iteration tests and 44% faster during 100k iteration tests!
When it comes to performance, it seems like a custom loop wins by a landslide.
\
However, if you would have to compare how a custom loop performance flattens N depths, I suspected it might have diminishing returns in optimization when compared to using flat(). If this is your case, it might be worth putting it to the test.
\

\
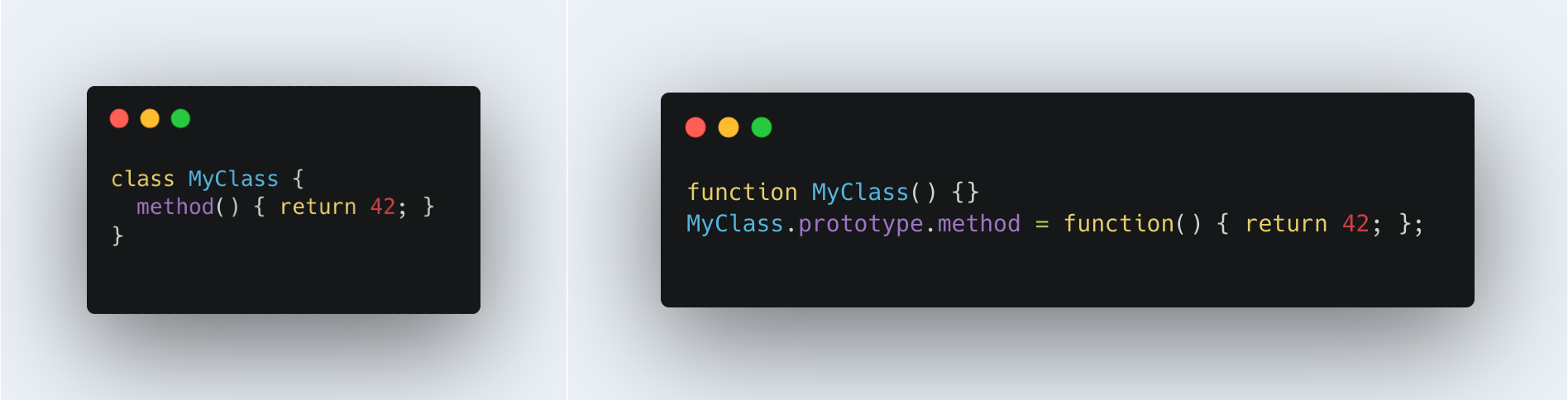
17. Class Methods vs Prototypes
Prototype methods are generally faster than class methods due to differences in how they are handled under the hood.
\
class keyword was introduced to JavaScript in ES6, which was a while ago. It turns out that declaring classes and methods class is less performant. Using prototypes yields fast execution times, being 20% faster than using class. For 100k iterations, while prototypes are still faster, the gap is much smaller and just about 8% faster.
\
\
18. Lazy Initialization
Lazy initialization can save memory and reduce unnecessary object allocations.
\ This is another example that does not necessarily need a performance test. The whole idea of delaying initialization by first checking if we have initialized is another example similar to memoization, where we trade memory usage for speed performance. Like before, this only makes sense when making the trade-off favorable, meaning holding the previously instanced object is not too big or initialization is actually slow.
\

\
19. Iterators (for vs. Custom Iterator)
Custom iterators can provide fine-grained control over iteration, potentially improving memory usage for very large datasets.
\ Using custom iterators was 12% faster on average for 100 iterations of performance tests. However, during the 100k iterations test, it turns out optimizations that occur at that scale favor simply for loops better, being 33% faster than the custom iterators.
\ The test was inconclusive. Therefore, I recommend running your own performance tests.
\

\ \ That’s a wrap!
\
Conclusion
What did we learn from these tests?
- There’s a striking pattern—operations tend to speed up significantly when repeated (~100k iterations).
- And your assumption? It's probably wrong! ~ Always test your code. I started out thinking all aesthetically pleasing code had to be slower, but to my surprise, with NodeJS +22 at least, there are cases where you get both pretty and fast. Yet, there are still plenty of examples where ugly/verbose is the better choice when execution speed is the primary concern.
\ If you leave parroting that X is faster than Y —well, don’t! You’ve missed the point.
\

\ Seriously, Test. Test. Test.
\ If you’re not running performance tests or measuring results, then you probably don’t care about performance as much as you think.
\ In the world of software development, we constantly balance between writing clean, syntactic-sugar-heavy code and maximizing performance. Modern JavaScript and TypeScript offer a wealth of features that enhance readability and ease of use, but sometimes those conveniences come at the cost of speed and memory efficiency. By understanding these trade-offs and testing our assumptions, we can make more informed decisions about when to prioritize cleaner code versus when raw execution speed takes precedence.
\ Ultimately, the choice between “pretty but slow” and “ugly but fast” isn’t always obvious. It’s up to us as developers to assess where we can afford a performance trade-off for readability, and when we need to focus on squeezing out every bit of speed. Hopefully, the examples shared here inspire you to experiment further and to think critically about how your code choices affect performance.
\
P. S.
If you happen to need to test the performance of algorithms in TypeScript or JavaScript, you can clone or use my project as a template to get yourself started https://github.com/AndrewRedican/structura.
\ If you enjoyed this article, I recommend reading the following. While I have no affiliation with this, I think it was incredibly insightful and closely related to the performance discussion:
https://www.computerenhance.com/p/clean-code-horrible-performance?embedable=true
\
This content originally appeared on HackerNoon and was authored by Andrew Redican
Andrew Redican | Sciencx (2024-10-21T17:47:21+00:00) Pretty Slow / Ugly Fast: How to Optimize your Code in 19 Different Ways. Retrieved from https://www.scien.cx/2024/10/21/pretty-slow-ugly-fast-how-to-optimize-your-code-in-19-different-ways/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.