
This content originally appeared on HackerNoon and was authored by Economic Hedging Technology
Table of Links
Introduction
REINFORCEMENT LEARNING
RL, which is given a thorough explanation by Sutton and Barto (2018), is summarized in this section. RL is a continuous feedback loop between an agent and its environment. At each time step, the RL agent, in a current state 𝑠, takes an action 𝑎, and receives a reward 𝑟. The objective is to maximize future expected rewards, 𝐺𝑡 , which, at time step 𝑡 for an episodic task of 𝑇 discrete steps, are computed as
\
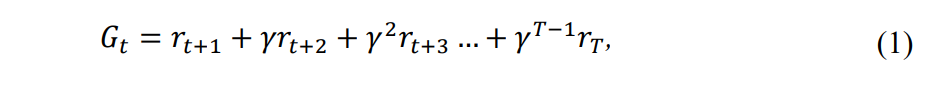
\ noting that 𝛾 is the discount factor to avoid infinite returns. For any state 𝑠, the corresponding action is given by the agent’s policy, 𝜋(𝑠) → 𝑎. Policies are evaluated by computing value functions such as the 𝑄-function, which maps state-action pairs to their expected returns under the current policy, i.e.,
\
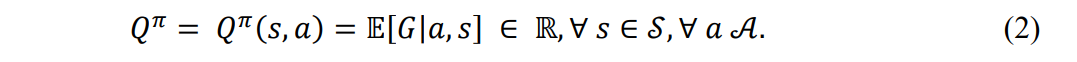
\

\ SARSA and 𝑄-learning are tabular methods, which require storing the 𝑄-value for each stateaction pair and policy for each state in a lookup table. As a tabular 𝑄-function requires the storage of 𝒮 × 𝒜 values, high-dimensional problems become intractable. However, the 𝑄-function may be approximated with function approximators such as NNs, recalling that this combination of NNs and RL is called DRL. DRL was popularized by the work of Mnih et al. (2013), who approximate the 𝑄-function with a NN, specifically denoting each 𝑄-value by 𝑄(𝑠, 𝑎; 𝜃), where 𝜃 is a vector of the NN parameters that signifies the weights and biases connecting the nodes within the neural network. Mnih et al. (2013) show that this method of deep Q-networks (DQN) can be used to train an agent to master multiple Atari games.
\ The Q-network parameters stored in 𝜃 are optimized by minimizing a loss function between the Q-network output and the target value. The loss function for iteration 𝑖 is given by
\
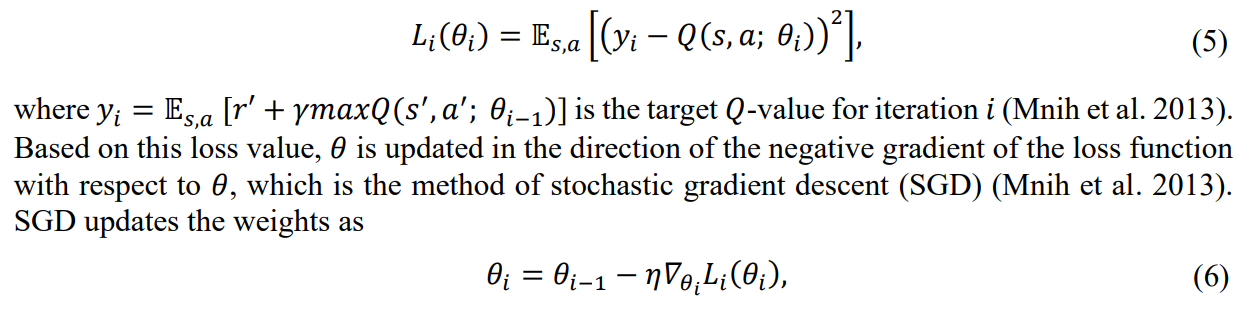
\ where 𝜂 is the learning rate for the neural network, and 𝛻𝜃𝑖 𝐿𝑖(𝜃𝑖) is the gradient of the loss with respect to the network weights. In addition to 𝑄-network approximation, another component of DQN is the use of the experience replay buffer (Mnih et al. 2013). Experience replay, originally proposed for RL by Lin (1992), stores encountered transitions (state, action, and reward) in a memory buffer. Mnih et al. (2013) use the replay buffer to uniformly sample the target 𝑄-value for iteration 𝑖 (𝑦𝑖 ).
\ To update the Q-function in value methods such as DQN, a max operation on the 𝑄-value over all next possible actions is required. Further, as discussed above, improving the policy in value methods requires an argmax operation over the entire action-space. When the action-space is continuous, the valuation of each potential next action becomes intractable. In financial option hedging, discretizing the action-space restricts the available hedging decisions. While hedging does require the acquisition of an integer number of shares, a continuous action-space for the optimal hedge provides more accuracy, as the hedge is not limited to a discrete set of choices. As such, continuous action-spaces are much more prevalent in the DRL hedging literature (Pickard and Lawryshyn 2023)
\

\
:::info Authors:
(1) Reilly Pickard, Department of Mechanical and Industrial Engineering, University of Toronto, Toronto, ON M5S 3G8, Canada (reilly.pickard@mail.utoronto.ca);
(2) Finn Wredenhagen, Ernst & Young LLP, Toronto, ON, M5H 0B3, Canada;
(3) Julio DeJesus, Ernst & Young LLP, Toronto, ON, M5H 0B3, Canada;
(4) Mario Schlener, Ernst & Young LLP, Toronto, ON, M5H 0B3, Canada;
(5) Yuri Lawryshyn, Department of Chemical Engineering and Applied Chemistry, University of Toronto, Toronto, ON M5S 3E5, Canada.
:::
:::info This paper is available on arxiv under CC BY-NC-SA 4.0 Deed (Attribution-Noncommercial-Sharelike 4.0 International) license.
:::
\
This content originally appeared on HackerNoon and was authored by Economic Hedging Technology
Economic Hedging Technology | Sciencx (2024-10-29T22:45:26+00:00) How Reinforcement Learning Enhances American Put Option Hedging Strategies. Retrieved from https://www.scien.cx/2024/10/29/how-reinforcement-learning-enhances-american-put-option-hedging-strategies/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.